Enhavtabelo[Kaŝi][Montri]
Grandaj tekst-al-bildaj modeloj faris signifan progreson en la evoluo de AI produktante altkvalitan kaj multfacetan bildsintezon de antaŭfiksita teksta prompto.
Tiuj modeloj estas nekapablaj sintezi unikajn reprezentadojn de subjektoj en diversaj kontekstoj aŭ reprodukti la aspekton de subjektoj en antaŭfiksita referencaro.
Nov-eldonitaj teknologioj kiel DALL.E2 de OpenAI aŭ StabilityAI Stabila Disvastigo kaj Midjourney jam atakas interreton. Nun estas tempo por personecigi la rezultojn. Tamen kiel?
Google DreamBooth AI alvenis.
DreamBooth havas la kapablon rekoni la temon de bildo, dekonstrui ĝin de ĝia origina kunteksto, kaj tiam precize sintezi ĝin en novan deziratan kuntekston. Aldone, ĝi povas esti uzata kun nunaj AI-bildaj generatoroj.
En ĉi tiu artikolo, ni profunde rigardos DreamBooth, ĝian uzon, ĝian lernilon, ĝiajn limojn kaj multe pli.
Kio estas Dreambooth?
sonĝbudo, tutnova tekst-al-bilda difuzmodelo, estis prezentita fare de Guglo. Skribita instilo povas esti uzata kiel gvido de Google DreamBooth AI por generi ampleksan gamon da fotoj de la elektita temo de la uzanto en malsamaj agordoj.
Esplorgrupo de Boston University kaj Google evoluigis DreamBooth, avangardan teknikon por ŝanĝi tekst-al-bildaj modeloj kiuj spertis ampleksan antaŭtrejnadon.
La ĝenerala koncepto estas sufiĉe simpla: ili volas pliigi la lingvo-vizian vortaron tiel ke maloftaj ĵetonoj estas asociitaj kun kutimaj temoj kiujn uzantoj povas difini.
La ĉefa celo de la modelo estas konekti uzantojn al la tekst-al-bilda disvastigmodelo donante al ili la rimedojn kiujn ili bezonas por produkti fotorealismajn reprezentadojn de la kazoj de ilia elektita temo.
Sekve, ĉi tiu tekniko ŝajnas funkcii bone por resumi defiojn en gamo da situacioj.
DreamBooth de Google diferencas de antaŭaj tekst-al-bildaj iloj, kiel ekzemple DALL-E2, Stabila DisvastigoKaj Mezvojaĝo, en tio ĝi donas al uzantoj pli da kontrolo de la temobildo antaŭ lasado de ili manipuli la difuzmodelon uzante tekst-bazitajn enigaĵojn.
Trajtoj
- DreamBooth AI povus plibonigi tekst-al-bildan modelon kun 3-5 bildoj.
- Originalaj fotorealismaj fotoj povas esti kreitaj per DreamBooth AI.
- Krome, la DreamBooth AI povas krei fotojn de temo el pluraj anguloj.
Apliko
Artaj Reprezentoj
Tiu tasko devias specife de stiltranslokigo, kiu konservas la semantikon de la fontsceno dum integrigado de la stilo de alia bildo en la origina sceno.

Surbaze de la kreiva aliro, la AI povas realigi signifajn scenajn ŝanĝojn konservante la identigon kaj temspecifojn.
Propraĵo-Modifo
La karakterizaĵoj de la subjektokazaĵo povas esti modifitaj fare de DreamBooth AI.

Akcesorigo
La forta komponaĵo antaŭ la generacia modelo estas kio faras la kapablon de DreamBooth AI ornami objektojn tiel interesa.

Rekontekstigo
DreamBooth AI povas produkti karakterizajn bildojn por certa temo, donante al trejnita modelo frazon kiu inkluzivas la unikan identigilon kaj la klassubstantivon.

Ĝi povas generi la subjekton en unikaj, antaŭe neaŭditaj pozoj, artikulacioj, kaj scenstrukturo prefere ol ŝanĝado de la medio. Realismaj reflektadoj kaj ombroj, same kiel interagoj inter la subjekto kaj ĉirkaŭaj objektoj.
Dreambooth lernilo
En ĉi tiu lernilo, ni sekvos la Kajero de Google Collab, kaj mi gvidos vin tra ĝi, kio igos vin kompreni kaj uzi ĝin memstare.
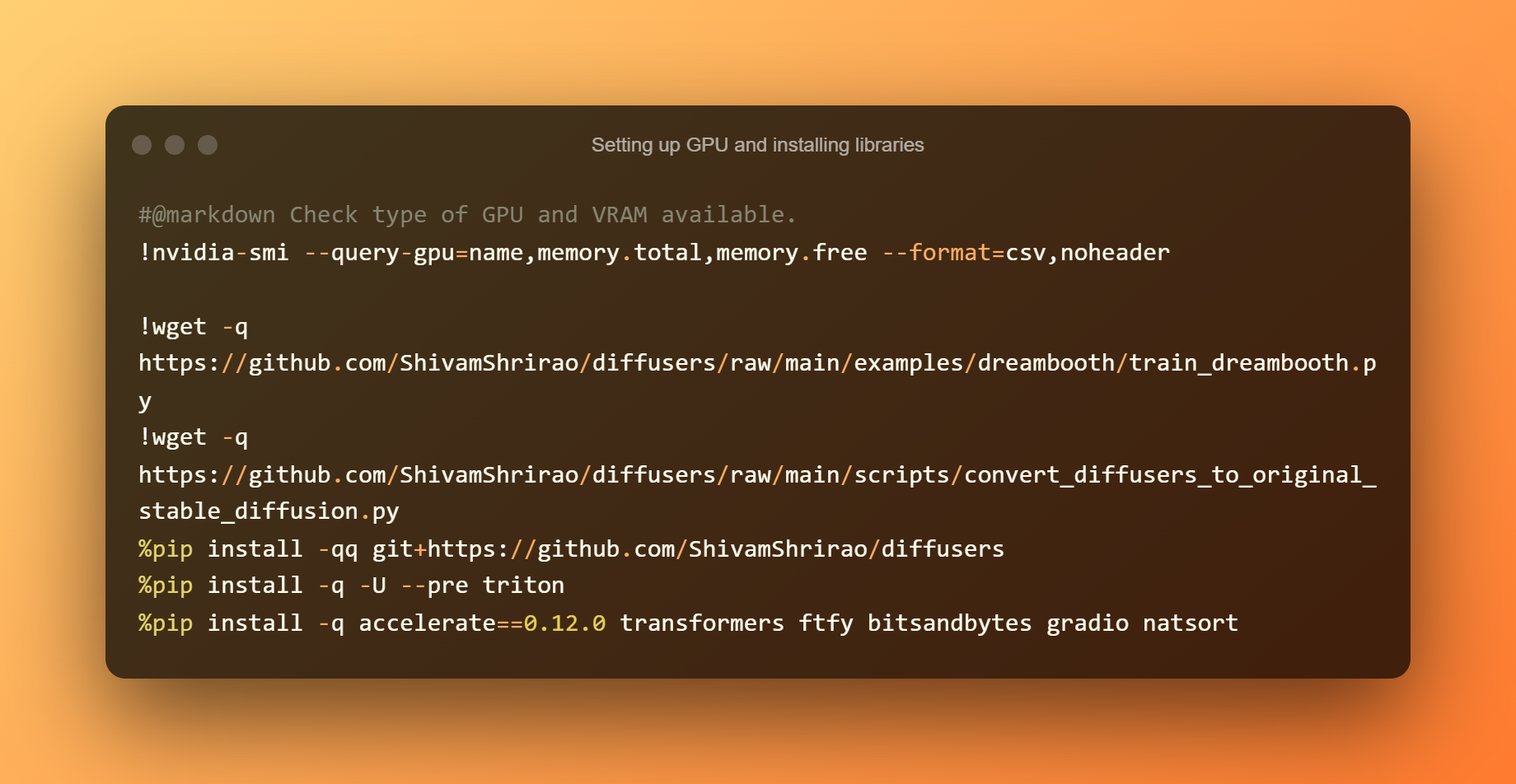
Agordo de GPU kaj instalado de bibliotekoj
Eltrovi kiajn GPU kaj VRAM-specojn disponeblas estas la unua paŝo. Instali kelkajn postulojn kaj dependecojn ankaŭ necesas. Simple premu la ludbutonon, tiam atendu ke ĝi finiĝos.
Kreu konton ĉe Huggingface kaj generu ĵetonon
La sekva paŝo estas registriĝi por Huggingface-konto. Kiam vi finis, alklaku agordojn en la supra dekstra angulo. Vi alvenos al la sekva paĝo.
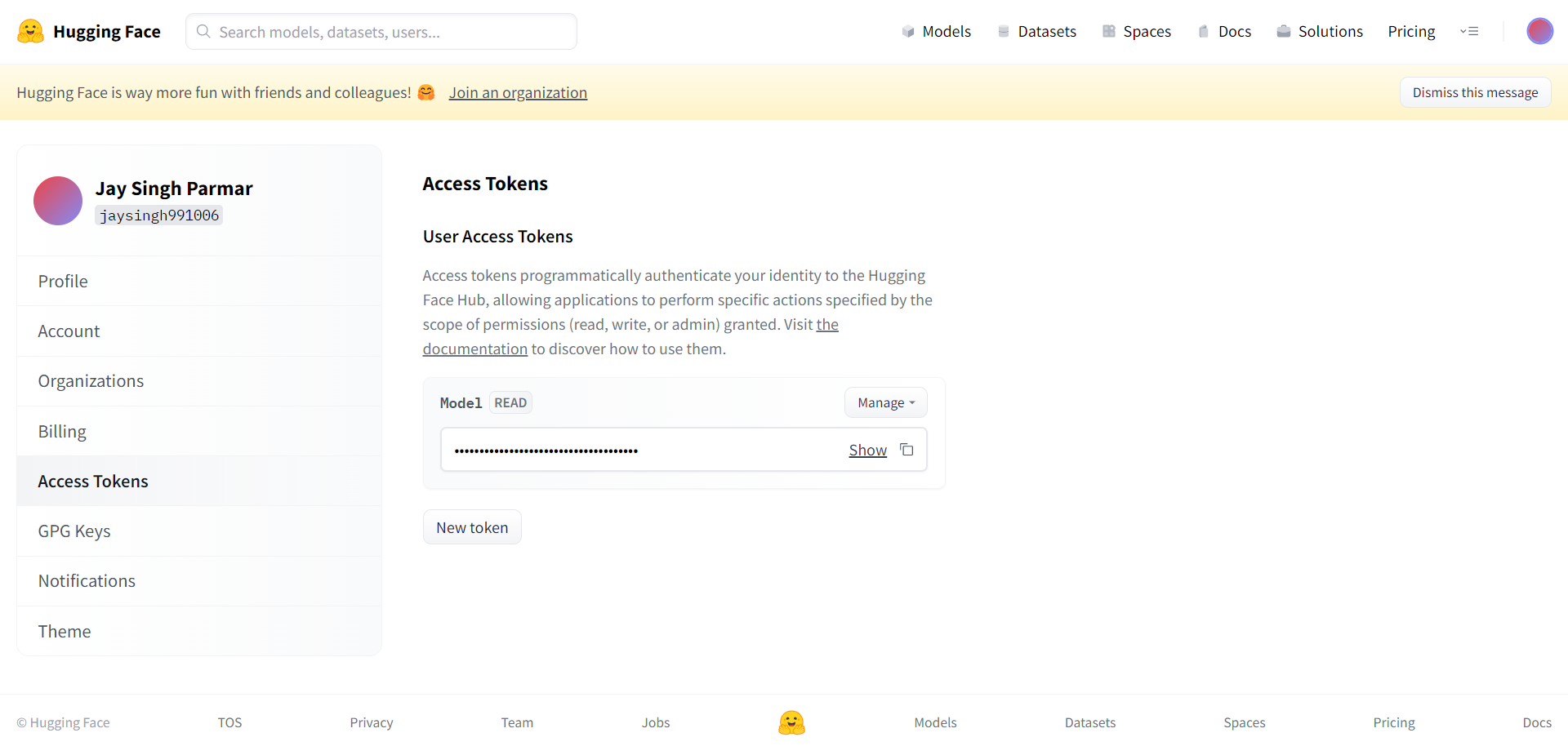
Kreu la ĵetonon kaj nomon laŭ la peto de ĉi tie. La signo devas esti kopiita kaj algluita en la Guglo-kunlaboron en la ĉelo sube.

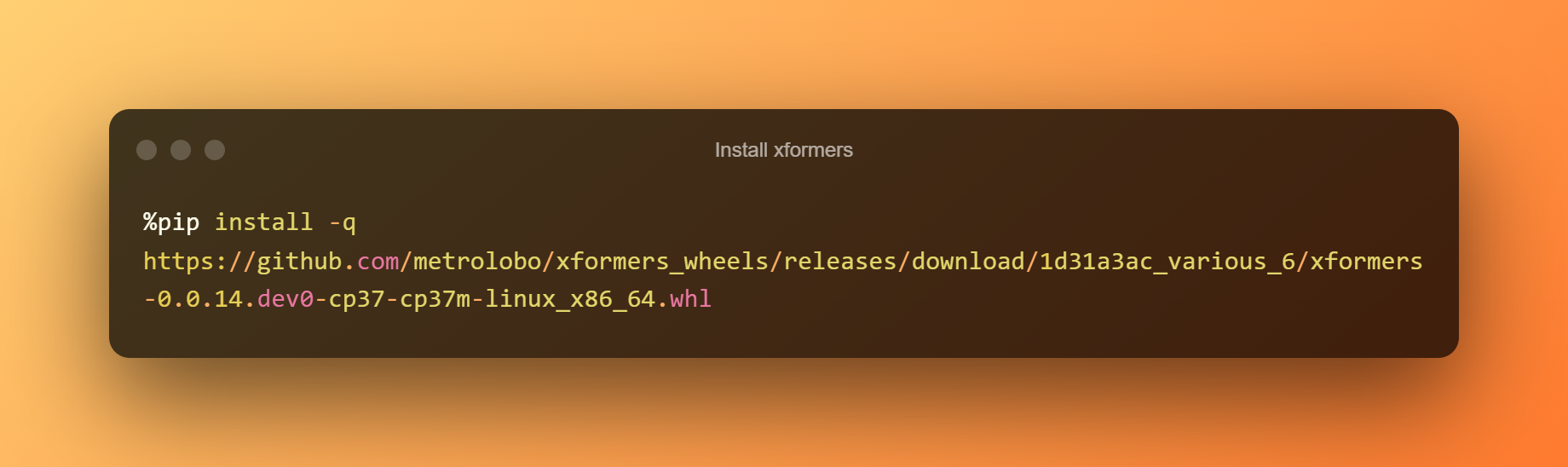
Instalu xformers
En ĉi tiu etapo, vi povas simple premi la ludbutonon por instali xformers alklakante la rultempon.
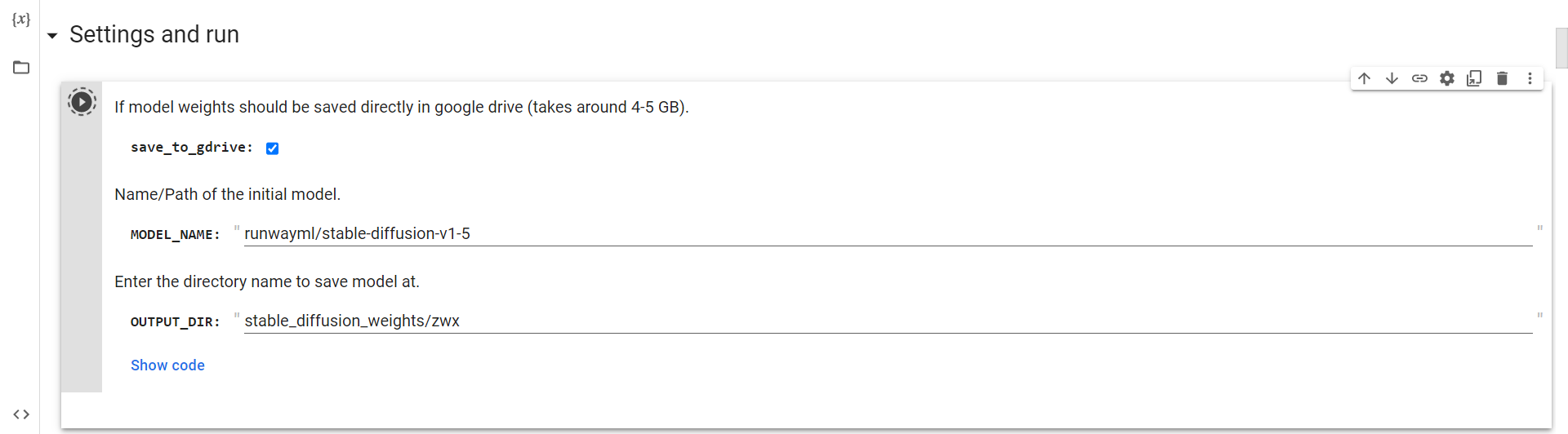
Konekti al Drive
Nun vi nur devas ruli ĉi tiun ĉelon por konekti al google drive.
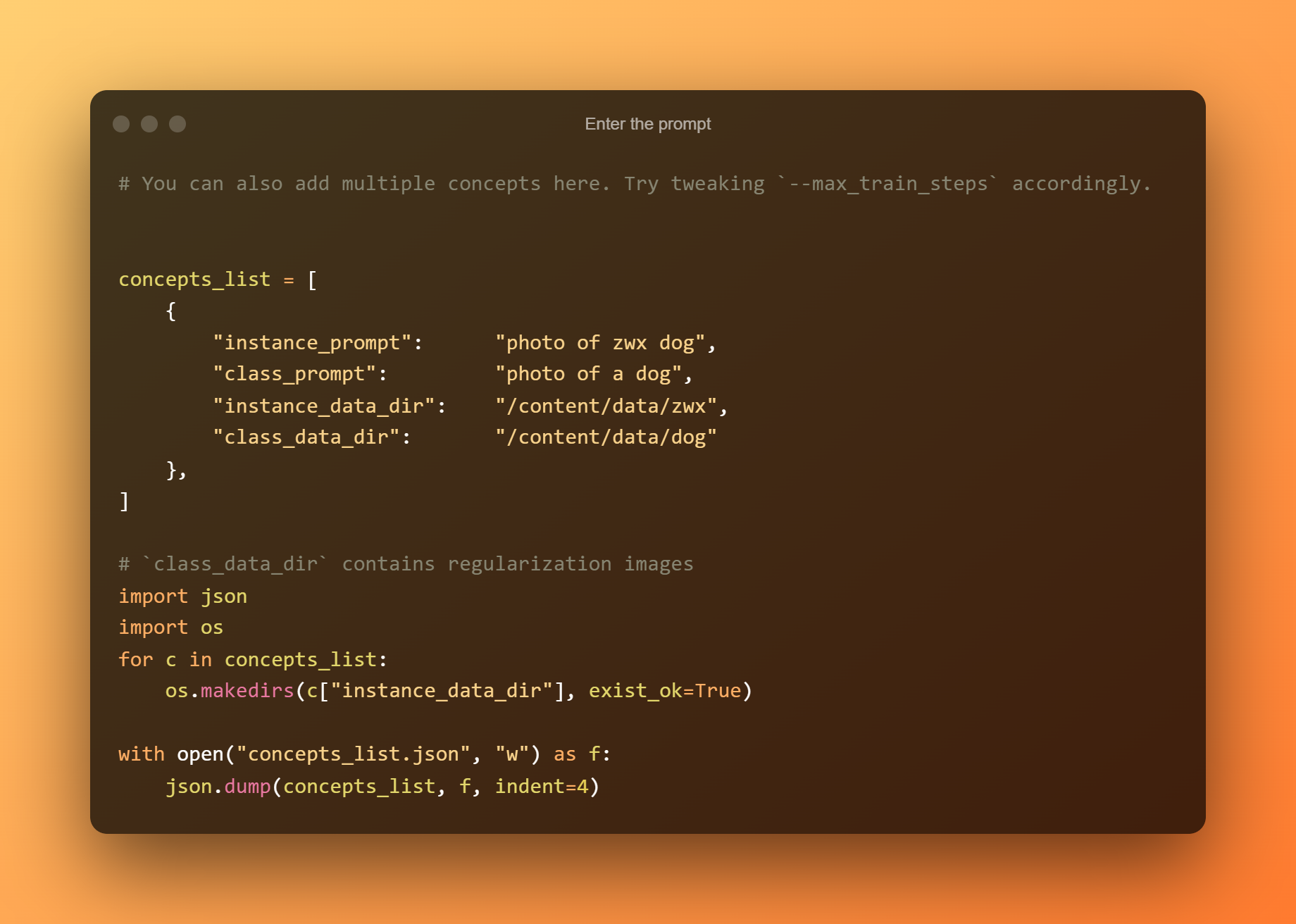
Enigu la prompton
En la sekva ĉelo, vi nur devas enigi la prompton.
Alŝuto de bildoj
En ĉi tiu paŝo, vi nur devas alŝuti la bildojn, kiujn vi volis trejni.

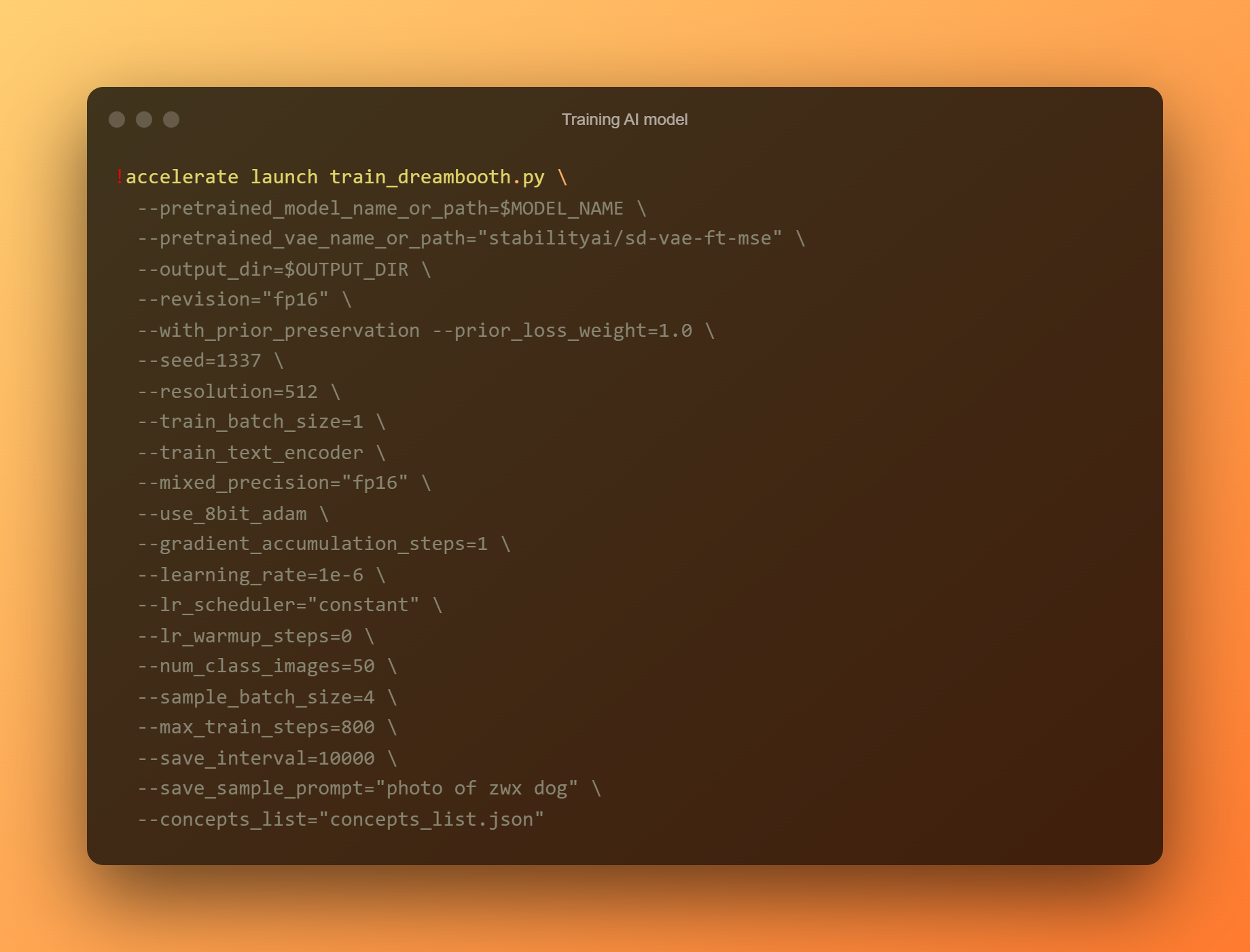
Trajna AI-modelo
Ĉi tiu estas la plej grava fazo, ĉar vi uzos DreamBooth por trejni novan AI-modelon bazitan sur ĉiuj viaj senditaj referencfotoj. Vi devas limigi vian atenton al du enigkampoj. "—instance prompto" estas la unua parametro. Vi devas doni tre klaran nomon ĉi tie.
La argumento '–konceptlisto' estas la dua kritika enigkampo. Ĝi devas esti renomita por kongrui kun tiu uzata en la sekcio "Ŝanĝi la promptilon".
Generu AI-bildojn
La AI-bildoj estos kreitaj en ĉi tiu etapo, kie vi povas enigi la tekstajn instrukciojn.

Dreambooth Limigoj
- La komanda prompto fariĝas baro por fari ripetojn en la temo kun altaj gradoj da detalo. DreamBooth povas ŝanĝi la kuntekston de la subjekto, sed se la modelo deziras ŝanĝi la temon mem, ekzistas problemoj kun la kadro.
- Alia problemo estas troagordi la eligbildon al la eniga bildo. Se ne estas sufiĉe daj bildoj liveritaj, la temo eble ne estas konsiderata aŭ povas esti miksita kun la kunteksto de la senditaj bildoj. Kiam oni demandas kuntekston por nepara generacio, okazas la sama afero.
konkludo
Por produkti produktaĵojn de ununura teksto-enigo, la plejparto de tekst-al-bildaj modeloj postulas milionojn da parametroj kaj bibliotekoj.
DreamBooth simpligas enhavakiron kaj uzadon por konsumantoj postulante nur la enigon de tri ĝis kvin temfotoj kune kun teksta fono.





Lasi Respondon