Web scraping metodo erabakigarria bihurtu da Interneteko plataformetatik datu argiak lortzeko gaur egungo datuetan oinarritutako gizartean.
Sare sozialen gune oso ezaguna denez, Instagramek erabiltzaileek sortutako material asko eskaintzen du. Eta, sortutako datu hauek marketin, ikerketa eta bestelako arrazoietarako erabil daitezke.
Erabiltzaileek Instagrametik datuak erraz eta eraginkortasunez atera ditzakete Bright Data-ren ezaugarri aberatsak diren Instagram scraper-ei esker. web scraping tresna. Argitalpen honetan, Instagramen scraping prozesuaren urratsez urratseko jarraibide sakona emango dugu.
Beraz, ikus ditzagun Instagram-eko datuak nola atera ditzakegun urratsak.
Bright Datuetatik Instagram Scrapers ulertzea
Erabilera guztietarako bi web scraper eta aurrez konpilatutako datu-multzo baten laguntzaz, Bright Datak Instagram scraping zerbitzu ugari eskaintzen ditu. Teknologia hauek aldakortasuna eskaintzen dute datuak erauzteko eta hainbat eskakizunetara egokitzen.
Azter ditzagun aukera hauetako bakoitza zehatzago:
a. Scraping arakatzailea
Scraping Browser izenez ezagutzen den teknologia berritzailea datuak scraping proiektuen eskakizunak betetzeko sortu zen. Arakatzaile bakar baten barruan eskalan scraping behar den guztia eskaintzen du. Webguneen desblokeo automatizazioari esker nabarmentzen da, mundu osoan mota horretako arakatzaile bakarra bihurtzen duena.
Scraping Browser-ek erabiltzaileei nabigatzaile automatizatu eta bururik gabeko arakatzaileetatik haratago doazen funtzio sendoetarako sarbidea ematen die, bot detektatzeko script eta webguneko oztoporik zailenak ere gainditzeko aukera emanez.
Datu-scraping eraginkorragoa eta arazorik gabekoa da doikuntza automatikoko eginbideengatik, bloke berriak, CAPTCHA irtenbideak, hatz-markak eta berriro saiakera erraz kudeatzen dituztenak, eta benetako erabiltzaile gisa agertzen baita.
AI erabiltzea bot-a detektatzeko sistemak asmatzeko
Puntako AI teknologia erabiliz, Scraping Browser-ek bot-a detektatzeko sistemak gaindi ditzake eta etengabe alda ditzaketen estrategietara egokitu. Web-orriak hobeto desblokeatzeko, Scraping Browser-ek sistema hauen scraping saiakerak detektatzeko eta blokeatzeko saiakeretatik ikasten du eta bere portaera egoki aldatzen du.
Ohiko proxyen eraginkortasuna gainditzen du, benetako erabiltzaile batek erabiltzen duen arakatzaile baten portaera imitatuz. Ondorioz, bezeroak datuen scraping-en helburuetan kontzentratu daitezke bot-a detektatzeko etengabeko prozeduren zailtasunei eta gastuei aurre egin beharrik gabe.
b. Web Scraper IDE
Garatzaileentzat sortutako web scraping tresna sendoa, Web Scraper IDE scraping zeregin konplexuak kudeatu ditzake. Garapen-denbora nabarmen murrizten du, eskalagarritasun infinitua eskaintzen duen bitartean erabat ostatatutako irtenbideari eta aurrez eraikitako scraping eginbideei esker. Aplikazioak lineako scrapers azkar eta eskalagarriak eraikitzea ahalbidetzen du, webgune ezagunetatik kode txantiloiak eta prest egindako JavaScript funtzioak eskainiz.
Web scraping arrakastatsua izateko beharrezkoa den guztia Web Scraper IDE-k eskaintzen du. Lineako datuak ateratzeko irtenbide osoa da, integrazio aukerek bezeroei arakatzeak planifikatzeko edo API bidez abiarazteko eta biltegiratze sistema nagusiekin lotzeko aukera ematen baitute.
Nola Erabili? – Tutoretza
Lehenik eta behin, joan webguneko erabiltzailearen panelera.

Has gaitezen gure urratsekin Instagram scraping.
1- Nabigatu arbela eta egin klik Datasets & Web Scraper IDE atalean.
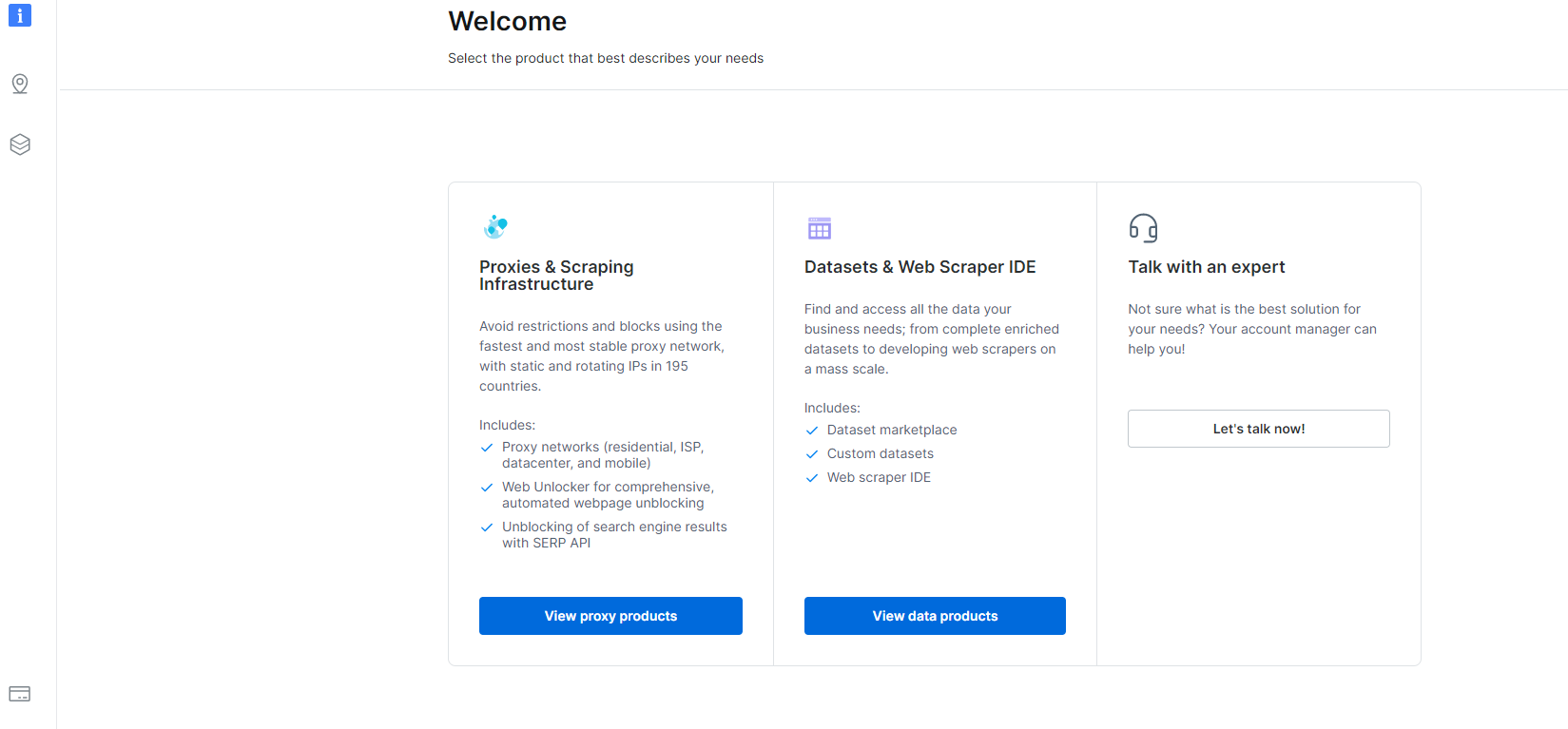
2- Behin, han zaudela, egin klik My Scrapers-en.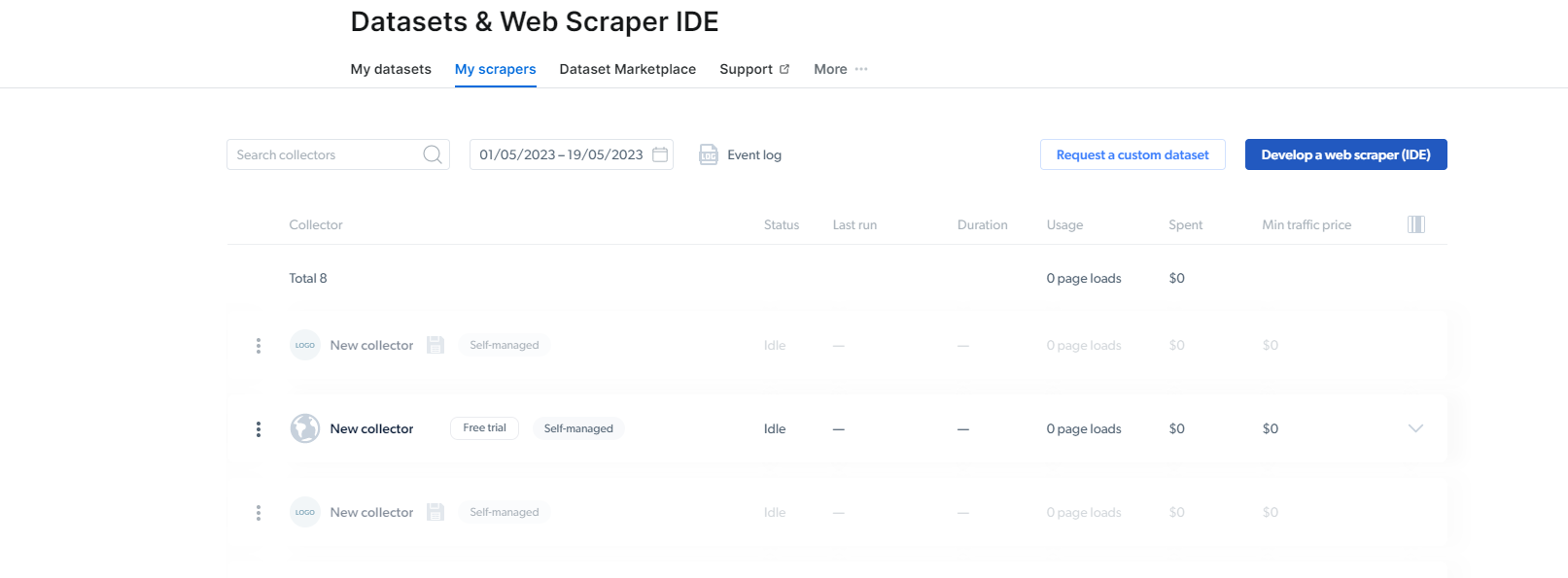
Hemen, "Gara ezazu web scraper (IDE)" aukeran. Hemen Instagram-erako gure scraper sortuko dugu.
3-Orain, web scraper berri bat garatu behar dugu. Adibide honetarako bakarrik, "NASA" kontua ezabatzea aukeratzen dut. Hau adibide honen mesedetan besterik ez da.
Beraz, nire kodea honela izango da:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Kode hau exekutatzeko, goiko eskuineko 'erreproduzitu' botoia sakatu behar duzu.
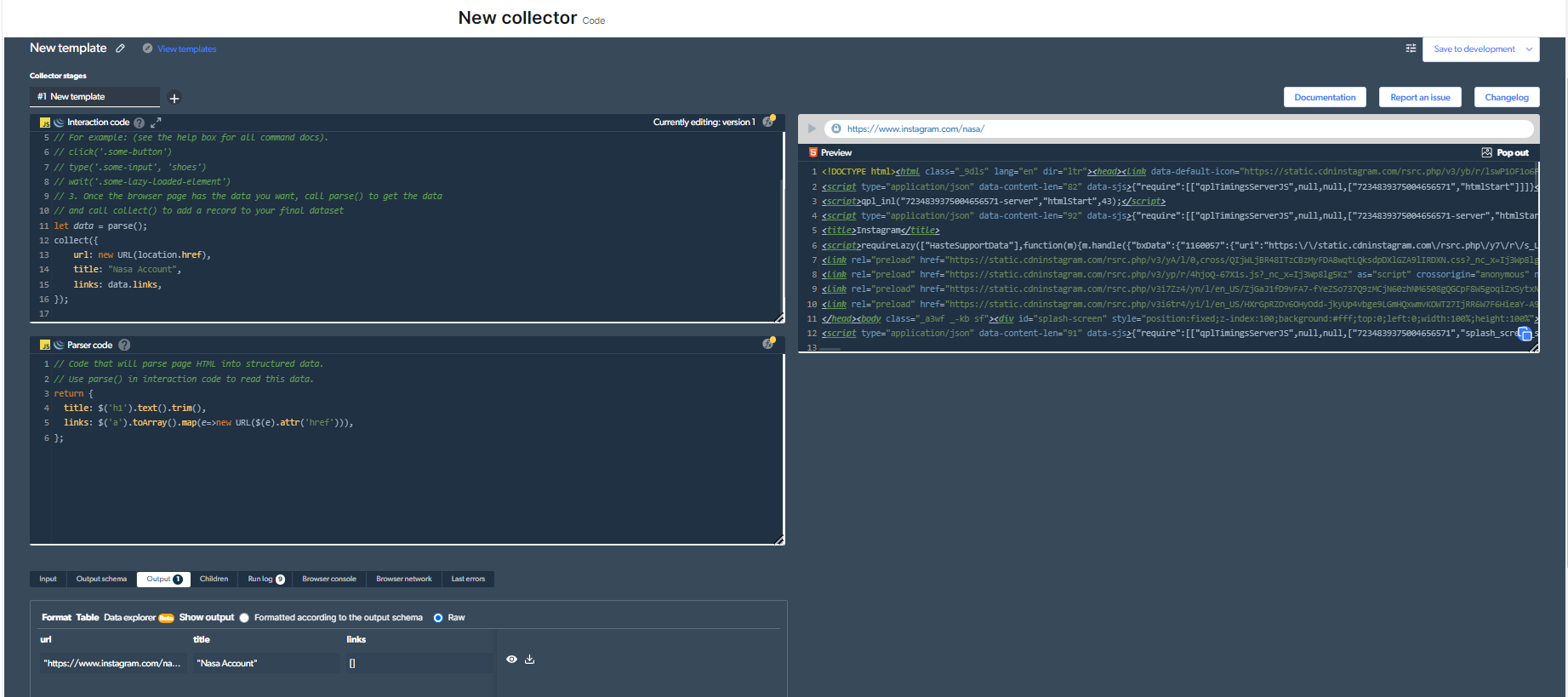
4- Orain, irteera bat izango dugu.
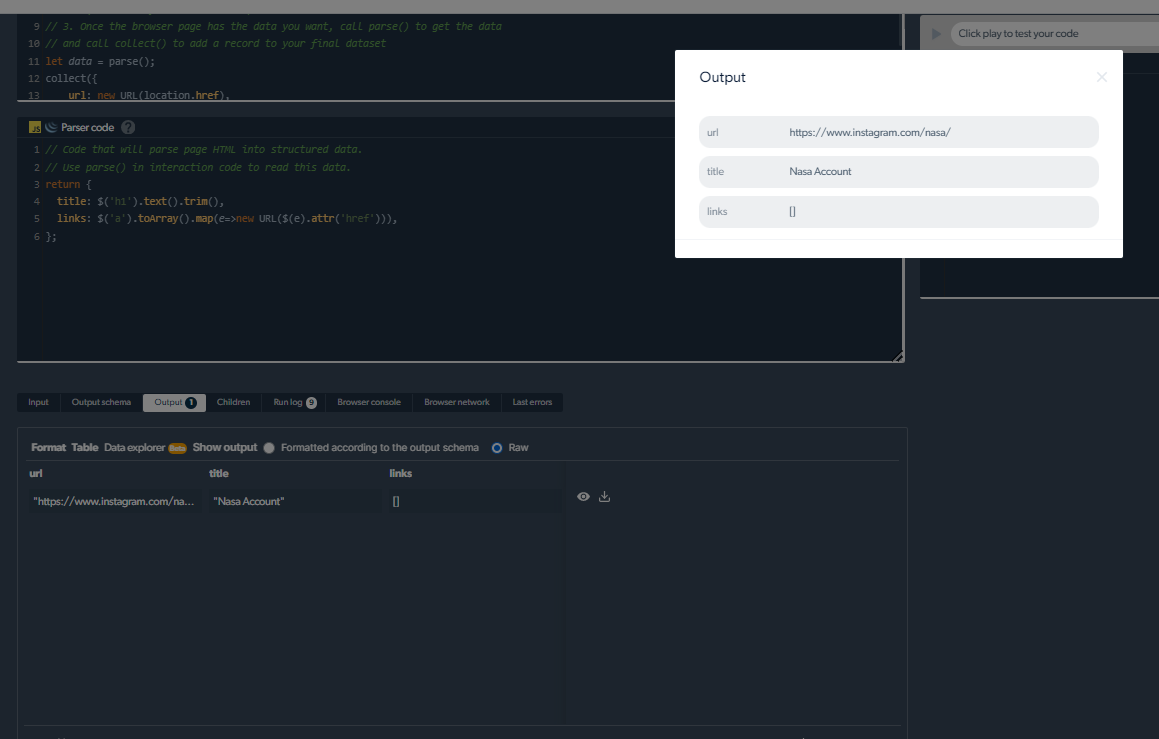
Scraping arazoak kudeatzea
"Erakutsi gehiago botoia" duten Instagram-eko argitalpenak zailak izan daitezke scraperek harrapatzea. Hala eta guztiz ere, Bright Data-ren Instagram scrapers konplexutasun hori behar bezala kudeatzeko eginak daude. Scraper hauek punta-puntako trebetasunak dituzte botoi gehigarrien orria eta kargak zeharkatzeko.
Bright Data-ren Instagram scraper-ek modu eraginkorrean kudeatzen dituzte zailtasun hauek, datuen erauzketa sakona ahalbidetzeko, zure azterketa edo azterketarako beharrezkoa den informazio-bilduma osoa biltzeko aukera emanez.
Instagram-eko mezuen izaera dinamikoak aurkezten dituen erronkei aurre egin diezaiekezu scraping tresna hauek erabiliz.
c. Aurrez bildutako datu multzoa
Bright Datak ulertzen du denek ez dutela beren arraspa exekutatu nahi. Aurretik bildutako datu-multzo bat hornitzen dute Instagramentzat kontsumitzaile horiek erakartzeko.
Datu-multzo honek informazio baliagarri ugari eskaintzen du, hala nola jarraitzaileak, profilak, argitalpenak eta abar.
Bright Data-k pertsonalizazio aukerak eskaintzen ditu datu-multzoa zure beharretara pertsonalizatzeko, datu-multzo oso bat edo datu espezializatuen azpimultzo bat nahi baduzu. Ikuspegi honek scraper bat eraikitzea eta kudeatzea saihesten du, analisi eta ikuspegietarako erabiltzeko prest dauden datuak emanez.
Orain, egiaztatu dezagun tresna hauek hain eraginkorrak egiten dituen azpiegitura: proxy azpiegitura eta Web Unlocker.
Askatu proxyen boterea
erabiliz ak funtsezkoa da web scraping zehar zure ekintzak oharkabean pasako direla bermatzeko.
Bright Data aukera zabala eskaintzen du proxy zerbitzuak zure beharretara egokitutakoak. Bertatik aukeratu dezakezu Bizileku Proxyak, 72 naziotan benetako pareko gailuetatik biratuta dauden 195 milioi IP baino gehiago eskaintzen dituztenak.
ISP Proxiak aukera ditzakezu, mundu osoan 700,000+ benetako etxeko IP eskaintzen dituztenak epe luzerako erabiltzeko; Datacenter Proxiak, edozein geokokapenetatik 770,000+ IP partekatu dituztenak; eta Mobile Proxies, 3+ IP dituen benetako pareko 4G/7,000,000G sare mugikor handiena osatzen dutenak.
Proxy hauen erabilerarekin, erraz bil daitezke datuak leku askotan baimendutako erabiltzaile gisa agertzen den bitartean.

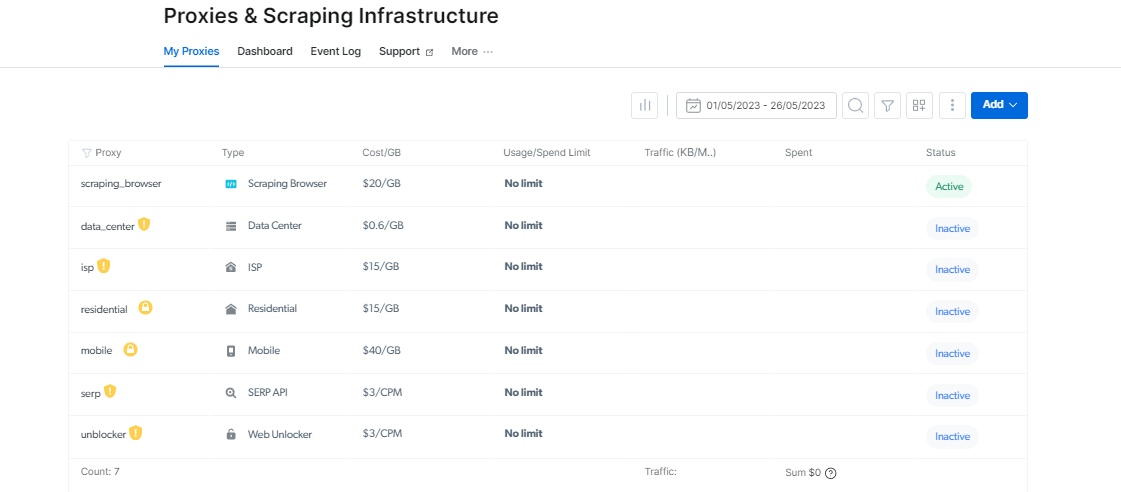
Proxy kudeatzailea: Proxy kudeaketa erraztu
Baliteke hainbat proxy kudeatzea zaila izan daiteke, baina Proxy Manager erraza da.
Kode irekiko interfaze honek zure proxy guztiak plataforma bakar batetik kudeatzeko aukera ematen dizu. Esan agur proxyak eskuz ezartzeari eta aldatzeari. Proxy-kudeatzaileak prozedura errazten du eta denbora eta ahalegina aurrezten dizu.
Proxy arakatzailearen luzapena: aldatu zure kokapena erraz
Hainbat eskualdetako web-datuak bildu behar dituzu? Gure proxy arakatzailearen luzapenarekin estalita zaude. Zure arakatze-kokapena alda dezakezu klik bakar batekin eskualdeko informazioa lortzeko.
Aprobetxatu hainbat eskualdetako datuak biltzearen malgutasuna eta sinpletasuna konplikazio teknologikorik gabe.
Nola dabil? – Tutoretza
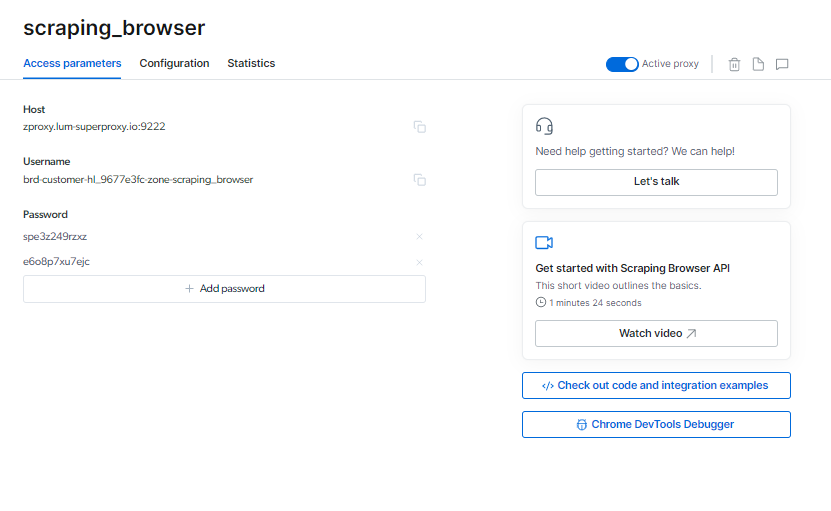
Zure lokalizatu dezakezu Scraping arakatzailea Sarbide-parametroen orrian saioa hasteko informazioa, arakatzaile-saio berri bat hasten duzunean erabiliko dena.
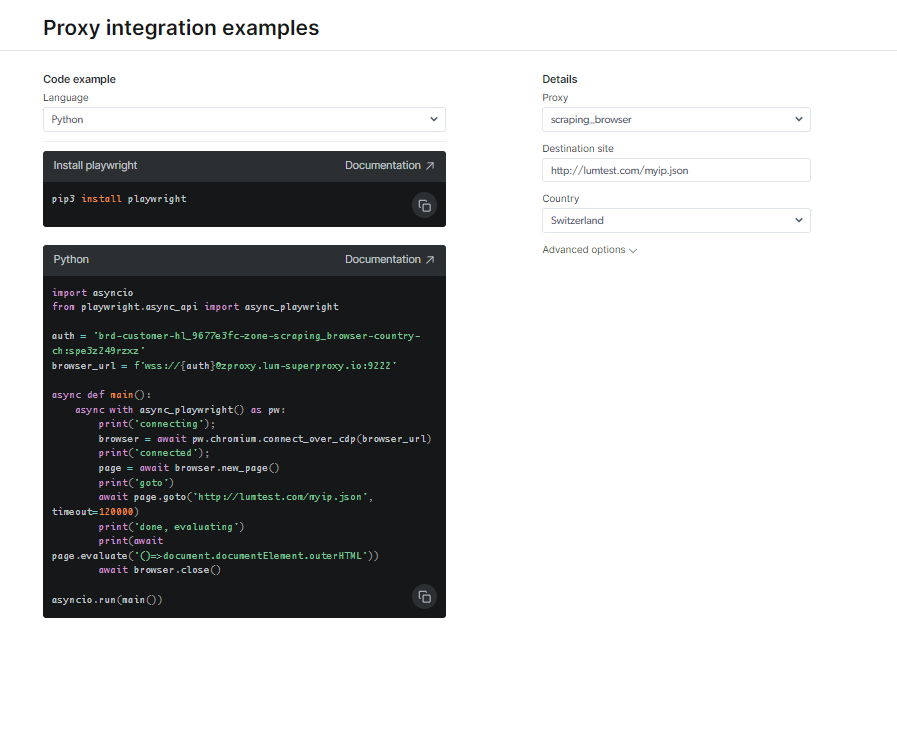
Begiratu dokumentazioa eta kode-laginak, erabiltzeko prest dagoen adibide-script guztiz funtzionala barne, edo ikusi hasierako argibide-bideo labur bat. Adibidez; hona hemen bat Python kodea integraziorako adibidea:
Laguntza nahi duzu? Espezialistetako batekin elkarrizketa bat izateko, txataren ikonoa sakatu dezakezu.
Gogoan izan arakatzailearen saioen kontrol osoa duzula Scraping Browser erabiltzen duzun bitartean eta Puppeteer, Playwright edo Chrome DevTools Protokoloaren erabilera zuzena onartzen duen edozein eragiketa egin dezakezula.
Webgunea blokeatu gabe desblokeatzea
Scraping Browser eskalan eta behar bezala funtzionatzeko egina dago. Ez duzu debekatua izateaz kezkatu behar; behar adina arakatzaile saio abiarazi ditzakezu.
Ahalmen horrek, proxyen indarrarekin konbinatuta, etengabeko datuak biltzea bermatzen du, nahi dituzun datuak modu eraginkorrean lortu ahal izateko.
Scraping Browser-en desblokeatzeko trebetasun integratuak eta proxy sare sendoak denbora aurrezten, produktibitatea hobetzen eta aukera berriak aurkitzen laguntzen dizu.
Orrialde bereko estatistikak zuzenean ikus ditzakezu.
Scraping arakatzailearen prezioa
Bright Data-k prezioen aukera pertsonalizagarriak eskaintzen ditu hainbat helburu betetzeko. Hilero edo urteko fakturazio-epea aukeratu dezakezu.
Ordaindu ahala aukerak erabiltzen duzunagatik bakarrik ordaintzeko aukera ematen du, konpromisorik gabe, 20.00 $/GB eta 0.1 $/ordukotik hasita.
$ 500 Growth plana egokia da hazten ari diren negozioetarako, 15.30 $ / GB eta 0.1 $ / orduko deskontu tasarekin.
The Negozio paketea, $ 1000 balio duena, aukerarik ezagunena da, Scraping Browser APIa $ 13.50 / GB eta $ 0.1 / orduko kostuarekin.
Bright Data taldearekin zuzenean harremanetan jarrita, enpresetako erabiltzaileek eskala infinitu eta prezio pertsonalizatuak goza ditzakete. Hasi doako proba bat gaur Bright Data-ren Scraping Arakatzailearen potentziala ezagutzeko eta zure lineako scraping ahaleginak aldatzeko.
Webguneen desblokeatzailea
Web Unlocker webguneen murrizketak gainditzeko eta datuak biltzeko errazak emateko sortutako tresna indartsua da. Hainbat erronka gainditzen ditu, besteak beste, cookieak, guneko arakatzaileen erabiltzaile-agente espezifikoak eta captcha irtenbideak, prozedura automatizatuak erabiliz.
IP helbideen biraketa automatikoa erabiliz, Web Unlocker-en erabiltzaileek helburuko webguneak etengabe arakatu ditzakete, datu garrantzitsuetarako etengabeko sarbidea ziurtatuz.
Garatzaileen eskaera-bidaiak hobetzea
Hainbat ezaugarrik Web Unlocker ezaguna egiten dute garatzaileen artean. Programak datuak biltzeko prozesua arintzen du webgune bakoitzean behar diren erabiltzaile-eragileak automatikoki identifikatuz, denbora eta baliabide baliotsuak aurreztuz.
Web Unlocker denbora errealean egokitzen da detekzioa saihesteko, etengabe aldatzen diren bot-ak blokeatzen dituzten estrategiei erantzunez, interesgarri diren webguneetarako etengabeko sarbidea bermatuz. Plataformaren ikaskuntza automatikoko algoritmoek azkar ebatzi ditzakete captchak, datuak biltzeko ekimenetarako maiz oztopo bat.

Web Unlocker-en prezioa
Mila eskaerako (CPM) 2.03 dolar inguru hasita, Web Unlocker-ek hainbat prezio-aukera eskaintzen ditu hainbat eskari erantzuteko. 7 eguneko doako proba bat erabilgarri dago erabiltzaileek martxan jartzeko eta Web Unlocker-en eginbideak probatu ditzaten konpromisoa hartu aurretik.
Web Unlocker-ek hainbat erabilera-eredu onartzeko moldagarritasuna du, kontsumitzaileek ordaindu ahala nahi duten ala ez beren eskakizunetara egokitutako plan pertsonalizatua behar duten ala ez. Gainera, epe luzerako prezio planak aukeratzen dituztenek % 32 aurreztu dezakete.
Web Desblokeatzailearen arteko konparaketa autokudeatutako proxyekin
Web Unlocker-ek berehalako abantaila ugari eskaintzen ditu autokudeatutako proxyen aurrean. Ezarpen egokia lortzeko, integrazio-teknika zabala eskaintzen du, super proxy eta Proxy Manager funtzioak konbinatzen dituena. Erabiltzaileek modu eraginkorrean eskalatu ditzakete datuak biltzeko eragiketak aldibereko konexio kopuru infinitu batekin.
Web Unlocker-ek desblokeatze automatikoa eskaintzen du, CAPTCHAak konpontzen ditu eta marka-aldaketak behar bezala kudeatzen ditu xede webguneetan.
Plataformak datuen erauzketa etengabea eta fidagarria bermatzen du auto-berriro sistema bat ezarriz eta zenbait domeinutarako dei asinkronoak eginez. Gainera, online Unlocker-en gero eta gero eta handiagoa den HTTP goiburuko eskaerak, guneko arakatzaileko cookie-ak eta simulatutako tramankuluak erabiltzaileei detektatu gabe geratzeko aukera ematen die sareko datuak denbora errealean eskura ditzaketen bitartean.
Azken gogoetak eta gogoan hartzeko gauza garrantzitsuak
Azkenik, Bright Data Instagram scraping-erako erabiltzen duzun bitartean, funtsezkoa da funtsezko puntu batzuk gogoan izatea.
Kontuan izan haien scraping gaitasunak publikoki eskuragarri dauden datuetara mugatuta daudela, praktika etikoen arabera.
Beti jarraitu behar dituzu Instagram-en zerbitzu-baldintzak eta pribatutasun-politikak. Scraping etikoki eta arduraz egin behar da, erabiltzaileen eskubideetan sartu gabe edo legerik hautsi gabe.
Bigarrenik, eguneratu eta egokitu zure scraping parametroak aldizka, berreskuratutako datuen zehaztasuna eta garrantzia ziurtatzeko. Instagram-en plataforma eta algoritmoak alda daitezke, beraz, zure scraping estrategiak aldatu behar dituzu.
Azkenik, erabili Bright Data-ren plataformaren laguntza eta baliabideak zure Instagram scraping ahaleginen arrakasta optimizatzeko. Hartu haien dokumentazioarekin, tutorialekin eta bezeroarentzako arreta-zerbitzuarekin beren scraping tresnen ezagutza hobetzeko.
Ikuspegi erabilgarriak lor ditzakezu, erabakiak hartzen jakintsuetan eragin eta Instagram plataforman datuetan oinarritutako ekimenetan arrakasta izan dezakezu praktika on hauek jarraituz eta Bright Data-ren Instagram scraping gaitasunen indarra erabiliz.





Utzi erantzun bat