Neurales Rendering ist eine aufkommende Technik im Deep Learning, die darauf abzielt, die klassische Pipeline von Computergrafiken mit neuronalen Netzen zu erweitern.
Ein neuronaler Rendering-Algorithmus erfordert einen Satz von Bildern, die verschiedene Winkel derselben Szene darstellen. Diese Bilder werden dann in ein neuronales Netzwerk eingespeist, um ein Modell zu erstellen, das neue Winkel derselben Szene ausgeben kann.
Die Brillanz hinter dem neuronalen Rendering liegt darin, wie es detaillierte fotorealistische Szenen genau nachbilden kann, ohne sich auf klassische Methoden verlassen zu müssen, die möglicherweise rechenintensiver sind.
Bevor wir uns mit der Funktionsweise des neuronalen Renderings befassen, gehen wir die Grundlagen des klassischen Renderings durch.
Was ist klassisches Rendering?
Lassen Sie uns zunächst die typischen Methoden verstehen, die beim klassischen Rendering verwendet werden.
Klassisches Rendering bezieht sich auf eine Reihe von Techniken, die verwendet werden, um ein 2D-Bild einer dreidimensionalen Szene zu erstellen. Das auch als Bildsynthese bezeichnete klassische Rendering verwendet verschiedene Algorithmen, um zu simulieren, wie Licht mit verschiedenen Arten von Objekten interagiert.
Beispielsweise erfordert das Rendern eines massiven Ziegels einen bestimmten Satz von Algorithmen, um die Position des Schattens zu bestimmen oder wie gut beide Seiten der Wand beleuchtet sind. Ebenso erfordern Objekte, die Licht reflektieren oder brechen, wie ein Spiegel, ein glänzendes Objekt oder ein Gewässer, ebenfalls ihre eigenen Techniken.

Beim klassischen Rendering wird jedes Asset durch ein Polygonnetz dargestellt. Ein Shader-Programm verwendet dann das Polygon als Eingabe, um zu bestimmen, wie das Objekt bei der angegebenen Beleuchtung und dem angegebenen Winkel aussehen wird.
Realistisches Rendering erfordert viel mehr Rechenleistung, da unsere Assets am Ende Millionen von Polygonen als Eingabe verwenden. Das Rendern der computergenerierten Ausgabe, die in Hollywood-Blockbustern üblich ist, dauert normalerweise Wochen oder sogar Monate und kann Millionen von Dollar kosten.
Der Raytracing-Ansatz ist besonders kostspielig, weil jedes Pixel im endgültigen Bild eine Berechnung des Lichtwegs von der Lichtquelle zum Objekt und zur Kamera erfordert.

Fortschritte in der Hardware haben das Rendern von Grafiken für Benutzer viel zugänglicher gemacht. Zum Beispiel viele der neuesten Videospiele erlauben Raytracing-Effekte wie fotorealistische Reflexionen und Schatten, solange ihre Hardware der Aufgabe gewachsen ist.
Die neuesten GPUs (Graphic Processing Units) wurden speziell entwickelt, um die CPU bei der Bewältigung der hochkomplexen Berechnungen zu unterstützen, die zum Rendern fotorealistischer Grafiken erforderlich sind.
Der Aufstieg des neuronalen Renderings
Neuronales Rendering versucht, das Rendering-Problem auf andere Weise anzugehen. Anstatt Algorithmen zu verwenden, um zu simulieren, wie Licht mit Objekten interagiert, was wäre, wenn wir ein Modell erstellen würden, das lernt, wie eine Szene aus einem bestimmten Winkel aussehen sollte?
Sie können es sich als Abkürzung zum Erstellen fotorealistischer Szenen vorstellen. Beim neuronalen Rendering müssen wir nicht berechnen, wie Licht mit einem Objekt interagiert, wir brauchen nur genügend Trainingsdaten.
Dieser Ansatz ermöglicht es Forschern, hochwertige Renderings komplexer Szenen zu erstellen, ohne dass sie eine Leistung erbringen müssen
Was sind Neuronale Felder?
Wie bereits erwähnt, verwenden die meisten 3D-Renderings Polygonnetze, um Daten über die Form und Textur jedes Objekts zu speichern.
Neuronale Felder werden jedoch als alternative Methode zur Darstellung dreidimensionaler Objekte immer beliebter. Im Gegensatz zu Polygonnetzen sind neuronale Felder differenzierbar und kontinuierlich.
Was meinen wir, wenn wir sagen, dass neuronale Felder differenzierbar sind?
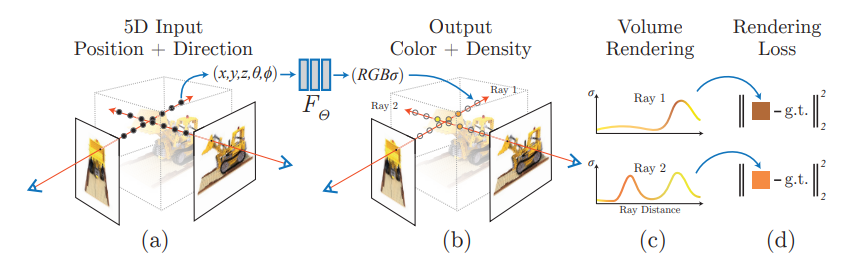
Eine 2D-Ausgabe aus einem neuronalen Feld kann nun so trainiert werden, dass sie fotorealistisch wird, indem einfach die Gewichte des neuronalen Netzwerks angepasst werden.
Mit neuronalen Feldern müssen wir die Physik des Lichts nicht mehr simulieren, um eine Szene zu rendern. Das Wissen darüber, wie das endgültige Rendering beleuchtet wird, ist jetzt implizit in den Gewichtungen unserer gespeichert neuronale Netzwerk.
So können wir relativ schnell aus einer Handvoll Fotos oder Videomaterial neuartige Bilder und Videos erstellen.
Wie trainiere ich ein neuronales Feld?
Nachdem wir nun die Grundlagen der Funktionsweise eines neuronalen Feldes kennen, werfen wir einen Blick darauf, wie Forscher ein neuronales Strahlungsfeld trainieren können Nerf.
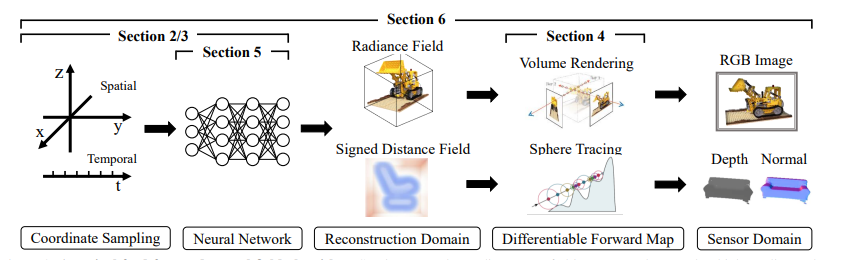
Zuerst müssen wir die zufälligen Koordinaten einer Szene abtasten und sie in ein neuronales Netzwerk einspeisen. Dieses Netzwerk wird dann in der Lage sein, Feldmengen zu produzieren.
Die erzeugten Feldgrößen werden als Proben aus dem gewünschten Rekonstruktionsbereich der Szene angesehen, die wir erstellen möchten.
Wir müssen dann die Rekonstruktion auf tatsächliche 2D-Bilder abbilden. Ein Algorithmus berechnet dann den Rekonstruktionsfehler. Dieser Fehler leitet das neuronale Netzwerk an, seine Fähigkeit zur Rekonstruktion der Szene zu optimieren.
Anwendungen des neuronalen Renderings
Novel-View-Synthese
Neuartige Ansichtssynthese bezieht sich auf die Aufgabe, Kameraperspektiven aus neuen Blickwinkeln unter Verwendung von Daten aus einer begrenzten Anzahl von Perspektiven zu erstellen.
Neuronale Rendering-Techniken versuchen, die relative Position der Kamera für jedes Bild im Datensatz zu erraten und diese Daten in ein neuronales Netzwerk einzuspeisen.
Das neuronale Netzwerk erstellt dann eine 3D-Darstellung der Szene, wobei jeder Punkt im 3D-Raum eine zugeordnete Farbe und Dichte hat.

Eine neue Implementierung von NeRFs in Google Street View verwendet eine neuartige Ansichtssynthese, um es Benutzern zu ermöglichen, reale Orte zu erkunden, als ob sie eine Kamera steuern würden, die ein Video aufnimmt. Dies ermöglicht es Touristen, Reiseziele auf immersive Weise zu erkunden, bevor sie sich entscheiden, zu einem bestimmten Ort zu reisen.
Fotorealistische Avatare
Fortgeschrittene Techniken im neuronalen Rendering können auch den Weg für realistischere digitale Avatare ebnen. Diese Avatare können dann für verschiedene Rollen wie virtuelle Assistenten oder Kundendienst verwendet werden, oder als Möglichkeit für Benutzer, ihr Bild in ein einzufügen Telespiel oder simuliertes Rendern.
![]()
Zum Beispiel kann ein Krepppapier veröffentlicht im März 2023 schlägt die Verwendung neuronaler Rendering-Techniken vor, um nach einigen Minuten Videomaterial einen fotorealistischen Avatar zu erstellen.
Zusammenfassung
Neuronales Rendering ist ein spannendes Studiengebiet, das das Potenzial hat, die gesamte Computergrafikbranche zu verändern.
Die Technologie könnte die Eintrittsbarriere für die Erstellung von 3D-Assets senken. Visual-Effects-Teams müssen nicht länger tagelang warten, um ein paar Minuten fotorealistische Grafiken zu rendern.
Die Kombination der Technologie mit bestehenden VR- und AR-Anwendungen kann es Entwicklern auch ermöglichen, immersivere Erfahrungen zu schaffen.
Was ist Ihrer Meinung nach das wahre Potenzial für neuronales Rendering?





Hinterlassen Sie uns einen Kommentar