تولید فیلمهای پرتره خلاقانه با بالاترین کالیبر یک کار بسیار مهم و مطلوب در بینایی و گرافیک کامپیوتری است.
اگرچه چندین مدل موثر برای تونیفیکیشن تصویر پرتره بر اساس StyleGAN قدرتمند پیشنهاد شده است، این تکنیکهای تصویرگرا هنگام استفاده با فیلمها دارای اشکالات واضحی هستند، مانند اندازه ثابت قاب، نیاز به تراز چهره، عدم وجود جزئیات غیر چهره. ، و ناسازگاری زمانی.
یک چارچوب انقلابی VToonify برای مقابله با انتقال سبک ویدئویی پرتره با وضوح بالا و کنترل شده دشوار استفاده می شود.
ما در این مقاله جدیدترین مطالعه در مورد VToonify را از جمله عملکرد، معایب و عوامل دیگر بررسی خواهیم کرد.
Vtoonify چیست؟
چارچوب VToonify امکان انتقال تصویر پرتره با وضوح بالا را به سبک قابل تنظیم می دهد.
VToonify از لایههای با وضوح متوسط و بالا StyleGAN برای ایجاد پرترههای هنری با کیفیت بالا بر اساس ویژگیهای محتوای چند مقیاسی بازیابی شده توسط یک رمزگذار برای حفظ جزئیات فریم استفاده میکند.
معماری کاملاً کانولوشنال حاصل، چهرههای غیرهمتراز را در فیلمهای با اندازه متغیر به عنوان ورودی دریافت میکند، که در نتیجه مناطق کل چهره با حرکات واقعی در خروجی ایجاد میشود.

این چارچوب با مدلهای تونیسازی تصویر مبتنی بر StyleGAN سازگار است و به آنها اجازه میدهد تا به تونیفیکیشن ویدیو نیز بسط داده شوند و ویژگیهای جذابی مانند سفارشیسازی رنگ و شدت قابل تنظیم را به ارث ببرند.
این مطالعه دو نمونه از VToonify بر اساس Toonify و DualStyleGAN به ترتیب برای انتقال سبک ویدیوی پرتره مبتنی بر مجموعه و مبتنی بر نمونه معرفی می کند.
یافتههای تجربی گسترده نشان میدهد که چارچوب پیشنهادی VToonify از رویکردهای موجود در ساخت فیلمهای پرتره هنری با کیفیت بالا و زمانی منسجم با پارامترهای سبک متغیر بهتر عمل میکند.
محققان ارائه می کنند نوت بوک گوگل کولب، بنابراین می توانید دست خود را روی آن کثیف کنید.
چگونه کار می کند؟
برای انجام انتقال سبک ویدیوی پرتره با وضوح بالا قابل تنظیم، VToonify مزایای چارچوب ترجمه تصویر را با چارچوب مبتنی بر StyleGAN ترکیب می کند.
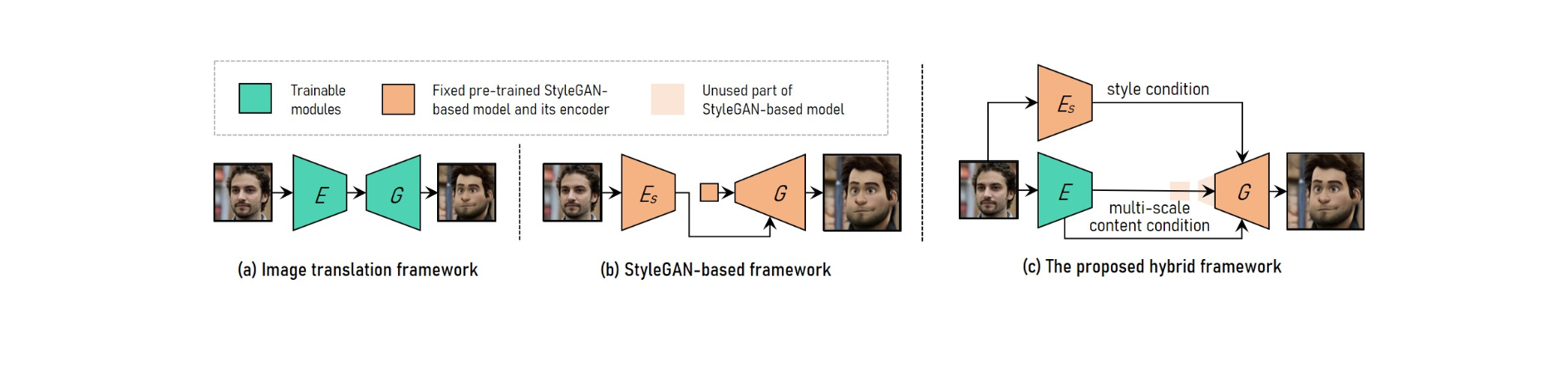
برای تطبیق اندازه های ورودی مختلف، سیستم ترجمه تصویر از شبکه های کاملاً کانولوشنال استفاده می کند. از سوی دیگر، آموزش از ابتدا، انتقال با وضوح بالا و سبک کنترل شده را غیرممکن می کند.
مدل StyleGAN از پیش آموزشدیده در چارچوب مبتنی بر StyleGAN برای انتقال سبک با وضوح بالا و کنترلشده استفاده میشود، اگرچه محدود به اندازه تصویر ثابت و کاهش جزئیات است.
StyleGAN در چارچوب ترکیبی با حذف ویژگی ورودی با اندازه ثابت و لایههای با وضوح پایین، اصلاح شده است، که منجر به یک معماری رمزگذار-مولد کاملاً پیچیده شبیه به چارچوب ترجمه تصویر میشود.
برای حفظ جزئیات قاب، یک رمزگذار را آموزش دهید تا ویژگی های محتوای چند مقیاسی قاب ورودی را به عنوان یک نیاز محتوای اضافی برای مولد استخراج کند. Vtoonify انعطاف پذیری کنترل سبک مدل StyleGAN را با قرار دادن آن در ژنراتور به ارث می برد تا هم داده ها و هم مدل آن را تقطیر کند.
محدودیت های StyleGAN و Vtoonify پیشنهادی
پرتره های هنری در زندگی روزمره ما و همچنین در مشاغل خلاقانه مانند هنر رایج است. رسانه های اجتماعی آواتارها، فیلم ها، تبلیغات سرگرمی و غیره.
با توسعه یادگیری عمیق با فناوری، اکنون می توان با استفاده از انتقال خودکار سبک پرتره، پرتره های هنری با کیفیت بالا از عکس های چهره واقعی ایجاد کرد.
راههای موفق مختلفی برای انتقال سبک مبتنی بر تصویر ایجاد شدهاند، که بسیاری از آنها بهراحتی برای کاربران مبتدی در قالب برنامههای کاربردی موبایل قابل دسترسی هستند. مطالب ویدیویی به سرعت در طی چندین سال گذشته به یکی از پایههای اصلی فیدهای رسانههای اجتماعی ما تبدیل شده است.
ظهور رسانههای اجتماعی و فیلمهای زودگذر، تقاضا برای ویرایش ویدیویی خلاقانه، مانند انتقال سبک ویدیوی پرتره، برای تولید ویدیوهای موفق و جالب را افزایش داده است.
تکنیکهای تصویر محور موجود هنگام استفاده از فیلمها دارای معایب قابلتوجهی هستند و کاربرد آنها را در سبکسازی خودکار ویدیوی پرتره محدود میکنند.
StyleGAN به دلیل ظرفیت آن برای ایجاد چهره های با کیفیت بالا با مدیریت سبک قابل تنظیم، یک ستون فقرات رایج برای توسعه یک مدل انتقال سبک تصویر پرتره است.
یک سیستم مبتنی بر StyleGAN (همچنین به عنوان تونی سازی تصویر نیز شناخته می شود) یک چهره واقعی را در فضای پنهان StyleGAN رمزگذاری می کند و سپس کد سبک حاصل را به StyleGAN دیگری که به خوبی روی مجموعه داده پرتره هنری تنظیم شده است، اعمال می کند تا یک نسخه تلطیف شده ایجاد کند.
StyleGAN تصاویری را با چهرههای همتراز و در اندازه ثابت ایجاد میکند، که به نفع چهرههای پویا در فیلمهای دنیای واقعی نیست. برش و تراز کردن چهره در ویدیو گاهی منجر به چهره جزئی و حرکات ناخوشایند می شود. محققان این موضوع را "محدودیت محصول ثابت" StyleGAN می نامند.
برای چهره های بدون تراز، StyleGAN3 پیشنهاد شده است. با این حال، فقط از یک اندازه تصویر تنظیم شده پشتیبانی می کند.
علاوه بر این، یک مطالعه اخیر کشف کرده است که رمزگذاری چهره های غیر هم تراز چالش برانگیزتر از چهره های تراز است. رمزگذاری نادرست چهره برای انتقال سبک پرتره مضر است، و در نتیجه مسائلی مانند تغییر هویت و از دست رفتن اجزا در فریم های بازسازی شده و مدل داده شده ایجاد می شود.
همانطور که بحث شد، یک تکنیک کارآمد برای انتقال سبک ویدیوی پرتره باید مسائل زیر را حل کند:
- برای حفظ حرکات واقع گرایانه، این رویکرد باید بتواند با چهره های غیرهمتراز و اندازه های مختلف ویدیو مقابله کند. اندازه ویدیوی بزرگ یا زاویه دید وسیع، میتواند اطلاعات بیشتری را ثبت کند و در عین حال چهره از قاب خارج نشود.
- برای رقابت با ابزارهای معمولی HD امروزی، ویدئو با وضوح بالا ضروری است.
- کنترل سبک انعطاف پذیر باید برای کاربران ارائه شود تا در هنگام توسعه یک سیستم تعامل واقعی با کاربر، انتخاب خود را تغییر داده و انتخاب کنند.
برای این منظور، محققان VToonify را پیشنهاد می کنند، یک چارچوب ترکیبی جدید برای تونی سازی ویدئو. برای غلبه بر محدودیت محصول ثابت، محققان ابتدا معادل سازی ترجمه را در StyleGAN مطالعه می کنند.
VToonify مزایای معماری مبتنی بر StyleGAN و چارچوب ترجمه تصویر را برای دستیابی به انتقال سبک ویدیوی پرتره با وضوح بالا با قابلیت تنظیم ترکیب می کند.
مشارکت های زیر به شرح زیر است:
- محققان محدودیت محصول ثابت StyleGAN را بررسی میکنند و راهحلی بر اساس معادله ترجمه پیشنهاد میکنند.
- محققان یک چارچوب کاملاً کانولوشنال VToonify را برای انتقال سبک ویدیوی پرتره با وضوح بالا ارائه میکنند که از چهرههای بدون تراز و اندازههای مختلف ویدیو پشتیبانی میکند.
- محققان VToonify را بر روی ستون فقرات Toonify و DualStyleGAN میسازند و ستون فقرات را از نظر دادهها و مدل متراکم میکنند تا امکان انتقال سبک ویدیوی پرتره مبتنی بر مجموعه و نمونه را فراهم کنند.
مقایسه Vtoonify با سایر مدل های پیشرفته
Toonify کردن
این به عنوان پایه ای برای انتقال سبک مبتنی بر مجموعه بر روی چهره های تراز با استفاده از StyleGAN عمل می کند. برای بازیابی کدهای سبک، محققان باید چهره ها را تراز کرده و 256256 عکس را برای PSP برش دهند. Toonify برای ایجاد یک نتیجه سبک با کدهای سبک 1024*1024 استفاده می شود.
در نهایت، آنها نتیجه موجود در ویدیو را مجدداً با مکان اصلی خود تراز می کنند. ناحیه سبک نشده روی سیاه تنظیم شده است.

DualStyleGAN
این یک ستون فقرات برای انتقال سبک مبتنی بر نمونه مبتنی بر StyleGAN است. آنها از همان تکنیک های پیش و پس پردازش داده ها مانند Toonify استفاده می کنند.
Pix2pixHD
این یک مدل ترجمه تصویر به تصویر است که معمولاً برای فشرده سازی مدل های از پیش آموزش دیده برای ویرایش با وضوح بالا استفاده می شود. با استفاده از داده های جفت شده آموزش داده می شود.
محققان از pix2pixHD به عنوان ورودی های نقشه نمونه اضافی آن استفاده می کنند زیرا از نقشه تجزیه استخراج شده استفاده می کند.
حرکت مرتبه اول
FOM یک مدل متحرک تصویر معمولی است. این بر روی 256256 تصویر آموزش داده شده است و با اندازه های دیگر تصویر ضعیف عمل می کند. در نتیجه، محققان ابتدا فریم های ویدئویی را به 256*256 برای FOM به انیمیشن مقیاس می دهند و سپس اندازه نتایج را به اندازه اصلی خود تغییر می دهند.
برای مقایسه منصفانه، FOM از اولین فریم تلطیف شده رویکرد خود به عنوان تصویر سبک مرجع خود استفاده می کند.
داگان
این یک مدل انیمیشن صورت سه بعدی است. آنها از همان روش های آماده سازی و پس پردازش داده ها مانند FOM استفاده می کنند.

مزایای
- می توان از آن در هنرها، آواتارهای رسانه های اجتماعی، فیلم ها، تبلیغات سرگرمی و غیره استفاده کرد.
- Vtoonify همچنین می تواند در متاورس استفاده شود.
محدودیت ها
- این روش هم داده ها و هم مدل را از ستون فقرات مبتنی بر StyleGAN استخراج می کند که منجر به سوگیری داده ها و مدل می شود.
- این مصنوعات عمدتاً به دلیل تفاوت اندازه بین ناحیه صورت استایل شده و سایر بخش ها ایجاد می شوند.
- این استراتژی در هنگام برخورد با چیزهایی در ناحیه چهره کمتر موفق است.
نتیجه
در نهایت، VToonify چارچوبی برای تونیفیکیشن ویدیویی با وضوح بالا با کنترل سبک است.
این فریم ورک عملکرد فوقالعادهای در مدیریت ویدیوها به دست میآورد و با متراکم کردن مدلهای تونیکسازی تصویر مبتنی بر StyleGAN، کنترل گستردهای را بر سبک ساختاری، سبک رنگ و درجه سبک امکانپذیر میسازد. داده های مصنوعی و ساختارهای شبکه





پاسخ دهید