AI estas ĉie, sed foje povas esti malfacila kompreni la terminologion kaj ĵargonon. En ĉi tiu bloga afiŝo, ni klarigas pli ol 50 terminojn kaj difinojn de AI por ke vi povu kompreni ĉi tiun rapide kreskantan teknologion.
Ĉu vi estas komencanto aŭ spertulo, ni vetas, ke ekzistas kelkaj terminoj ĉi tie, kiujn vi ne konas!
1. Artefarita inteligento
Artefarita inteligento (AI) rilatas al la evoluo de komputilsistemoj kiuj havas la kapablon lerni kaj funkcii sendepende, ofte imitante homan inteligentecon.
Ĉi tiuj sistemoj analizas datumojn, rekonas ŝablonojn, faras decidojn kaj adaptas sian konduton laŭ sperto. Utiligante algoritmojn kaj modelojn, AI celas krei inteligentajn maŝinojn kapablajn percepti kaj kompreni ilian ĉirkaŭaĵon.
La finfina celo estas ebligi maŝinojn plenumi taskojn efike, lerni de datumoj kaj elmontri kognajn kapablojn similajn al homoj.
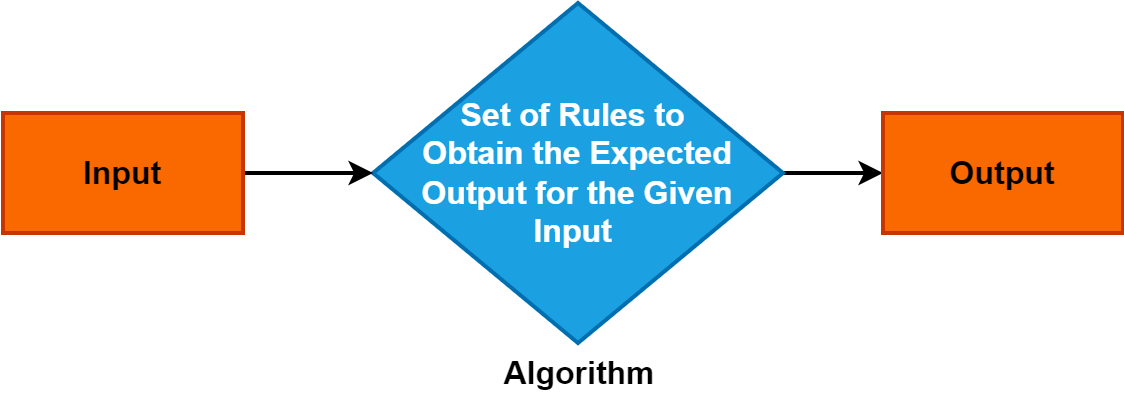
2. Algoritmo
Algoritmo estas preciza kaj sistema aro de instrukcioj aŭ reguloj kiuj gvidas la procezon de solvado de problemo aŭ plenumado de specifa tasko.
Ĝi funkcias kiel fundamenta koncepto en diversaj domajnoj kaj ludas pivotan rolon en komputiko, matematiko, kaj solvantaj disciplinoj. Kompreni algoritmojn estas decida ĉar ili ebligas efikajn kaj strukturitajn problemo-solvajn alirojn, kondukante progresojn en teknologio kaj decidaj procezoj.
3. Granda Datumo
Grandaj datumoj rilatas al ekstreme grandaj kaj kompleksaj datumaroj, kiuj superas la kapablojn de tradiciaj analizmetodoj. Tiuj datenserioj estas tipe karakterizitaj per sia volumeno, rapideco, kaj diverseco.
Volumo rilatas al la vasta kvanto da datumoj generitaj de diversaj fontoj kiel ekzemple sociaj rimedoj, sensiloj, kaj transakcioj.
Rapideco rilatas al la alta rapideco ĉe kiu datenoj estas generitaj kaj devas esti prilaboritaj en reala tempo aŭ preskaŭ reala tempo. Vario signifas la diversajn specojn kaj formatojn de datumoj, inkluzive de strukturitaj, nestrukturitaj kaj duonstrukturitaj datumoj.
4. Datuma Minado
Datumminado estas ampleksa procezo celanta ĉerpi valorajn komprenojn de vastaj datumaroj.
Ĝi ampleksas kvar ŝlosilajn stadiojn: datumkolektado, implikanta la kolekton de koncernaj datumoj; datumpreparo, certigante datumkvaliton kaj kongruecon; minado de la datumoj, utiligante algoritmojn por malkovri ŝablonojn kaj rilatojn; kaj datenanalizo kaj interpreto, kie la eltirita scio estas ekzamenita kaj komprenita.
5. Neŭrala Reto
Komputila sistemo estas dizajnita por funkcii kiel la homa cerbo, kunmetita de interligitaj nodoj aŭ neŭronoj. Ni komprenu ĉi tion iom pli, ĉar plej multaj AI baziĝas sur Neŭraj retoj.
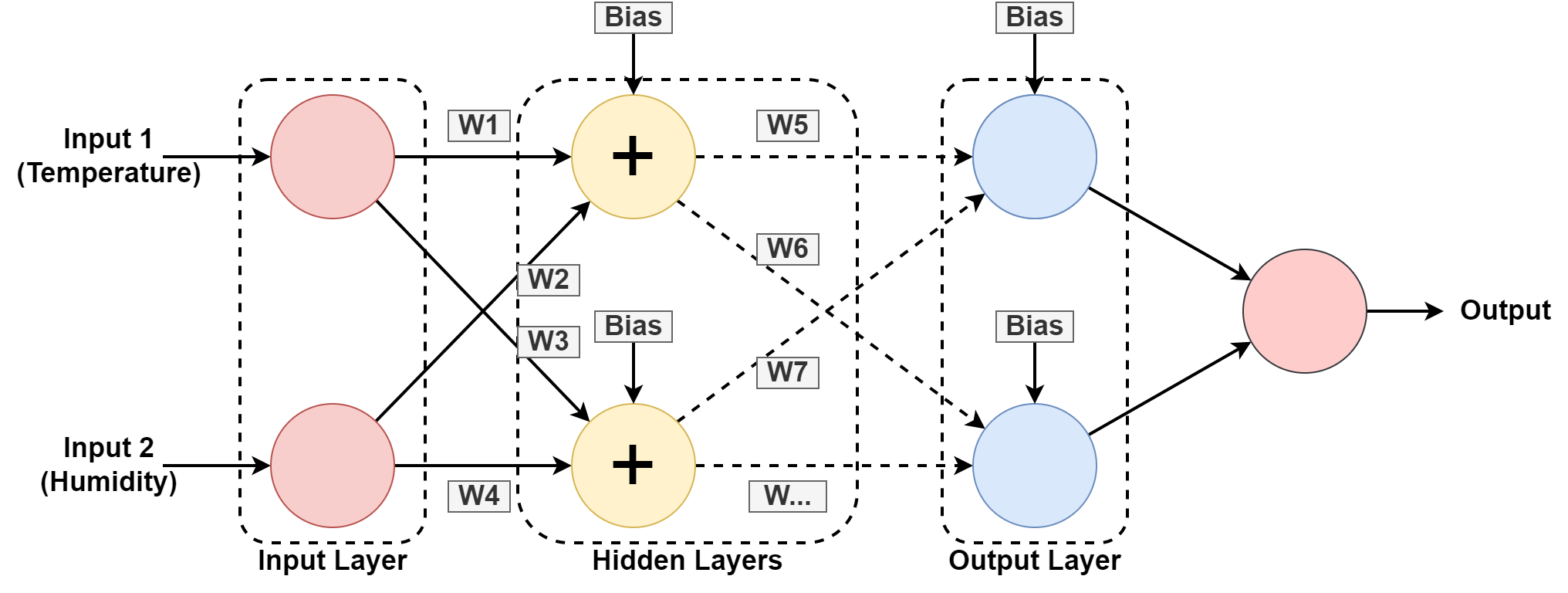
En la supraj grafikaĵoj, ni antaŭdiras la humidon kaj temperaturon de geografia loko per lernado de la pasinta ŝablono. La enigaĵoj estas la datumaro por la pasinta rekordo.
la neŭrala reto lernas la ŝablono per ludado per pezoj kaj aplikante biasvalorojn en la kaŝitaj tavoloj. W1, W2....W7 estas la respektivaj pezoj. Ĝi trejnas sin sur la datumaro provizita kaj donas eligon kiel antaŭdiro.
Vi povas esti superfortita de ĉi tiu kompleksa informo. Se ĉi tio estas la kazo, vi povas komenci per nia simpla gvidilo tie.
6. Maŝinlernado
Maŝinlernado temigas evoluigado de algoritmoj kaj modeloj kapablaj aŭtomate lerni de datumoj kaj plibonigi ilian agadon laŭlonge de la tempo.
Ĝi implikas la uzon de statistikaj teknikoj por ebligi komputilojn identigi padronojn, fari prognozojn kaj fari daten-movitajn decidojn sen esti eksplicite programitaj.
Maŝinlernaj algoritmoj analizi kaj lerni de grandaj datumaroj, permesante al sistemoj adaptiĝi kaj plibonigi sian konduton surbaze de la informoj, kiujn ili prilaboras.
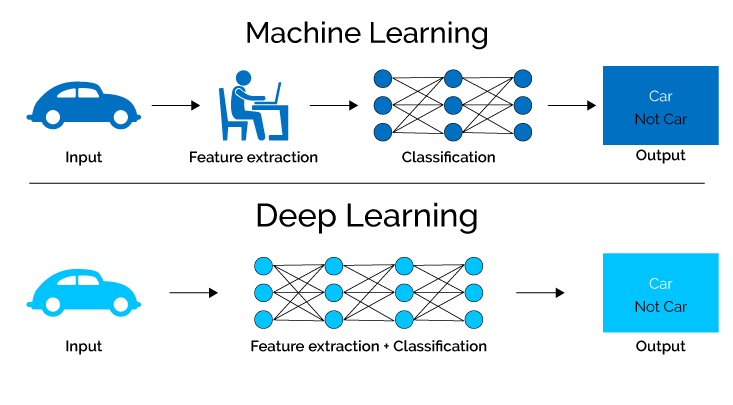
7. Profunda Lernado
Profunda lernado, subkampo de maŝinlernado kaj neŭralaj retoj, ekspluatas sofistikajn algoritmojn por akiri scion de datenoj simulante la malsimplajn procezojn de la homa cerbo.
Uzante neŭralajn retojn kun multaj kaŝitaj tavoloj, profundaj lernaj modeloj povas aŭtonome ĉerpi komplikajn funkciojn kaj ŝablonojn, ebligante ilin trakti kompleksajn taskojn kun escepta precizeco kaj efikeco.
8. Ŝablono-Rekono
Rekono de ŝablonoj, tekniko de datenanalizo, utiligas la potencon de maŝinlernado-algoritmoj por aŭtonome detekti kaj distingi ŝablonojn kaj regulecojn ene de datumaroj.
Utiligante komputilajn modelojn kaj statistikajn metodojn, padronrekono-algoritmoj povas identigi signifajn strukturojn, korelaciojn kaj tendencojn en kompleksaj kaj diversspecaj datenoj.
Ĉi tiu procezo ebligas eltiron de valoraj komprenoj, klasifikon de datumoj en apartajn kategoriojn kaj antaŭdiron de estontaj rezultoj bazitaj sur agnoskitaj ŝablonoj. Rekono de ŝablonoj estas esenca ilo tra diversaj domajnoj, rajtigante decidon, detekto de anomalioj kaj prognoza modeligado.
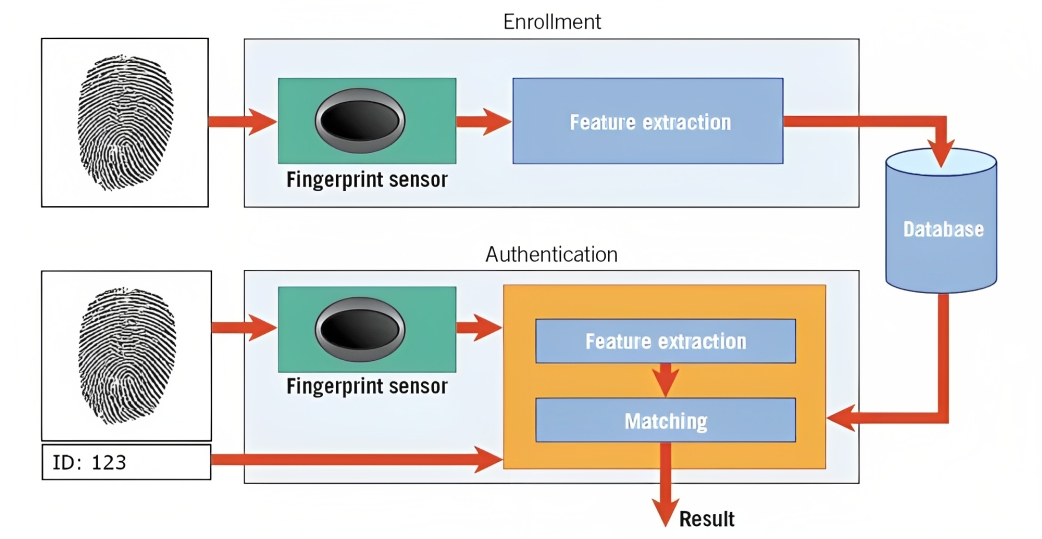
Biometrio estas unu ekzemplo de tio. Ekzemple, en fingrospurrekono, la algoritmo analizas la krestojn, kurbojn, kaj unikajn ecojn de la fingrospuro de persono por krei ciferecan reprezentadon nomitan ŝablono.
Kiam vi provas malŝlosi vian inteligentan telefonon aŭ aliri sekuran instalaĵon, la ŝablono-rekona sistemo komparas la kaptitajn biometriajn datumojn (ekz., fingrospuron) kun la stokitaj ŝablonoj en sia datumbazo.
Kongruante la ŝablonojn kaj taksante la nivelon de simileco, la sistemo povas determini ĉu la provizitaj biometrikaj datenoj kongruas kun la stokita ŝablono kaj doni aliron sekve.
9. Kontrolita Lernado
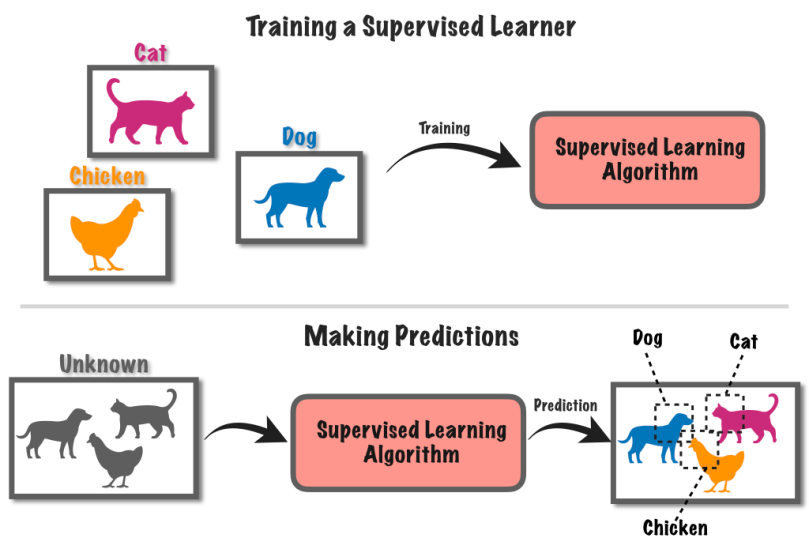
Kontrolita lernado estas maŝinlernado aliro kiu implikas trejni komputilan sistemon uzante etikeditajn datenojn. En ĉi tiu metodo, la komputilo estas provizita per aro de enirdatenoj kune kun ekvivalentaj konataj etikedoj aŭ rezultoj.
Ni diru, ke vi havas amason da bildoj, iuj kun hundoj kaj iuj kun katoj.
Vi diras al la komputilo, kiuj bildoj havas hundojn kaj kiuj havas katojn. La komputilo tiam lernas rekoni la diferencojn inter hundoj kaj katoj trovante ŝablonojn en la bildoj.
Post kiam ĝi lernas, vi povas doni al la komputilo novajn bildojn, kaj ĝi provos eltrovi ĉu ili havas hundojn aŭ katojn surbaze de tio, kion ĝi lernis de la etikeditaj ekzemploj. Estas kiel trejni komputilon por fari prognozojn uzante konatajn informojn.
10. Nekontrolita Lernado
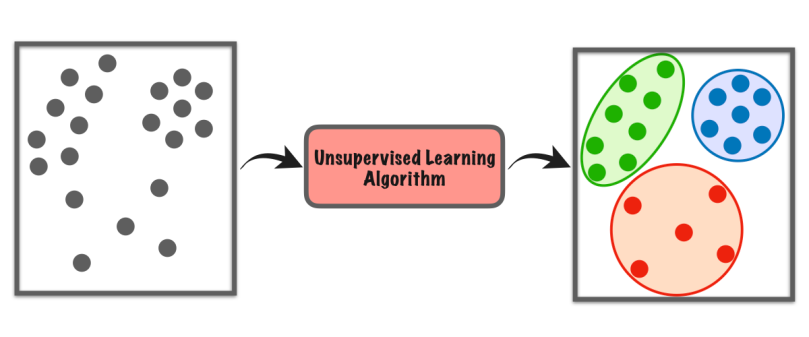
Nekontrolita lernado estas speco de maŝinlernado kie la komputilo esploras datumaron memstare por trovi ŝablonojn aŭ similecojn sen iuj specifaj instrukcioj.
Ĝi ne dependas de etikeditaj ekzemploj kiel en kontrolita lernado. Anstataŭe, ĝi serĉas kaŝitajn strukturojn aŭ grupojn en la datumoj. Estas kvazaŭ la komputilo malkovras aferojn per si mem, sen instruisto diri al ĝi kion serĉi.
Ĉi tiu speco de lernado helpas nin trovi novajn komprenojn, organizi datumojn aŭ identigi nekutimajn aferojn sen bezoni antaŭajn sciojn aŭ eksplicitan gvidadon.
11. Naturlingva Pretigo (NLP)
Natural Language Processing temigas kiel komputiloj komprenas kaj interagas kun homa lingvo. Ĝi helpas komputilojn analizi, interpreti kaj respondi al homa lingvo en maniero kiu sentas pli natura al ni.
NLP estas kio ebligas al ni komuniki kun voĉaj asistantoj, kaj babilrotoj, kaj eĉ havi niajn retpoŝtojn aŭtomate ordigitaj en dosierujojn.
Ĝi implicas instrui komputilojn kompreni la signifon malantaŭ vortoj, frazoj, kaj eĉ tutaj tekstoj, tiel ke ili povas helpi nin en diversaj taskoj kaj fari niajn interagojn kun teknologio pli senjuntaj.
12. Komputila Vido
Komputila vizio estas fascina teknologio, kiu permesas al komputiloj vidi kaj kompreni bildojn kaj filmetojn, same kiel ni homoj faras per niaj okuloj. Ĉio temas pri instruado de komputiloj analizi vidajn informojn kaj kompreni tion, kion ili vidas.
En pli simplaj esprimoj, komputila vizio helpas komputilojn rekoni kaj interpreti la vidan mondon. Ĝi implikas taskojn kiel instrui ilin identigi specifajn objektojn en bildoj, klasifiki bildojn en malsamajn kategoriojn aŭ eĉ dividi bildojn en signifajn partojn.
Imagu memveturantan aŭton uzante komputilan vizion por "vidi" la vojon kaj ĉion ĉirkaŭ ĝi.
Ĝi povas detekti kaj spuri piedirantojn, trafiksignojn kaj aliajn veturilojn, helpante ilin navigi sekure. Aŭ pensu pri kiel vizaĝrekonoteknologio uzas komputilan vizion por malŝlosi niajn saĝtelefonojn aŭ kontroli niajn identecojn rekonante niajn unikajn vizaĝajn trajtojn.
Ĝi ankaŭ estas uzata en gvatsistemoj por monitori plenplenajn lokojn kaj ekvidi ajnajn suspektindajn agadojn.
Komputila vizio estas potenca teknologio, kiu malfermas mondon de eblecoj. Ebligante komputilojn vidi kaj kompreni vidajn informojn, ni povas evoluigi aplikojn kaj sistemojn kiuj povas percepti kaj interpreti la mondon ĉirkaŭ ni, farante nian vivon pli facila, pli sekura kaj pli efika.
13. Babilejo
Babilejo estas kiel komputila programo, kiu povas paroli kun homoj tiel, kiel ŝajnas vera homa konversacio.
Ĝi estas ofte uzata en interreta klientservo por helpi klientojn kaj sentigi ilin kvazaŭ ili parolas kun homo, kvankam ĝi estas fakte programo funkcianta en komputilo.
La babilejo povas kompreni kaj respondi mesaĝojn aŭ demandojn de klientoj, provizante helpajn informojn kaj helpon same kiel farus reprezentanto de homa klientservado.
14. Voĉa Rekono
Voĉa rekono rilatas al la kapablo de komputilsistemo kompreni kaj interpreti homan paroladon. Ĝi implikas la teknologion, kiu ebligas komputilon aŭ aparaton "aŭskulti" parolitajn vortojn kaj konverti ilin en tekston aŭ ordonojn, kiujn ĝi povas kompreni.
kun voĉa rekono, vi povas interagi kun aparatoj aŭ aplikaĵoj simple parolante al ili anstataŭ tajpi aŭ uzi aliajn enigmetodojn.
La sistemo analizas la parolitajn vortojn, rekonas la ŝablonojn kaj sonojn, kaj poste tradukas ilin en kompreneblajn tekstojn aŭ agojn. Ĝi ebligas senmane kaj naturan komunikadon kun teknologio, ebligante taskojn kiel voĉkomandojn, diktadon aŭ voĉkontrolitajn interagojn. La plej oftaj ekzemploj estas la AI-asistantoj kiel Siri kaj Google Assistant.
15. Analizo de Sentoj
Analizo de sentoj estas tekniko uzata por kompreni kaj interpreti la emociojn, opiniojn kaj sintenojn esprimitajn en teksto aŭ parolado. Ĝi implikas analizi skriban aŭ parolan lingvon por determini ĉu la sento esprimita estas pozitiva, negativa aŭ neŭtrala.
Uzante maŝinlernajn algoritmojn, sentoj-algoritmoj povas skani kaj analizi grandajn kvantojn da tekstaj datumoj, kiel klientaj recenzoj, sociaj amaskomunikiloj aŭ klientaj sugestoj, por identigi la suban senton malantaŭ la vortoj.
La algoritmoj serĉas specifajn vortojn, frazojn aŭ ŝablonojn, kiuj indikas emociojn aŭ opiniojn.
Ĉi tiu analizo helpas entreprenojn aŭ individuojn kompreni kiel homoj sentas pri produkto, servo aŭ temo kaj povas esti uzata por fari datumajn decidojn aŭ akiri informojn pri klientpreferoj.
Ekzemple, firmao povas uzi sentan analizon por spuri klientkontenton, identigi areojn por plibonigo aŭ monitori publikan opinion pri sia marko.
16. Maŝina Tradukado
Maŝintradukado, en la kunteksto de AI, rilatas al la uzo de komputilaj algoritmoj kaj artefarita inteligenteco por aŭtomate traduki tekston aŭ paroladon de unu lingvo al alia.
Ĝi implikas instrui komputilojn kompreni kaj prilabori homajn lingvojn por disponigi precizajn tradukojn. La plej ofta ekzemplo estas Gugla tradukilo.
Kun maŝintradukado, vi povas enigi tekston aŭ paroladon en unu lingvo, kaj la sistemo analizos la enigaĵon kaj generos respondan tradukon en alia lingvo. Ĉi tio estas precipe utila kiam oni komunikas aŭ aliras informojn trans malsamaj lingvoj.
Maŝintradukaj sistemoj dependas de kombinaĵo de lingvaj reguloj, statistikaj modeloj kaj maŝinlernado-algoritmoj. Ili lernas el vastaj kvantoj da lingvaj datumoj por plibonigi tradukan precizecon laŭlonge de la tempo. Kelkaj maŝintradukaj aliroj ankaŭ inkluzivas neŭralajn retojn por plibonigi la kvaliton de tradukoj.
17. Robotiko
Robotiko estas la kombinaĵo de artefarita inteligenteco kaj mekanika inĝenierado por krei inteligentajn maŝinojn nomitajn robotoj. Ĉi tiuj robotoj estas dizajnitaj por plenumi taskojn aŭtonome aŭ kun minimuma homa interveno.
Robotoj estas fizikaj estaĵoj kiuj povas senti sian medion, fari decidojn surbaze de tiu sensa enigo kaj plenumi specifajn agojn aŭ taskojn.
Ili estas ekipitaj per diversaj sensiloj, kiel fotiloj, mikrofonoj aŭ tuŝsensiloj, kiuj ebligas al ili kolekti informojn de la mondo ĉirkaŭ ili. Helpe de AI-algoritmoj kaj programado, robotoj povas analizi ĉi tiujn datumojn, interpreti ĝin kaj fari inteligentajn decidojn por plenumi siajn elektitajn taskojn.
AI ludas decidan rolon en robotiko ebligante robotojn lerni de siaj spertoj kaj adaptiĝi al malsamaj situacioj.
Algoritmoj de maŝinlernado povas esti uzataj por trejni robotojn por rekoni objektojn, navigi mediojn aŭ eĉ interagi kun homoj. Tio permesas al robotoj iĝi pli diverstalentaj, flekseblaj kaj kapablaj pritrakti kompleksajn taskojn.
18 Dronoj
Virabeloj estas speco de roboto, kiu povas flugi aŭ ŝvebi en la aero sen homa piloto surŝipe. Ili ankaŭ estas konataj kiel senpilotaj aerveturiloj (UAVoj). Virabeloj estas ekipitaj per diversaj sensiloj, kiel fotiloj, GPS kaj giroskopoj, kiuj permesas al ili kolekti datumojn kaj navigi sian ĉirkaŭaĵon.
Ili estas kontrolataj malproksime de homa funkciigisto aŭ povas funkcii aŭtonome uzante antaŭ-programitajn instrukciojn.
Virabeloj servas larĝan gamon de celoj, inkluzive de aera foto kaj videografio, geodezio kaj mapado, liverservoj, serĉaj kaj savaj misioj, agrikultura monitorado kaj eĉ distra uzo. Ili povas aliri malproksimajn aŭ danĝerajn areojn, kiuj estas malfacilaj aŭ danĝeraj por homoj.
19. Pliigita Realaĵo (AR)
Pliigita realeco (AR) estas teknologio, kiu kombinas la realan mondon kun virtualaj objektoj aŭ informoj por plibonigi nian percepton kaj interagadon kun la medio. Ĝi supermetas komputil-generitajn bildojn, sonojn aŭ aliajn sensajn enigaĵojn al la reala mondo, kreante mergan kaj interagan sperton.
Simple dirite, imagu porti specialajn okulvitrojn aŭ uzi vian inteligentan telefonon por vidi la mondon ĉirkaŭ vi, sed kun pliaj virtualaj elementoj aldonitaj.
Ekzemple, vi povus direkti vian saĝtelefonon al urbostrato kaj vidi virtualajn vojmontrilojn montrantajn indikojn, taksojn kaj recenzojn por proksimaj restoracioj aŭ eĉ virtualajn gravulojn interagantajn kun la reala medio.
Ĉi tiuj virtualaj elementoj miksiĝas perfekte kun la reala mondo, plibonigante vian komprenon kaj sperton de la ĉirkaŭaĵo. Pliigita realeco povas esti uzata en diversaj kampoj kiel videoludado, edukado, arkitekturo, kaj eĉ por ĉiutagaj taskoj kiel navigado aŭ provi novajn meblojn en via hejmo antaŭ ol aĉeti ĝin.
20. Virtuala Realaĵo (VR)
Virtuala realeco (VR) estas teknologio kiu uzas komputil-generitajn simuladojn por krei artefaritan medion kun kiu persono povas esplori kaj interagi. Ĝi mergas la uzanton en virtuala mondo, blokante la realan mondon kaj anstataŭigante ĝin per cifereca regno.
Simple dirite, imagu surmeti specialan aŭdilon, kiu kovras viajn okulojn kaj orelojn kaj transportas vin al tute alia loko. En ĉi tiu virtuala mondo, ĉio, kion vi vidas kaj aŭdas, sentas nekredeble reala, kvankam ĝi estas ĉio generita de komputilo.
Vi povas moviĝi, rigardi en ajna direkto kaj interagi kun objektoj aŭ karakteroj kvazaŭ ili estus fizike ĉeestantaj.
Ekzemple, en virtuala realeca ludo, vi eble trovos vin ene de mezepoka kastelo, kie vi povas promeni tra ĝiaj koridoroj, preni armilojn kaj okupiĝi pri glavbataloj kun virtualaj kontraŭuloj. La medio de virtuala realeco respondas al viaj movoj kaj agoj, igante vin senti vin plene mergita kaj engaĝita en la sperto.
Virtuala realeco estas uzata ne nur por videoludado, sed ankaŭ por diversaj aliaj aplikoj kiel trejnado de simulaĵoj por pilotoj, kirurgoj aŭ armea personaro, arkitekturaj promenoj, virtuala turismo kaj eĉ terapio por certaj psikologiaj kondiĉoj. Ĝi kreas senton de ĉeesto kaj transportas uzantojn al novaj kaj ekscitaj virtualaj mondoj, igante la sperton senti kiel eble plej proksima al realeco.
21. Scienco de datumoj
Scienco de datumoj estas kampo kiu implikas uzi sciencajn metodojn, ilojn kaj algoritmojn por ĉerpi valorajn sciojn kaj komprenojn el datumoj. Ĝi kombinas elementojn de matematiko, statistiko, programado, kaj domajna kompetenteco por analizi grandajn kaj kompleksajn datumarojn.
En pli simplaj terminoj, datuma scienco temas pri trovi signifajn informojn kaj ŝablonojn kaŝitajn en amaso da datumoj. Ĝi implikas kolekti, purigi kaj organizi datumojn, poste uzi diversajn teknikojn por esplori kaj analizi ĝin. Datumaj sciencistoj uzu statistikajn modelojn kaj algoritmojn por malkovri tendencojn, fari antaŭdirojn kaj solvi problemojn.
Ekzemple, en la kampo de sanservo, datuma scienco povas esti uzata por analizi pacientajn registrojn kaj medicinajn datumojn por identigi riskfaktorojn por malsanoj, antaŭdiri pacientajn rezultojn aŭ optimumigi kuracajn planojn. En komerco, datumscienco povas esti aplikata al klientdatenoj por kompreni iliajn preferojn, rekomendi produktojn aŭ plibonigi merkatajn strategiojn.
22. Datuma Kverelado
Datuma kverelado, ankaŭ konata kiel datuma munging, estas la procezo de kolektado, purigado kaj transformado de krudaj datumoj en formaton pli utila kaj taŭga por analizo. Ĝi implikas pritrakti kaj prepari datumojn por certigi ĝian kvaliton, konsistencon kaj kongruon kun analizaj iloj aŭ modeloj.
En pli simplaj terminoj, datuma kverelado estas kiel prepari ingrediencojn por kuirado. Ĝi implikas kolekti datumojn de malsamaj fontoj, ordigi ĝin kaj purigi ĝin por forigi ajnajn erarojn, nekonsekvencojn aŭ palajn informojn.
Aldone, datumoj eble devas esti transformitaj, restrukturitaj aŭ kunigitaj por faciligi labori kun kaj eltiri komprenojn.
Ekzemple, datuma kverelado povas impliki forigi duplikatajn enskribojn, korekti misliterumojn aŭ formatadajn problemojn, pritrakti mankantajn valorojn kaj konverti datumtipojn. Ĝi ankaŭ povas impliki kunfandi aŭ kunigi malsamajn datumarojn kune, dividante datumojn en subarojn, aŭ krei novajn variablojn bazitajn sur ekzistantaj datenoj.
23. Datuma Rakontado
Rakontado de datumoj estas la arto prezenti datumojn en konvinka kaj alloga maniero por efike komuniki rakonton aŭ mesaĝon. Ĝi implikas uzi datumaj bildigoj, rakontoj kaj kunteksto por transdoni komprenojn kaj rezultojn en maniero komprenebla kaj memorinda al la spektantaro.
En pli simplaj terminoj, datuma rakontado temas pri uzado de datumoj por rakonti rakonton. Ĝi iras preter nur prezento de nombroj kaj furorlisto. Ĝi implikas krei rakonton ĉirkaŭ la datumoj, uzante vidajn elementojn kaj rakontadteknikojn por vivigi la datumojn kaj igi ĝin rilatigebla al la spektantaro.
Ekzemple, anstataŭ simple prezenti tabelon de vendaj ciferoj, datumrakontado povus impliki krei interagan instrumentpanelon, kiu permesas al uzantoj esplori la vendajn tendencojn vide.
Ĝi povus inkluzivi rakonton, kiu elstarigas la ŝlosilajn rezultojn, klarigas la kialojn malantaŭ la tendencoj kaj sugestas ageblajn rekomendojn bazitajn sur la datumoj.
24. Daten-movita Decidfarado
Daten-movita decidiĝo estas procezo de farado de elektoj aŭ farado de agoj bazitaj sur la analizo kaj interpreto de signifaj datenoj. Ĝi implikas uzi datumojn kiel fundamenton por gvidi kaj subteni decidajn procezojn prefere ol fidi nur sur intuicio aŭ persona juĝo.
En pli simplaj terminoj, datuma decidado signifas uzi faktojn kaj pruvojn de datumoj por informi kaj gvidi la elektojn, kiujn ni faras. Ĝi implikas kolekti kaj analizi datumojn por kompreni ŝablonojn, tendencojn kaj rilatojn kaj uzi tiun scion por fari informitajn decidojn kaj solvi problemojn.
Ekzemple, en komerca konteksto, datenmovita decidiĝo povas impliki analizi vendajn datumojn, klientajn sugestojn kaj merkatajn tendencojn por determini la plej efikan prezstrategion aŭ identigi areojn por plibonigo en produkta evoluo.
En sanservo, ĝi povas impliki analizi paciencajn datumojn por optimumigi kuracajn planojn aŭ antaŭdiri malsanrezultojn.
25. Datuma Lago
Datumlago estas centralizita kaj skalebla datumdeponejo, kiu stokas vastajn kvantojn da datumoj en sia kruda kaj neprilaborita formo. Ĝi estas dizajnita por teni vastan gamon de datumtipoj, formatoj kaj strukturoj, kiel ekzemple strukturitaj, duonstrukturitaj kaj nestrukturitaj datumoj, sen la bezono de antaŭdifinitaj skemoj aŭ datumtransformoj.
Ekzemple, firmao povas kolekti kaj stoki datumojn de diversaj fontoj, kiel retejaj protokoloj, klienttransakcioj, sociaj amaskomunikiloj kaj IoT-aparatoj, en datuma lago.
Ĉi tiuj datumoj tiam povas esti uzataj por diversaj celoj, kiel fari progresintajn analizojn, plenumi maŝinlernajn algoritmojn aŭ esplori ŝablonojn kaj tendencojn en klienta konduto.
26. Datuma Stokejo
Datumstokejo estas speciala datumbaza sistemo, kiu estas specife dizajnita por stoki, organizi kaj analizi grandajn kvantojn da datumoj de diversaj fontoj. Ĝi estas strukturita en maniero kiel kiu subtenas efikan datumportadon kaj kompleksajn analizajn demandojn.
Ĝi funkcias kiel centra deponejo, kiu integras datumojn de malsamaj operaciaj sistemoj, kiel transakciaj datumbazoj, CRM-sistemoj kaj aliaj datumfontoj ene de organizo.
La datumoj estas transformitaj, purigitaj kaj ŝarĝitaj en la datumstokejon en strukturita formato optimumigita por analizaj celoj.
27. Komerca Inteligenteco (BI)
Komerca inteligenteco rilatas al la procezo kolekti, analizi kaj prezenti datumojn en maniero kiel kiu helpas entreprenojn fari informitajn decidojn kaj akiri valorajn komprenojn. Ĝi implikas uzi diversajn ilojn, teknologiojn kaj teknikojn por transformi krudajn datumojn en signifajn, ageblajn informojn.
Ekzemple, komerca spiona sistemo povus analizi vendajn datumojn por identigi la plej enspezigajn produktojn, monitori inventarnivelojn kaj spuri klientajn preferojn.
Ĝi povas provizi realtempajn sciojn pri ŝlosilaj agado-indikiloj (KPI) kiel enspezo, kliento-akiro aŭ produkta efikeco, permesante al entreprenoj fari decidojn de datumoj kaj fari taŭgajn agojn por plibonigi siajn operaciojn.
Komercaj spionaj iloj ofte inkluzivas funkciojn kiel datuma bildigo, ad hoc demandado kaj datumesploradkapabloj. Ĉi tiuj iloj ebligas uzantojn, kiel ekzemple komercaj analizistoj aŭ administrantoj, por interagi kun la datumoj, tranĉi kaj tranĉi ĝin, kaj generi raportojn aŭ vidajn prezentojn, kiuj elstarigas gravajn komprenojn kaj tendencojn.
28. Antaŭdira Analitiko
Prognoza analizo estas la praktiko uzi datenojn kaj statistikajn teknikojn por fari informitajn prognozojn aŭ prognozojn pri estontaj eventoj aŭ rezultoj. Ĝi implikas analizi historiajn datumojn, identigi ŝablonojn kaj konstrui modelojn por eksterpoli kaj taksi estontajn tendencojn, kondutojn aŭ okazojn.
Ĝi celas malkovri rilatojn inter variabloj kaj uzi tiujn informojn por fari antaŭdirojn. Ĝi iras preter simple priskribado de pasintaj okazaĵoj; anstataŭe, ĝi utiligas historiajn datumojn por kompreni kaj antaŭvidi kio verŝajne okazos en la estonteco.
Ekzemple, en la kampo de financo, prognoza analizo povas esti uzata por prognozi provizo prezoj bazitaj sur historiaj merkataj datumoj, ekonomiaj indikiloj kaj aliaj rilataj faktoroj.
En merkatado, ĝi povas esti uzata por antaŭdiri klientan konduton kaj preferojn, ebligante celitan reklamadon kaj personigitajn merkatajn kampanjojn.
En sanservo, prognoza analizo povas helpi identigi pacientojn kun alta risko por certaj malsanoj aŭ antaŭdiri la probablecon de readmisi surbaze de anamnezo kaj aliaj faktoroj.
29. Preskriba Analizo
Preskriba analizo estas la apliko de datenoj kaj analizoj por determini la plej bonajn eblajn agojn por preni en speciala situacio aŭ decida scenaro.
Ĝi iras preter priskriba kaj prognozaj analizoj ne nur provizante komprenojn pri tio, kio povus okazi en la estonteco, sed ankaŭ rekomendante la plej optimuman agadon por atingi deziratan rezulton.
Ĝi kombinas historiajn datumojn, prognozajn modelojn kaj optimumigajn teknikojn por simuli malsamajn scenarojn kaj taksi la eblajn rezultojn de diversaj decidoj. Ĝi konsideras multoblajn limojn, celojn kaj faktorojn por generi ageblajn rekomendojn, kiuj maksimumigas deziratajn rezultojn aŭ minimumigas riskojn.
Ekzemple, en ĉeno de provizado administrado, preskriba analizo povas analizi datumojn pri stokregistraj niveloj, produktadkapacitoj, transportkostoj kaj klientpostulo por determini la plej efikan distribuplanon.
Ĝi povas rekomendi la idealan atribuon de rimedoj, kiel stokaĵaj stokaj lokoj aŭ transportaj vojoj, por minimumigi kostojn kaj certigi ĝustatempan liveron.
30. Daten-movita Merkatado
Daten-movita merkatado rilatas al la praktiko uzi datenojn kaj analizojn por funkciigi merkatajn strategiojn, kampanjojn kaj decidajn procezojn.
Ĝi implikas utiligi diversajn fontojn de datumoj por akiri komprenojn pri klienta konduto, preferoj kaj tendencoj kaj uzi tiujn informojn por optimumigi merkatajn klopodojn.
Ĝi koncentriĝas pri kolektado kaj analizado de datumoj de pluraj tuŝpunktoj, kiel retejaj interagoj, sociaj amaskomunikiloj, kliento-demografio, aĉethistorio kaj pli. Ĉi tiuj datumoj tiam estas uzataj por krei ampleksan komprenon de la celgrupo, iliaj preferoj kaj iliaj bezonoj.
Utiligante datumojn, merkatistoj povas fari informitajn decidojn pri klientsegmentado, celado kaj personigo.
Ili povas identigi specifajn klientajn segmentojn, kiuj pli verŝajne respondas pozitive al merkataj kampanjoj kaj adapti siajn mesaĝojn kaj ofertojn laŭe.
Aldone, datuma merkatado helpas optimumigi merkatajn kanalojn, determini la plej efikan merkatikan miksaĵon kaj mezuri la sukceson de merkataj iniciatoj.
Ekzemple, daten-movita merkataliro eble implikos analizi klientdatenojn por identigi aĉetan konduton kaj preferpadronojn. Surbaze de ĉi tiuj komprenoj, merkatistoj povas krei celitajn kampanjojn kun personigita enhavo kaj ofertoj, kiuj resonas kun specifaj klientsegmentoj.
Per kontinua analizo kaj optimumigo, ili povas mezuri la efikecon de siaj merkatikaj klopodoj kaj rafini strategiojn laŭlonge de la tempo.
31. Regado de datumoj
Datenregado estas la kadro kaj aro de praktikoj kiujn organizoj adoptas por certigi la taŭgan administradon, protekton kaj integrecon de datumoj dum ĝia vivociklo. Ĝi ampleksas la procezojn, politikojn kaj procedurojn, kiuj regas kiel datumoj estas kolektitaj, stokitaj, aliritaj, uzataj kaj dividitaj ene de organizo.
Ĝi celas establi respondecon, respondecon kaj kontrolon de datumaktivaĵoj. Ĝi certigas, ke datumoj estas precizaj, kompletaj, konsekvencaj kaj fidindaj, ebligante al organizoj fari informitajn decidojn, konservi datumkvaliton kaj plenumi reguligajn postulojn.
Datenregado implikas difini rolojn kaj respondecojn por datumadministrado, establado de datumnormoj kaj politikoj, kaj efektivigado de procezoj por monitori kaj devigi observon. Ĝi traktas diversajn aspektojn de datumadministrado, inkluzive de datuma privateco, datumsekureco, datumkvalito, datumklasifiko kaj datumvivciklo-administrado.
Ekzemple, datuma regado povas impliki efektivigi procedurojn por certigi, ke personaj aŭ sentemaj datumoj estas pritraktitaj konforme al aplikeblaj privatecaj regularoj, kiel la Ĝenerala Regulo pri Protekto de Datumoj (GDPR).
Ĝi ankaŭ povas inkluzivi starigi datenkvalitajn normojn kaj efektivigi datumvalidigajn procezojn por certigi, ke datumoj estas precizaj kaj fidindaj.
32. Datuma Sekureco
Sekureco de datumoj temas pri konservi niajn valorajn informojn sekura kontraŭ neaŭtorizita aliro aŭ ŝtelo. Ĝi implikas preni mezurojn por protekti datumojn konfidencon, integrecon kaj haveblecon.
Esence, ĝi signifas certigi, ke nur la ĝustaj homoj povas aliri niajn datumojn, ke ĝi restas preciza kaj senŝanĝa, kaj ke ĝi estas havebla kiam bezonate.
Por atingi datumsekurecon, diversaj strategioj kaj teknologioj estas uzataj. Ekzemple, alirkontroloj kaj ĉifradmetodoj helpas limigi aliron al rajtigitaj individuoj aŭ sistemoj, igante ĝin pli malfacila por eksteruloj aliri niajn datumojn.
Monitoraj sistemoj, fajroŝirmiloj kaj entrudiĝaj detektaj sistemoj funkcias kiel gardantoj, atentigante nin pri suspektindaj agadoj kaj malhelpante neaŭtorizitan aliron.
33 Interreto de Aĵoj
La Interreto de Aĵoj (IoT) rilatas al reto de fizikaj objektoj aŭ "aĵoj" kiuj estas konektitaj al la Interreto kaj povas komuniki unu kun la alia. Ĝi estas kiel granda reto de ĉiutagaj objektoj, aparatoj kaj maŝinoj, kiuj kapablas kunhavi informojn kaj plenumi taskojn interagante per interreto.
En simplaj terminoj, IoT implikas doni "inteligentajn" kapablojn al diversaj objektoj aŭ aparatoj, kiuj tradicie ne estis konektitaj al la interreto. Ĉi tiuj objektoj povas inkluzivi hejmajn aparatojn, porteblajn aparatojn, termostatojn, aŭtojn kaj eĉ industriajn maŝinojn.
Konektante ĉi tiujn objektojn al la interreto, ili povas kolekti kaj dividi datumojn, ricevi instrukciojn kaj plenumi taskojn aŭtonome aŭ responde al uzantkomandoj.
Ekzemple, inteligenta termostato povas monitori temperaturon, ĝustigi agordojn kaj sendi raportojn pri energia uzado al inteligenta telefono. Portebla taŭgeca spurilo povas kolekti datumojn pri viaj fizikaj agadoj kaj sinkronigi ĝin al nub-bazita platformo por analizo.
34. Arbo de decido
Decidarbo estas vida reprezentado aŭ diagramo, kiu helpas nin fari decidojn aŭ determini agmanieron bazitan sur serio de elektoj aŭ kondiĉoj.
Ĝi estas kiel fludiagramo, kiu gvidas nin tra decida procezo konsiderante malsamajn opciojn kaj iliajn eblajn rezultojn.
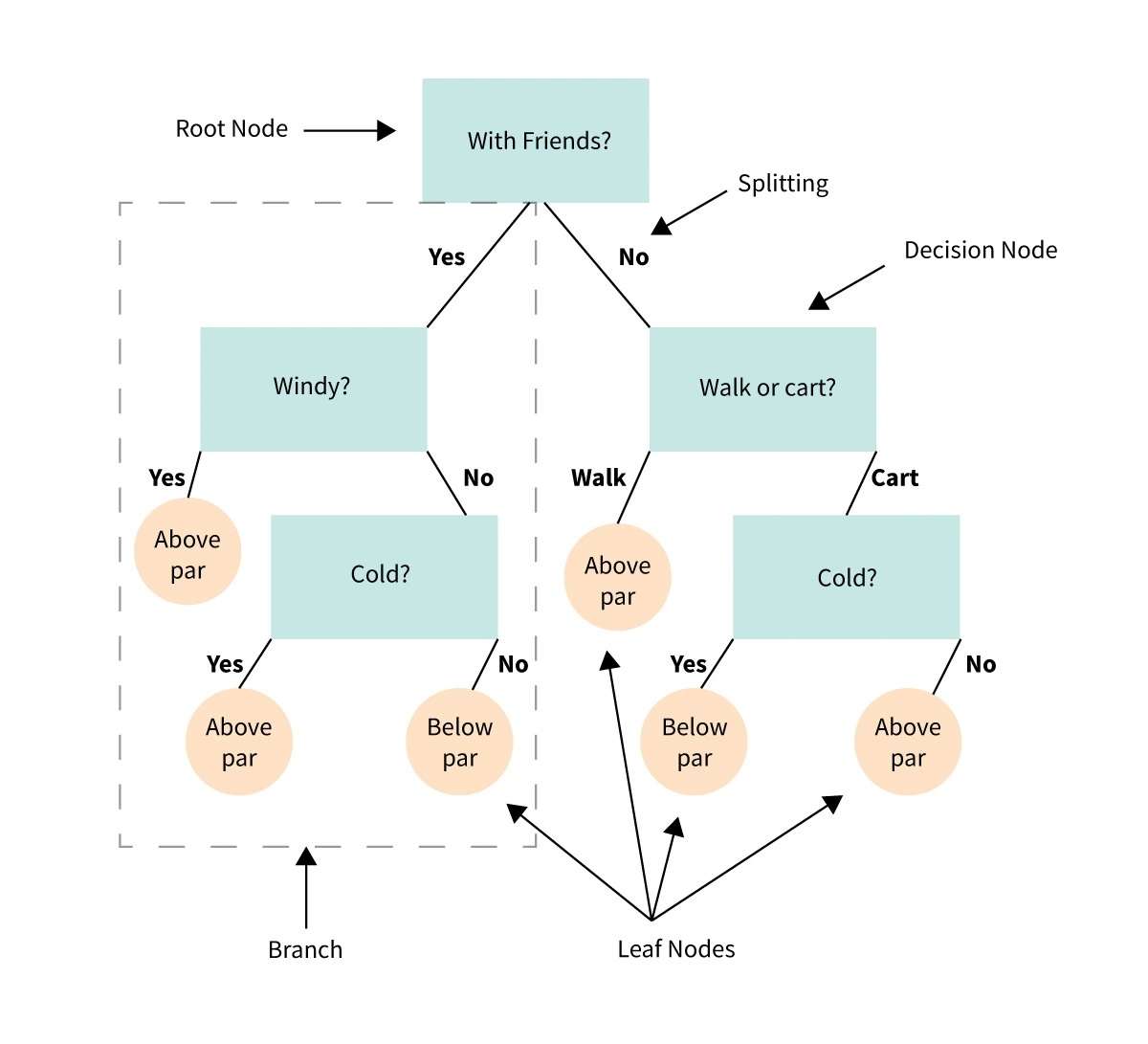
Imagu, ke vi havas problemon aŭ demandon, kaj vi devas fari elekton.
Decidarbo malkonstruas la decidon en pli malgrandajn paŝojn, komencante kun komenca demando kaj disbranĉiĝante en malsamajn eblajn respondojn aŭ agojn bazitajn sur la kondiĉoj aŭ kriterioj ĉe ĉiu paŝo.
35. Kogna Komputado
Kogna komputiko, en simplaj esprimoj, rilatas al komputilsistemoj aŭ teknologioj kiuj imitas homajn kognajn kapablojn, kiel ekzemple lernado, rezonado, kompreno kaj problemo-solvado.
Ĝi implikas krei komputilsistemojn kiuj povas prilabori kaj interpreti informojn en maniero kiel kiu similas homan pensadon.
Kogna komputiko celas evoluigi maŝinojn kiuj povas kompreni kaj interagi kun homoj en pli natura kaj inteligenta maniero. Ĉi tiuj sistemoj estas dizajnitaj por analizi vastajn kvantojn da datumoj, rekoni ŝablonojn, fari antaŭdirojn kaj provizi signifajn komprenojn.
Pensu pri kogna komputado kiel provo igi komputilojn pensi kaj agi pli kiel homoj.
Ĝi implikas utiligi teknologiojn kiel artefarita inteligenteco, maŝinlernado, naturlingva prilaborado kaj komputila vizio por ebligi komputilojn plenumi taskojn kiuj estis tradicie asociitaj kun homa inteligenteco.
36. Komputila Lernada Teorio
Komputila Lernada Teorio estas specialeca branĉo ene de la sfero de artefarita inteligenteco kiu rondiras ĉirkaŭ la evoluo kaj ekzameno de algoritmoj specife dizajnitaj por lerni de datenoj.
Ĉi tiu kampo esploras diversajn teknikojn kaj metodarojn por konstrui algoritmojn, kiuj povas aŭtonome plibonigi sian agadon per analizado kaj prilaborado de grandaj kvantoj da informoj.
Utiligante la potencon de datumoj, Komputila Lernada Teorio celas malkovri ŝablonojn, rilatojn kaj komprenojn, kiuj ebligas maŝinojn plibonigi siajn decidkapablojn kaj plenumi taskojn pli efike.
La finfina celo estas krei algoritmojn kiuj povas adaptiĝi, ĝeneraligi kaj fari precizajn antaŭdirojn bazitajn sur la datenoj al kiuj ili estis eksponitaj, kontribuante al la progreso de artefarita inteligenteco kaj ĝiaj praktikaj aplikoj.
37. Testo de Turing
La Turing-testo, origine proponita de la genia matematikisto kaj komputikisto Alan Turing, estas alloga koncepto uzata por taksi ĉu maŝino povas elmontri inteligentan konduton kompareblan aŭ preskaŭ nedistingeblan de tiu de homo.
En la Turing-testo, homa analizisto okupiĝas pri naturlingva konversacio kun kaj maŝino kaj alia homa partoprenanto sen sciado kiu unu estas la maŝino.
La rolo de la taksisto estas distingi kiu unuo estas la maŝino nur surbaze de iliaj respondoj. Se la maŝino povas konvinki la taksiston ke ĝi estas la homa ekvivalento, tiam ĝi laŭdire pasigis la Turing-teston, tiel montrante nivelon de inteligenteco kiu spegulas homsimilajn kapablojn.
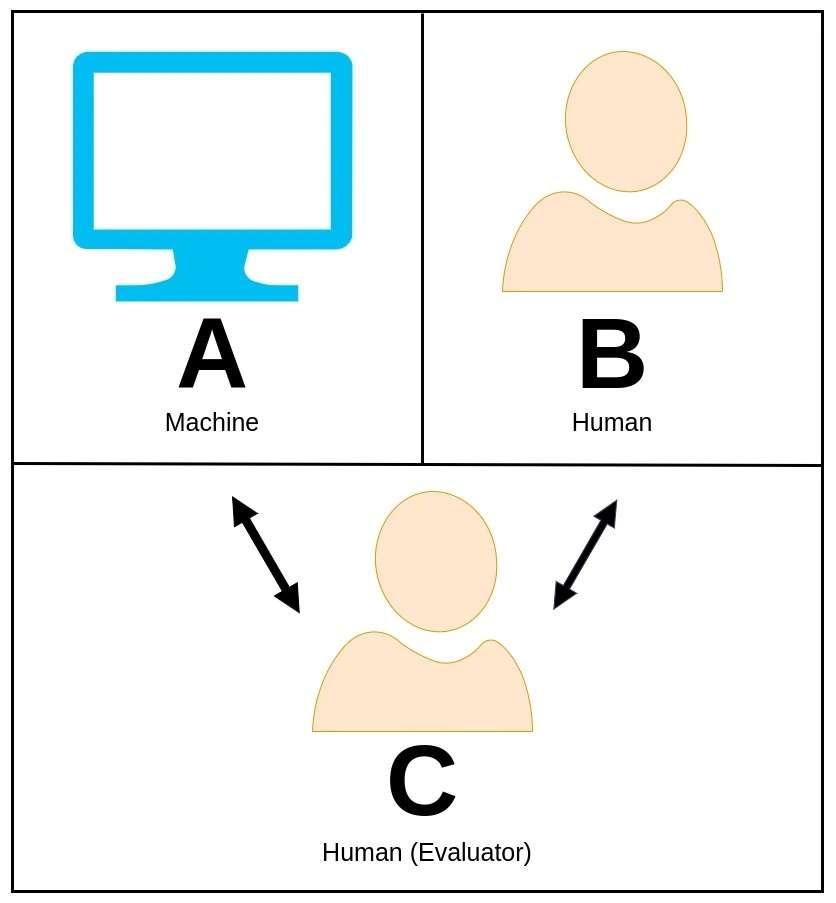
Alan Turing proponis ĉi tiun teston kiel rimedon por esplori la koncepton de maŝininteligenteco kaj prezenti la demandon ĉu maŝinoj povas atingi homnivelan pensadon.
Enkadrigante la teston laŭ homa nedistingebleco, Turing elstarigis la eblecon por maŝinoj elmontri konduton kiu estas tiel konvinke inteligenta ke iĝas defie diferencigi ilin de homoj.
La Turing-testo estigis ampleksajn diskutojn kaj esploradon en la kampoj de artefarita inteligenteco kaj kogna scienco. Dum pasigi la Turing-teston restas signifa mejloŝtono, ĝi ne estas la sola mezuro de inteligenteco.
Tamen, la testo funkcias kiel pensiga komparnormo, stimulante daŭrajn klopodojn evoluigi maŝinojn kapablajn kopii homajn inteligentecon kaj konduton kaj kontribuante al la pli larĝa esplorado de tio, kion ĝi signifas esti inteligenta.
38. Plifortiga Lernado
Plifortiga lernado estas speco de lernado kiu okazas per provo kaj eraro, kie "agento" (kiu povas esti komputila programo aŭ roboto) lernas plenumi taskojn ricevante rekompencojn por bona konduto kaj alfrontante la sekvojn aŭ punojn por malbona konduto.
Imagu scenaron kie la agento provas plenumi specifan taskon, kiel navigi en labirinto. Komence, la agento ne scias la ĝustan vojon por preni, do ĝi provas malsamajn agojn kaj esploras diversajn itinerojn.
Kiam ĝi elektas bonan agon, kiu proksimigas ĝin al la celo, ĝi ricevas rekompencon, kiel virtuala "frapeto sur la dorson". Tamen, se ĝi faras malbonan decidon, kiu kondukas al sakstrato aŭ forprenas ĝin de la celo, ĝi ricevas punon aŭ negativan reagojn.
Tra ĉi tiu procezo de provo kaj eraro, la agento lernas asocii certajn agojn kun pozitivaj aŭ negativaj rezultoj. Ĝi iom post iom eltrovas la plej bonan sinsekvon de agoj por maksimumigi siajn rekompencojn kaj minimumigi punojn, finfine iĝante pli kompetenta pri la tasko.
Plifortiga lernado desegnas inspiron de kiel homoj kaj bestoj lernas ricevante religon de la medio.
Aplikante ĉi tiun koncepton al maŝinoj, esploristoj celas evoluigi inteligentajn sistemojn kiuj povas lerni kaj adaptiĝi al malsamaj situacioj aŭtonome malkovrante la plej efikajn kondutojn per procezo de pozitiva plifortigo kaj negativaj sekvoj.
39. Ento Eltiro
Ento-ekstraktado rilatas al procezo en kiu ni identigas kaj ĉerpas gravajn informojn, konatajn kiel entojn, el bloko de teksto. Ĉi tiuj estaĵoj povas esti diversaj aferoj kiel la nomoj de homoj, nomoj de lokoj, nomoj de organizoj, ktp.
Ni imagu, ke vi havas alineon priskribanta novaĵartikolon.
Enta eltiro implikus analizi la tekston kaj elekti specifajn pecojn kiuj reprezentas apartajn entojn. Ekzemple, se la teksto mencias la nomon de persono kiel "John Smith", la lokon "Novjorko" aŭ la organizon "OpenAI", ĉi tiuj estus la estaĵoj, kiujn ni celas identigi kaj ĉerpi.
Farante entan eltiron, ni esence instruas komputilan programon rekoni kaj izoli signifajn elementojn de la teksto. Ĉi tiu procezo ebligas al ni organizi kaj kategoriigi informojn pli efike, faciligante serĉi, analizi kaj derivi komprenojn de grandaj volumoj de tekstaj datumoj.
Ĝenerale, enta eltiro helpas nin aŭtomatigi la taskon indiki gravajn entojn, kiel homoj, lokoj kaj organizoj, ene de la teksto, simpligante la eltiron de valoraj informoj kaj plibonigante nian kapablon prilabori kaj kompreni tekstajn datumojn.
40. Lingva Komentario
Lingva komentario implicas riĉigi tekston per pliaj lingvaj informoj por plibonigi nian komprenon kaj analizon de la uzata lingvo. Estas kiel aldoni helpajn etikedojn aŭ etikedojn al malsamaj partoj de teksto.
Kiam ni faras lingvan komentarion, ni preterpasas la bazajn vortojn kaj frazojn en teksto kaj komencas etikedi aŭ etikedi specifajn elementojn. Ekzemple, ni povus aldoni parolad-etikedojn, kiuj indikas la gramatikan kategorion de ĉiu vorto (kiel substantivo, verbo, adjektivo, ktp.). Ĉi tio helpas nin kompreni la rolon kiun ĉiu vorto ludas en frazo.
Alia formo de lingva komentario estas nomita entorekono, kie ni identigas kaj etikedas specifajn nomitajn unuojn, kiel ekzemple nomoj de homoj, lokoj, organizoj aŭ datoj. Ĉi tio permesas al ni rapide lokalizi kaj ĉerpi gravajn informojn el la teksto.
Komentante tekston tiamaniere, ni kreas pli strukturitan kaj organizitan reprezenton de la lingvo. Ĉi tio povas esti ege utila en diversaj aplikoj. Ekzemple, ĝi helpas plibonigi la precizecon de serĉiloj komprenante la intencon malantaŭ uzantdemandoj. Ĝi ankaŭ helpas en maŝintradukado, sentanalizo, inform-eltiro kaj multaj aliaj naturlingvaj prilaboraj taskoj.
Lingva komentario funkcias kiel esenca ilo por esploristoj, lingvistoj kaj programistoj, ebligante ilin studi lingvajn ŝablonojn, konstrui lingvomodelojn kaj evoluigi kompleksajn algoritmojn, kiuj povas pli bone analizi kaj kompreni la tekston.
41. Hiperparametro
In maŝinlernado, hiperparametro estas kiel speciala agordo aŭ agordo, pri kiu ni devas decidi antaŭ trejnado de modelo. Ĝi ne estas io, kion la modelo povas lerni memstare de la datumoj; anstataŭe, ni devas determini ĝin antaŭe.
Pensu pri ĝi kiel butonon aŭ ŝaltilon, kiun ni povas ĝustigi por agordi kiel la modelo lernas kaj faras antaŭdirojn. Tiuj hiperparametroj regas diversajn aspektojn de la lernado, kiel ekzemple la komplekseco de la modelo, la rapideco de trejnado, kaj la avantaĝinterŝanĝo inter precizeco kaj ĝeneraligo.
Ekzemple, ni konsideru neŭralan reton. Unu grava hiperparametro estas la nombro da tavoloj en la reto. Ni devas elekti kiom profunda ni volas, ke la reto estu, kaj ĉi tiu decido influas ĝian kapablon kapti kompleksajn ŝablonojn en la datumoj.
Aliaj komunaj hiperparametroj inkluzivas la lernadon, kiu determinas kiom rapide la modelo alĝustigas siajn internajn parametrojn surbaze de la trejnaddatenoj, kaj la reguligforton, kiu kontrolas kiom multe la modelo punas kompleksajn padronojn por malhelpi trofitting.
Agordi ĉi tiujn hiperparametrojn ĝuste estas decida ĉar ili povas signife influi la efikecon kaj konduton de la modelo. Ĝi ofte implikas iom da provo kaj eraro, eksperimentante kun malsamaj valoroj kaj observante kiel ili influas la agadon de la modelo sur validuma datumaro.
42. Metadatenoj
Metadatenoj rilatas al pliaj informoj, kiuj provizas detalojn pri aliaj datumoj. Ĝi estas kiel aro de etikedoj aŭ etikedoj kiuj donas al ni pli da kunteksto aŭ priskribas la karakterizaĵojn de la ĉefaj datumoj.
Kiam ni havas datumojn, ĉu ĝi estas dokumento, foto, video aŭ ajna alia speco de informoj, metadatenoj helpas nin kompreni gravajn aspektojn de tiuj datumoj.
Ekzemple, en dokumento, metadatenoj povus inkluzivi detalojn kiel la nomo de la aŭtoro, la dato kiam ĝi estis kreita aŭ la dosierformato. En la kazo de foto, metadatenoj povus diri al ni la lokon, kie ĝi estis prenita, la fotilaj agordoj uzataj, aŭ eĉ la daton kaj horon, kiam ĝi estis kaptita.
Metadatumoj helpas nin organizi, serĉi kaj interpreti datumojn pli efike. Aldonante ĉi tiujn priskribajn informojn, ni povas rapide trovi specifajn dosierojn aŭ kompreni ilian originon, celon aŭ kuntekston sen devi trafosi la tutan enhavon.
43. Dimensieco Redukto
Dimensiecredukto estas tekniko uzita por simpligi datumaron reduktante la nombron da trajtoj aŭ variabloj kiujn ĝi enhavas. Estas kiel densigi aŭ resumi la informojn en datumaro por fari ĝin pli regebla kaj pli facile labori kun.
Imagu, ke vi havas datumaron kun multaj kolumnoj aŭ atributoj reprezentantaj malsamajn trajtojn de la datumpunktoj. Ĉiu kolumno aldonas al la komplekseco kaj komputilaj postuloj de maŝinlernado-algoritmoj.
En iuj kazoj, havi altan nombron da dimensioj povas fari ĝin malfacila trovi signifajn ŝablonojn aŭ rilatojn en la datumoj.
Dimensiecredukto helpas trakti ĉi tiun temon transformante la datumaron en malsupra-dimensian reprezentadon konservante kiel eble plej multe da signifaj informoj. Ĝi celas kapti la plej gravajn aspektojn aŭ variojn en la datumoj forĵetante superfluajn aŭ malpli informajn dimensiojn.
44. Teksta Klasifiko
Tekstoklasifiko estas procezo kiu implikas asigni specifajn etikedojn aŭ kategoriojn al blokoj de teksto bazitaj sur ilia enhavo aŭ signifo. Estas kiel ordigi aŭ organizi tekstajn informojn en malsamajn grupojn aŭ klasojn por faciligi plian analizon aŭ decidon.
Ni konsideru ekzemplon de retpoŝta klasifiko. En ĉi tiu scenaro, ni volas determini ĉu envenanta retpoŝto estas spamo aŭ ne-spamo (ankaŭ konata kiel ŝinko). Klasifiko de tekstoj algoritmoj analizas la enhavon de la retpoŝto kaj atribuas al ĝi etikedon laŭe.
Se la algoritmo determinas, ke la retpoŝto prezentas trajtojn kutime asociitajn kun spamo, ĝi atribuas la etikedon "spamo". Male, se la retpoŝto aperas laŭleĝa kaj ne-spama, ĝi atribuas la etikedon "ne-spamo" aŭ "ŝinko".
Teksta klasifiko trovas aplikojn en diversaj domajnoj preter retpoŝta filtrado. Ĝi estas uzata en sentanalizo por determini la senton esprimitan en klientrecenzoj (pozitivaj, negativaj aŭ neŭtralaj).
Novaĵartikoloj povas esti klasifikitaj en malsamaj temoj aŭ kategorioj kiel sportoj, politikoj, distro kaj pli. Klientsubtenaj babilejprogramoj povas esti kategoriigitaj laŭ la intenco aŭ problemo traktita.
45. Malforta AI
Malforta AI, ankaŭ konata kiel mallarĝa AI, rilatas al artefarita inteligenteco sistemoj kiuj estas dizajnitaj kaj programitaj por plenumi specifajn taskojn aŭ funkciojn. Male al homa inteligenteco, kiu ampleksas larĝan gamon de kognaj kapabloj, malforta AI estas limigita al speciala domajno aŭ tasko.
Pensu pri malforta AI kiel speciala programaro aŭ maŝinoj, kiuj elstaras en plenumado de specifaj laboroj. Ekzemple, ŝak-ludanta AI-programo povas esti kreita por analizi ludsituaciojn, strategii movojn, kaj konkuri kontraŭ homaj ludantoj.
Alia ekzemplo estas bildrekonosistemo kiu povas identigi objektojn en fotoj aŭ vidbendoj.
Ĉi tiuj AI-sistemoj estas trejnitaj kaj optimumigitaj por elstari en siaj specifaj kompetentecoj. Ili dependas de algoritmoj, datumoj kaj antaŭdifinitaj reguloj por plenumi siajn taskojn efike.
Tamen, ili ne posedas ĝeneralan inteligentecon kiu permesas al ili kompreni aŭ plenumi taskojn ekster sia elektita domajno.
46. Forta AI
Forta AI, ankaŭ konata kiel ĝenerala AI aŭ artefarita ĝenerala inteligenteco (AGI), rilatas al formo de artefarita inteligenteco kiu posedas la kapablon kompreni, lerni kaj plenumi ajnan intelektan taskon kiun homo povas.
Male al malforta AI, kiu estas dizajnita por specifaj taskoj, forta AI celas reprodukti homsimilan inteligentecon kaj kognajn kapablojn. Ĝi strebas krei maŝinojn aŭ programojn, kiuj ne nur elstaras je specialaj taskoj, sed ankaŭ posedas pli larĝan komprenon kaj adapteblecon por trakti ampleksan gamon de intelektaj defioj.
La celo de forta AI estas evoluigi sistemojn kiuj povas rezoni, kompreni kompleksajn informojn, lerni de sperto, okupiĝi pri naturlingvaj konversacioj, elmontri kreivon kaj elmontri aliajn kvalitojn asociitajn kun homa inteligenteco.
Esence, ĝi aspiras krei AI-sistemojn, kiuj povas simuli aŭ reprodukti homnivelan pensadon kaj problemo-solvon tra pluraj domajnoj.
47. Antaŭen Ĉenado
Antaŭen ĉenado estas metodo de rezonado aŭ logiko, kiu komenciĝas per la disponeblaj datumoj kaj uzas ĝin por fari konkludojn kaj tiri novajn konkludojn. Estas kiel ligi la punktojn uzante la informojn por antaŭeniri kaj atingi pliajn komprenojn.
Imagu, ke vi havas aron da reguloj aŭ faktoj, kaj vi volas derivi novajn informojn aŭ atingi specifajn konkludojn bazitajn sur ili. Antaŭen ĉenado funkcias ekzamenante la komencajn datumojn kaj aplikante logikajn regulojn por generi pliajn faktojn aŭ konkludojn.
Por simpligi, ni konsideru simplan scenaron por determini kion porti surbaze de veterkondiĉoj. Vi havas regulon kiu diras: "Se pluvas, kunportu ombrelon", kaj alian regulon kiu diras "Se estas malvarme, portu jakon." Nun, se vi observas, ke ja pluvas, vi povas uzi antaŭan ĉenadon por konkludi, ke vi devas kunporti ombrelon.
48. Malantaŭa Ĉenado
Malantaŭen ĉenado estas rezona metodo, kiu komenciĝas per dezirata konkludo aŭ celo kaj funkcias malantaŭen por determini la necesajn datumojn aŭ faktojn necesajn por subteni tiun konkludon. Estas kiel spuri viajn paŝojn de la dezirata rezulto ĝis la komencaj informoj bezonataj por atingi ĝin.
Por kompreni malantaŭen ĉenadon, ni konsideru simplan ekzemplon. Supozu, ke vi volas determini ĉu taŭgas naĝi. La dezirata konkludo estas ĉu aŭ ne naĝado taŭgas surbaze de certaj kondiĉoj.
Anstataŭ komenci kun la kondiĉoj, malantaŭa ĉenado komenciĝas per la konkludo kaj funkcias malantaŭen por trovi la subtenajn datumojn.
En ĉi tiu kazo, malantaŭa ĉenado implicus fari demandojn kiel "Ĉu la vetero varmas?" Se la respondo estas jes, vi tiam demandus, "Ĉu estas disponebla naĝejo?" Se la respondo denove estas jesa, vi demandus pliajn demandojn kiel: "Ĉu estas sufiĉe da tempo por naĝi?"
Ripete respondante ĉi tiujn demandojn kaj laborante malantaŭen, vi povas determini la necesajn kondiĉojn, kiujn oni devas plenumi por subteni la konkludon de naĝado.
49. Heŭristiko
Heŭristiko, en simplaj terminoj, estas praktika regulo aŭ strategio, kiu helpas nin fari decidojn aŭ solvi problemojn, kutime surbaze de niaj pasintaj spertoj aŭ intuicio. Ĝi estas kiel mensa ŝparvojo, kiu permesas al ni rapide elpensi akcepteblan solvon sen trapasi longan aŭ ĝisfundan procezon.
Se alfrontite kun kompleksaj situacioj aŭ taskoj, heŭristiko funkcias kiel gvidprincipoj aŭ "reguloj de dikfingro" kiuj simpligas decidon. Ili provizas al ni ĝeneralajn gvidliniojn aŭ strategiojn, kiuj ofte efikas en certaj situacioj, kvankam ili eble ne garantias la optimuman solvon.
Ekzemple, ni konsideru heŭristiko por trovi parkejon en plenplena areo. Anstataŭ skrupule analizi ĉiun disponeblan lokon, vi povus fidi je la heŭristiko serĉi parkumitajn aŭtojn kun siaj motoroj funkciante.
Ĉi tiu heŭristiko supozas, ke ĉi tiuj aŭtoj estas forironta, pliigante la ŝancojn trovi disponeblan lokon.
50. Natura Lingva Modelado
Naturlingva modeligado, en simplaj esprimoj, estas la procezo de trejnado de komputilmodeloj por kompreni kaj generi homan lingvon en maniero kiel kiu estas simila al kiel homoj komunikas. Ĝi implikas instrui komputilojn prilabori, interpreti kaj generi tekston en natura kaj signifoplena maniero.
La celo de naturlingva modeligado estas ebligi komputilojn kompreni kaj generi homan lingvon en maniero kiel kiu estas flua, kohera, kaj kuntekste signifa.
Ĝi implikas trejnadon de modeloj pri vastaj kvantoj de tekstaj datumoj, kiel libroj, artikoloj aŭ konversacioj, por lerni la ŝablonojn, strukturojn kaj semantikon de lingvo.
Post kiam trejnitaj, ĉi tiuj modeloj povas plenumi diversajn lingvajn taskojn, kiel lingvan tradukadon, tekstan resumon, demandojn respondantajn, babilbotinteragojn kaj pli.
Ili povas kompreni la signifon kaj kuntekston de frazoj, ĉerpi koncernajn informojn kaj generi tekston gramatike ĝustan kaj koheran.





Lasi Respondon