Es ist eine entscheidende und erstrebenswerte Aufgabe in Computer Vision und Grafik, kreative Porträtfilme auf höchstem Niveau zu produzieren.
Obwohl mehrere effektive Modelle zur Toonifizierung von Porträtbildern basierend auf dem leistungsstarken StyleGAN vorgeschlagen wurden, haben diese bildorientierten Techniken klare Nachteile, wenn sie mit Videos verwendet werden, wie z , und zeitliche Inkonsistenz.
Ein revolutionäres VToonify-Framework wird verwendet, um die schwierige kontrollierte Übertragung von hochauflösenden Hochformat-Videostilen zu bewältigen.
Wir werden in diesem Artikel die neueste Studie zu VToonify untersuchen, einschließlich ihrer Funktionalität, Nachteile und anderer Faktoren.
Was ist Vtoonify?
Das VToonify-Framework ermöglicht eine anpassbare Übertragung im Hochformat-Videostil mit hoher Auflösung.
VToonify verwendet die Ebenen mit mittlerer und hoher Auflösung von StyleGAN, um qualitativ hochwertige künstlerische Porträts zu erstellen, die auf mehrskaligen Inhaltsmerkmalen basieren, die von einem Encoder abgerufen werden, um Framedetails beizubehalten.
Die resultierende vollständig gefaltete Architektur verwendet nicht ausgerichtete Gesichter in Filmen mit variabler Größe als Eingabe, was zu Regionen mit ganzen Gesichtern mit realistischen Bewegungen in der Ausgabe führt.

Dieses Framework ist mit aktuellen StyleGAN-basierten Bild-Toonifizierungsmodellen kompatibel, sodass sie auf Video-Toonifizierung erweitert werden können, und erbt attraktive Eigenschaften wie anpassbare Farb- und Intensitätsanpassungen.
Dieser Studie führt zwei Instanziierungen von VToonify basierend auf Toonify und DualStyleGAN für die sammlungsbasierte bzw. exemplarbasierte Hochformat-Videostilübertragung ein.
Umfangreiche experimentelle Ergebnisse zeigen, dass das vorgeschlagene VToonify-Framework bestehende Ansätze bei der Erstellung hochwertiger, zeitlich kohärenter künstlerischer Porträtfilme mit variablen Stilparametern übertrifft.
Forscher liefern die Google Colab-Notizbuch, damit Sie sich die Hände schmutzig machen können.
Wie funktioniert es?
Um eine einstellbare Übertragung des hochauflösenden Hochformat-Videostils zu erreichen, kombiniert VToonify die Vorteile des Bildübersetzungs-Frameworks mit dem StyleGAN-basierten Framework.
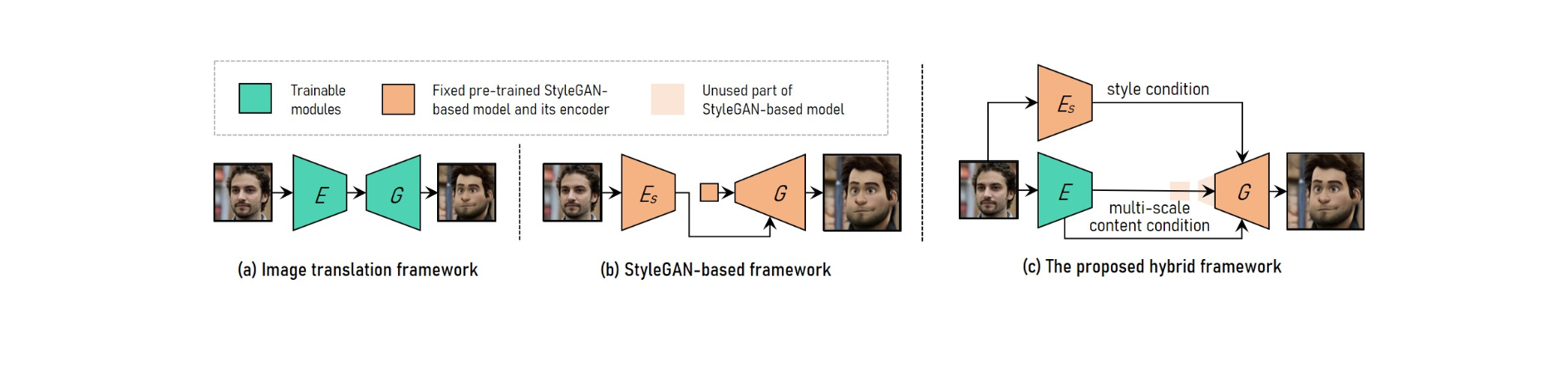
Um sich unterschiedlichen Eingabegrößen anzupassen, verwendet das Bildübersetzungssystem vollständig konvolutionelle Netzwerke. Das Training von Grund auf hingegen macht eine hochauflösende und kontrollierte Stilübertragung unmöglich.
Das vortrainierte StyleGAN-Modell wird im StyleGAN-basierten Framework für eine hochauflösende und kontrollierte Stilübertragung verwendet, obwohl es auf feste Bildgröße und Detailverluste beschränkt ist.
StyleGAN wird im Hybrid-Framework modifiziert, indem seine Eingabefunktion mit fester Größe und Schichten mit niedriger Auflösung gelöscht werden, was zu einer vollständig konvolutionellen Encoder-Generator-Architektur führt, die der des Bildübersetzungs-Frameworks ähnelt.
Um Frame-Details beizubehalten, trainieren Sie einen Encoder, um Multiskalen-Inhaltseigenschaften des Eingabeframes als zusätzliche Inhaltsanforderung an den Generator zu extrahieren. Vtoonify erbt die Stilsteuerungsflexibilität des StyleGAN-Modells, indem es in den Generator eingefügt wird, um sowohl seine Daten als auch sein Modell zu destillieren.
Einschränkungen von StyleGAN und vorgeschlagenem Vtoonify
Künstlerische Porträts sind in unserem täglichen Leben sowie in kreativen Unternehmen wie Kunst, Social Media Avatare, Filme, Unterhaltungswerbung und so weiter.
Mit der Entwicklung von tiefe Lernen -Technologie ist es jetzt möglich, hochwertige künstlerische Porträts aus echten Gesichtsfotos mit automatischer Porträtstilübertragung zu erstellen.
Es gibt eine Vielzahl erfolgreicher Wege für die bildbasierte Stilübertragung, von denen viele für Anfänger in Form von mobilen Anwendungen leicht zugänglich sind. Videomaterial hat sich in den letzten Jahren schnell zu einem festen Bestandteil unserer Social-Media-Feeds entwickelt.
Der Aufstieg von Social Media und ephemeren Filmen hat die Nachfrage nach innovativer Videobearbeitung, wie z.
Vorhandene bildorientierte Techniken haben erhebliche Nachteile, wenn sie auf Filme angewendet werden, was ihre Nützlichkeit bei der automatischen Hochformat-Videostilisierung einschränkt.
StyleGAN ist ein gemeinsames Rückgrat für die Entwicklung eines Transfermodells für Porträtbilder, da es in der Lage ist, qualitativ hochwertige Gesichter mit anpassbarem Stilmanagement zu erstellen.
Ein StyleGAN-basiertes System (auch bekannt als Picture Toonification) kodiert ein echtes Gesicht in den latenten StyleGAN-Raum und wendet dann den resultierenden Stilcode auf ein anderes StyleGAN an, das auf dem künstlerischen Porträtdatensatz abgestimmt ist, um eine stilisierte Version zu erstellen.
StyleGAN erstellt Bilder mit ausgerichteten Gesichtern und in einer festen Größe, was dynamische Gesichter in realem Filmmaterial nicht bevorzugt. Das Zuschneiden und Ausrichten von Gesichtern im Video führt manchmal zu einem partiellen Gesicht und ungeschickten Gesten. Forscher nennen dieses Problem StyleGANs „festgelegte Erntebeschränkung“.
Für nicht ausgerichtete Flächen wurde StyleGAN3 vorgeschlagen; Es unterstützt jedoch nur eine festgelegte Bildgröße.
Darüber hinaus hat eine kürzlich durchgeführte Studie herausgefunden, dass das Kodieren nicht ausgerichteter Gesichter eine größere Herausforderung darstellt als ausgerichtete Gesichter. Eine falsche Gesichtscodierung ist schädlich für die Übertragung des Porträtstils und führt zu Problemen wie Identitätsänderungen und fehlenden Komponenten in den rekonstruierten und gestylten Rahmen.
Wie bereits erwähnt, muss eine effiziente Technik für die Übertragung im Hochformat-Videostil die folgenden Probleme lösen:
- Um realistische Bewegungen beizubehalten, muss der Ansatz in der Lage sein, mit nicht ausgerichteten Gesichtern und unterschiedlichen Videogrößen umzugehen. Eine große Videogröße oder ein weiter Blickwinkel können mehr Informationen erfassen, während verhindert wird, dass sich das Gesicht aus dem Rahmen bewegt.
- Um mit den heute weit verbreiteten HD-Gadgets konkurrieren zu können, ist hochauflösendes Video erforderlich.
- Benutzern sollte eine flexible Stilsteuerung angeboten werden, damit sie ihre Wahl ändern und auswählen können, wenn sie ein realistisches Benutzerinteraktionssystem entwickeln.
Zu diesem Zweck schlagen Forscher VToonify vor, ein neuartiges Hybrid-Framework für die Video-Toonifizierung. Um die feste Zuschneidebeschränkung zu überwinden, untersuchen die Forscher zunächst die Übersetzungsäquivarianz in StyleGAN.
VToonify kombiniert die Vorteile der StyleGAN-basierten Architektur und des Bildübersetzungs-Frameworks, um eine einstellbare hochauflösende Videostilübertragung im Hochformat zu erreichen.
Nachfolgend die wichtigsten Beiträge:
- Forscher untersuchen StyleGANs Fixed-Crop-Constraint und schlagen eine Lösung vor, die auf Übersetzungsäquivarianz basiert.
- Forscher präsentieren ein einzigartiges, vollständig konvolutionelles VToonify-Framework für die kontrollierte Übertragung von hochauflösenden Videoformaten im Hochformat, das nicht ausgerichtete Gesichter und unterschiedliche Videogrößen unterstützt.
- Die Forscher konstruieren VToonify auf den Backbones von Toonify und DualStyleGAN und verdichten die Backbones sowohl in Bezug auf Daten als auch auf das Modell, um eine sammlungsbasierte und exemplarbasierte Übertragung des Hochformat-Videostils zu ermöglichen.
Vergleich von Vtoonify mit anderen hochmodernen Modellen
Toonifizieren
Es dient als Grundlage für die kollektionsbasierte Stilübertragung auf ausgerichteten Flächen mit StyleGAN. Um die Stilcodes abzurufen, müssen die Forscher Gesichter ausrichten und 256256 Fotos für PSP zuschneiden. Toonify wird verwendet, um ein stilisiertes Ergebnis mit 1024*1024 Stilcodes zu generieren.
Schließlich richten sie das Ergebnis im Video wieder an seiner ursprünglichen Position aus. Der unstilisierte Bereich wurde auf Schwarz gesetzt.

DualStyleGAN
Es ist ein Backbone für den exemplarbasierten Stiltransfer auf Basis von StyleGAN. Sie verwenden dieselben Vor- und Nachverarbeitungstechniken für Daten wie Toonify.
Pix2pixHD
Es ist ein Bild-zu-Bild-Übersetzungsmodell, das häufig verwendet wird, um vortrainierte Modelle für die hochauflösende Bearbeitung zu verdichten. Es wird mit gepaarten Daten trainiert.
Forscher verwenden pix2pixHD als zusätzliche Instanzkarteneingaben, da es extrahierte Parsing-Karten verwendet.
Bewegung erster Ordnung
FOM ist ein typisches Bildanimationsmodell. Es wurde mit 256256 Bildern trainiert und schneidet bei anderen Bildgrößen schlecht ab. Als Konsequenz skalieren die Forscher zunächst die Videoframes auf 256*256 für die FOM-to-Animation und skalieren dann die Ergebnisse auf ihre ursprüngliche Größe.
Für einen fairen Vergleich verwendet FOM den ersten stilisierten Rahmen seines Ansatzes als Referenzstilbild.
DaGAN
Es ist ein 3D-Gesichtsanimationsmodell. Sie verwenden die gleichen Datenvorbereitungs- und Nachbearbeitungsmethoden wie FOM.

Vorteile
- Es kann in den Bereichen Kunst, Social-Media-Avatare, Filme, Unterhaltungswerbung usw. eingesetzt werden.
- Vtoonify kann auch im Metaverse verwendet werden.
Einschränkungen
- Diese Methodik extrahiert sowohl die Daten als auch das Modell aus den StyleGAN-basierten Backbones, was zu Daten- und Modellverzerrungen führt.
- Die Artefakte werden hauptsächlich durch Größenunterschiede zwischen dem stilisierten Gesichtsbereich und den anderen Abschnitten verursacht.
- Diese Strategie ist weniger erfolgreich, wenn es um Dinge in der Gesichtsregion geht.
Zusammenfassung
Schließlich ist VToonify ein Framework für stilgesteuerte hochauflösende Video-Toonifizierung.
Dieses Framework erzielt eine hervorragende Leistung bei der Handhabung von Videos und ermöglicht eine umfassende Kontrolle über den strukturellen Stil, den Farbstil und den Stilgrad, indem es StyleGAN-basierte Bildtonifizierungsmodelle in Bezug auf beide verdichtet synthetische Daten und Netzwerkstrukturen.





Hinterlassen Sie uns einen Kommentar