Web Scraping ist in der heutigen datengesteuerten Gesellschaft zu einer entscheidenden Methode geworden, um aufschlussreiche Daten von Internetplattformen zu erhalten.
Als äußerst beliebte Social-Media-Seite bietet Instagram jede Menge nutzergeneriertes Material. Und diese generierten Daten können für Marketing, Forschung und andere Zwecke verwendet werden.
Dank der funktionsreichen Instagram-Scraper von Bright Data, einem führenden Unternehmen, können Benutzer ganz einfach und effektiv Daten von Instagram extrahieren Bahnkratzen Werkzeug. In diesem Beitrag geben wir eine ausführliche Schritt-für-Schritt-Anleitung für den Instagram-Scraping-Prozess.
Sehen wir uns also die Schritte an, wie wir Daten von Instagram extrahieren können.
Instagram Scraper von Bright Data verstehen
Mit Hilfe von zwei universellen Web-Scrapern und einem vorkompilierten Datensatz bietet Bright Data eine Vielzahl von Instagram-Scraping-Diensten. Diese Technologien bieten Vielseitigkeit bei der Datenextraktion und passen sich verschiedenen Anforderungen an.
Sehen wir uns jede dieser Optionen genauer an:
a. Scraping-Browser
Die innovative Technologie namens Scraping Browser wurde entwickelt, um die Anforderungen von Daten-Scraping-Projekten zu erfüllen. Es bietet alles, was Sie zum Scraping in großem Maßstab in einem einzigen Browser benötigen. Er zeichnet sich durch seine integrierte Automatisierung zur Website-Entsperrung aus und ist damit der einzige Browser seiner Art auf der ganzen Welt.
Scraping Browser bietet Benutzern Zugriff auf robuste Funktionen, die über automatisierte und Headless-Browser hinausgehen, und ermöglicht es ihnen, selbst die schwierigsten Skripte und Website-Barrieren für die Bot-Erkennung zu überwinden.
Das Daten-Scraping ist aufgrund seiner automatischen Anpassungsfunktionen, die neue Blöcke, CAPTCHA-Lösungen, Fingerabdrücke und Wiederholungsversuche problemlos verwalten und als echter Benutzer erscheinen, effektiver und problemloser.
Einsatz von KI, um Bot-Erkennungssysteme auszutricksen
Durch den Einsatz modernster KI-Technologie kann Scraping Browser Bot-Erkennungssysteme überlisten und sich kontinuierlich an deren wechselnde Strategien anpassen. Um Webseiten besser zu entsperren, lernt Scraping Browser von den Versuchen dieser Systeme, Scraping-Versuche zu erkennen und zu blockieren, und passt sein Verhalten entsprechend an.
Es übertrifft die Effizienz herkömmlicher Proxys, indem es das Verhalten eines Browsers nachahmt, der von einem echten Benutzer verwendet wird. Dadurch können sich Kunden auf ihre Ziele beim Data Scraping konzentrieren, ohne sich mit den Schwierigkeiten und Kosten laufender Bot-Erkennungsverfahren auseinandersetzen zu müssen.
b. Web-Scraper-IDE
Web Scraper IDE ist ein robustes Web-Scraping-Tool, das für Entwickler entwickelt wurde und komplexe Scraping-Aufgaben bewältigen kann. Es verkürzt die Entwicklungszeit erheblich und bietet gleichzeitig unbegrenzte Skalierbarkeit dank seiner vollständig gehosteten Lösung und vorgefertigten Scraping-Funktionen. Die Anwendung ermöglicht die schnelle und skalierbare Erstellung von Online-Scrapern, indem sie Codevorlagen und vorgefertigte JavaScript-Funktionen von beliebten Websites bereitstellt.
Alles, was für ein erfolgreiches Web Scraping erforderlich ist, wird von der Web Scraper-IDE bereitgestellt. Es handelt sich um eine Komplettlösung für die Online-Datenextraktion, da die Integrationsoptionen es Kunden ermöglichen, Crawls zu planen oder sie über die API zu starten und mit den Hauptspeichersystemen zu verknüpfen.
Wie benutzt man es? - Lernprogramm
Navigieren Sie zunächst zum Benutzer-Dashboard auf der Website.

Beginnen wir mit unseren Schritten zum Scrapen von Instagram.
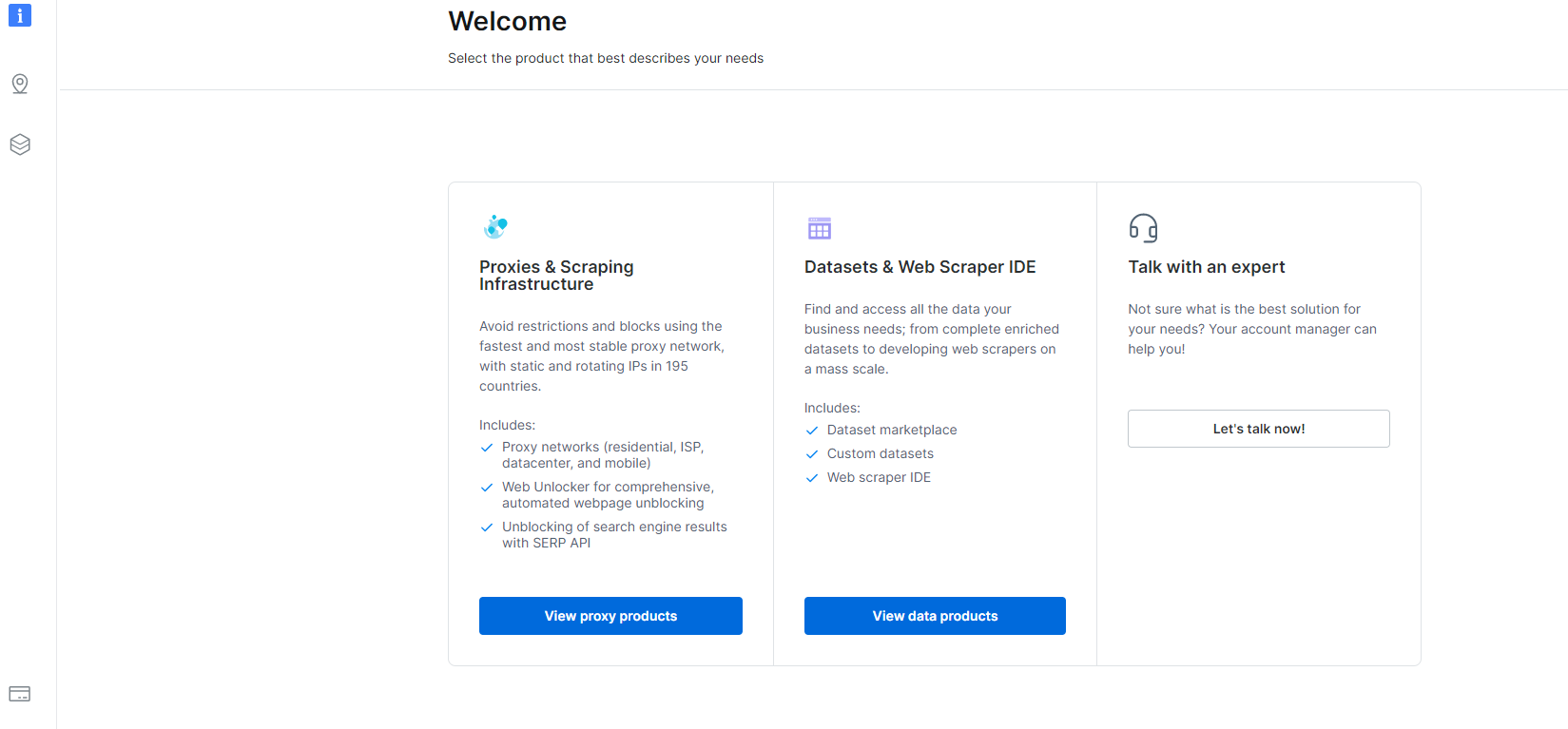
1- Navigieren Sie zu Dashboard und klicken Sie auf den Abschnitt „Datasets & Web Scraper IDE“.
2- Sobald Sie dort sind, klicken Sie auf „Meine Schaber“.
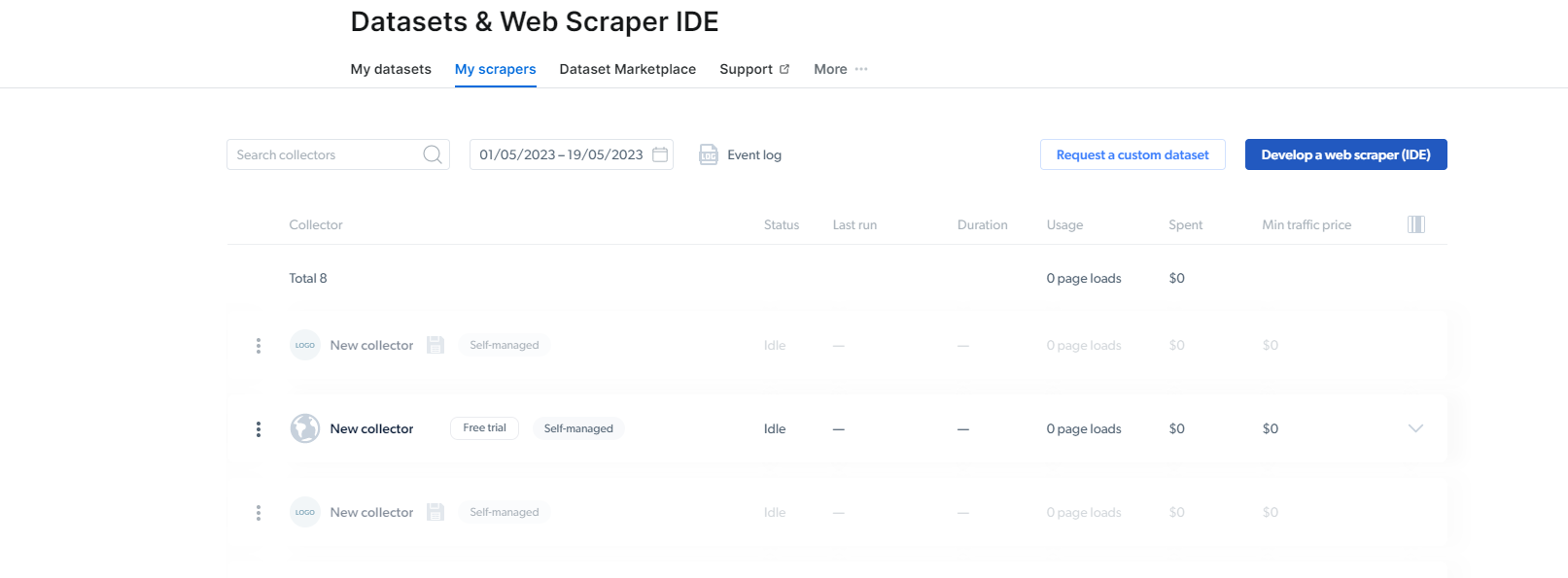
Hier müssen Sie auf „Web Scraper (IDE) entwickeln“ klicken. Hier erstellen wir unseren Scraper für Instagram.
3-Jetzt müssen wir einen neuen Web-Scraper entwickeln. Nur für dieses Beispiel habe ich mich für das Scrapen des „NASA“-Kontos entschieden. Dies dient lediglich diesem Beispiel.
Mein Code wird also so aussehen:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Sie müssen oben rechts auf die Schaltfläche „Play“ klicken, um diesen Code auszuführen.
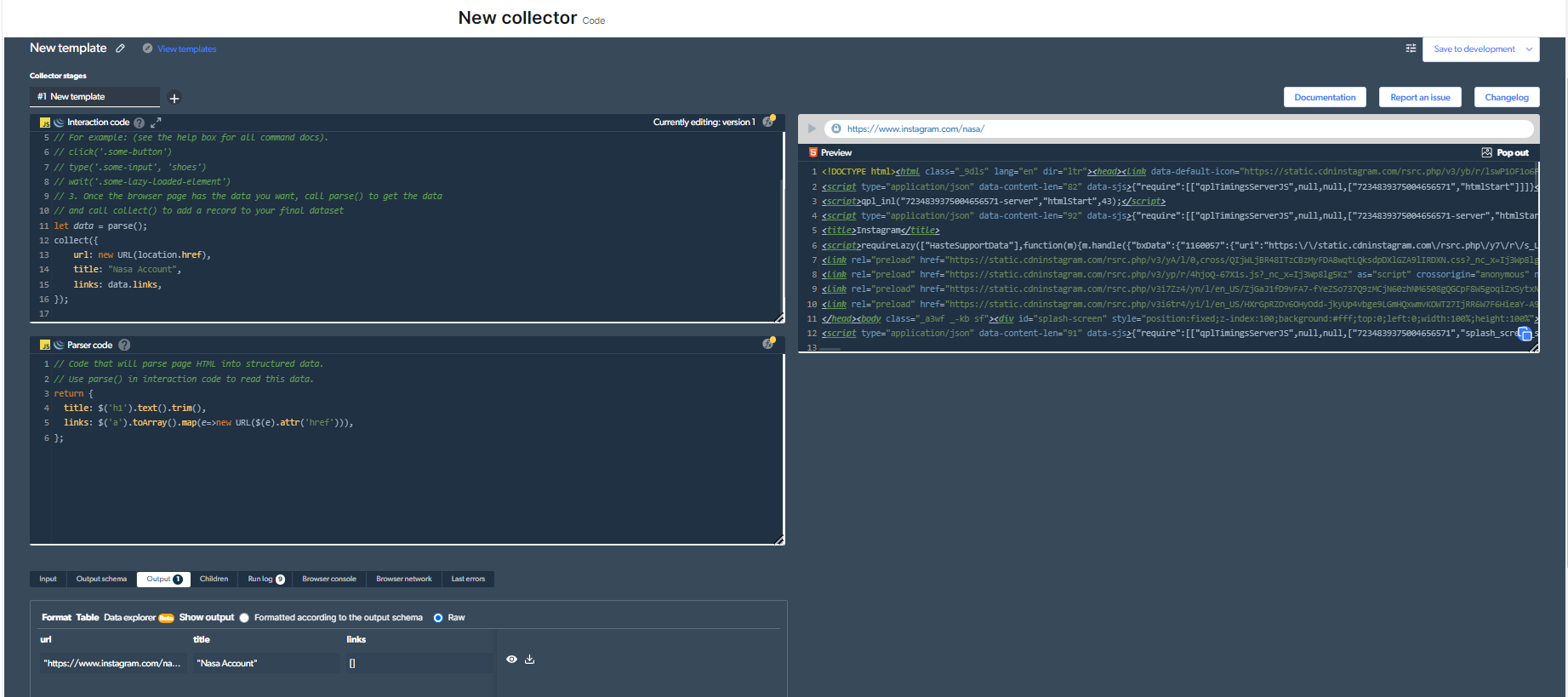
4- Jetzt erhalten wir eine Ausgabe.
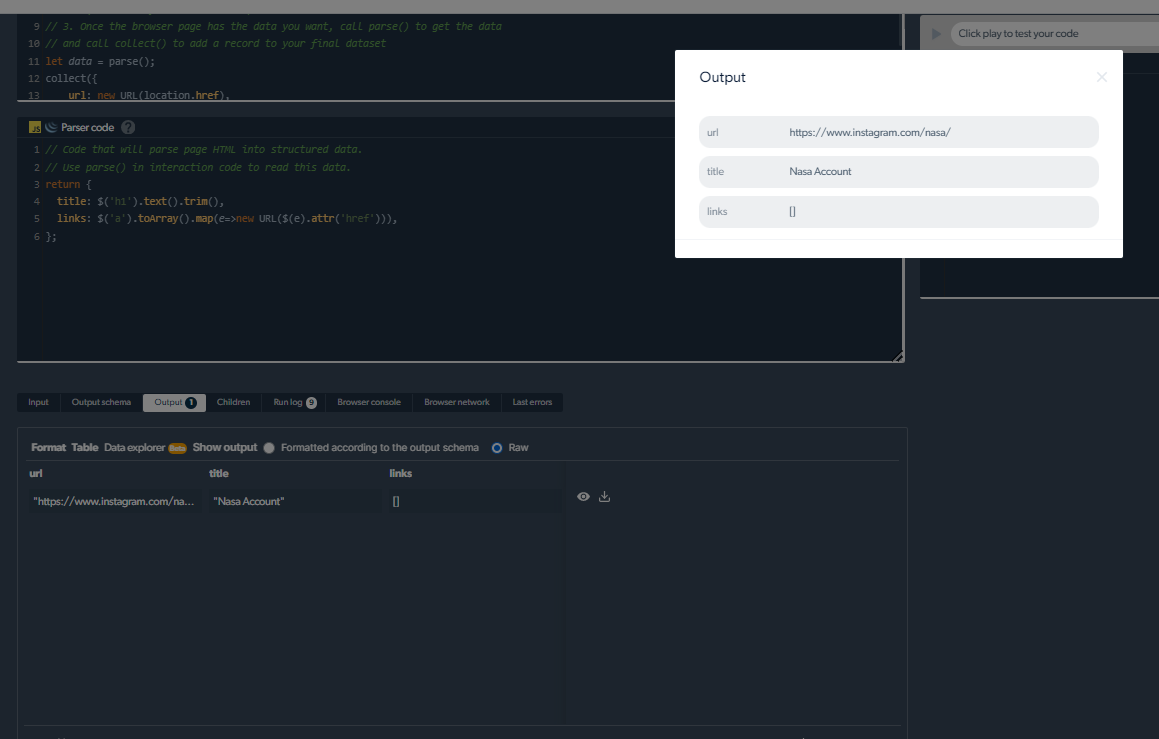
Umgang mit Scraping-Problemen
Instagram-Beiträge mit der Schaltfläche „Mehr anzeigen“ könnten für Scraper schwierig zu erfassen sein. Allerdings sind Instagram-Scraper von Bright Data darauf ausgelegt, diese Komplexität erfolgreich zu bewältigen. Diese Scraper verfügen über modernste Fähigkeiten, um die Paginierung und das Laden zusätzlicher Schaltflächen zu durchlaufen.
Die Instagram-Scraper von Bright Data bewältigen diese Schwierigkeiten effektiv und ermöglichen eine gründliche Datenextraktion, sodass Sie die gesamte Sammlung von Informationen sammeln können, die Sie für Ihre Analyse oder Studie benötigen.
Mit diesen Scraping-Tools können Sie die Herausforderungen umgehen, die sich aus der dynamischen Natur von Instagram-Posts ergeben.
c. Vorab erfasster Datensatz
Bright Data versteht, dass nicht jeder seinen Scraper betreiben möchte. Sie stellen einen vorab gesammelten Datensatz für Instagram bereit, um solche Verbraucher anzusprechen.
Dieser Datensatz bietet eine Fülle nützlicher Informationen, wie Follower, Profile, Beiträge und mehr.
Bright Data bietet Anpassungsoptionen, um den Datensatz an Ihre Bedürfnisse anzupassen, unabhängig davon, ob Sie einen gesamten Datensatz oder eine Teilmenge spezialisierter Daten wünschen. Dieser Ansatz vermeidet die Erstellung und Verwaltung eines Scrapers und liefert Ihnen sofort einsatzbereite Daten für Analysen und Erkenntnisse.
Schauen wir uns nun die Infrastruktur an, die diese Tools so effektiv macht: die Proxy-Infrastruktur und Web Unlocker.
Entfesseln Sie die Macht der Proxys
Die richtigen Proxies ist beim Web Scraping von entscheidender Bedeutung, um sicherzustellen, dass Ihre Aktionen unbemerkt bleiben.
Bright Data bietet eine große Auswahl an Proxy-Dienste die auf Ihre Anforderungen zugeschnitten sind. Sie können auswählen Wohnimmobilien, die mehr als 72 Millionen IPs anbieten, die von Real-Peer-Geräten in 195 Ländern rotiert werden.
Sie können sich für ISP-Proxys entscheiden, die über 700,000 echte Heim-IPs weltweit für die langfristige Nutzung anbieten; Rechenzentrums-Proxys mit über 770,000 gemeinsam genutzten IPs von jedem Standort aus; und Mobile Proxys, die mit über 3 IPs das größte echte Peer-4G/7,000,000G-Mobilfunknetz bilden.
Mithilfe dieser Proxys kann man problemlos Daten sammeln, während man sich an zahlreichen Orten als autorisierter Benutzer ausgibt.

Proxy-Manager: Vereinfachen Sie die Proxy-Verwaltung
Die Verwaltung mehrerer Proxys kann schwierig sein, aber Proxy Manager macht es einfach.
Mit dieser Open-Source-Schnittstelle können Sie alle Ihre Proxys von einer einzigen Plattform aus verwalten. Verabschieden Sie sich vom manuellen Festlegen und Wechseln von Proxys. Proxy Manager vereinfacht den Vorgang und spart Ihnen Zeit und Mühe.
Proxy-Browser-Erweiterung: Ändern Sie Ihren Standort ganz einfach
Müssen Sie Webdaten aus mehreren Regionen sammeln? Sie sind durch unsere Proxy-Browser-Erweiterung geschützt. Sie können Ihren Browserstandort mit einem einzigen Klick ändern, um regionalspezifische Informationen zu erhalten.
Profitieren Sie von der Flexibilität und Einfachheit der Datenerfassung aus mehreren Regionen ohne technische Komplikationen.
Wie funktioniert es? - Lernprogramm
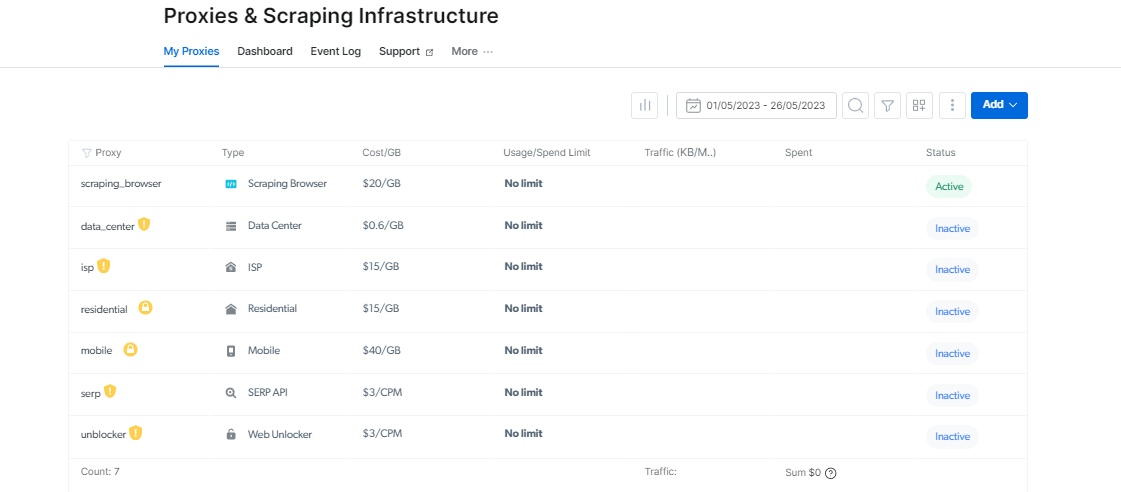
Sie können Ihre Scraping-Browser Anmeldeinformationen auf der Seite „Zugriffsparameter“, die verwendet werden, wenn Sie eine neue Browsersitzung starten.
Schauen Sie sich die Dokumentation und Codebeispiele an, einschließlich eines voll funktionsfähigen Beispielskripts, das sofort verwendet werden kann, oder sehen Sie sich ein kurzes Einführungsvideo an. Zum Beispiel; hier ist ein Python-Code Beispiel für Integration:
Brauchen Sie Hilfe? Für ein Gespräch mit einem der Spezialisten können Sie auf das Chat-Symbol klicken.
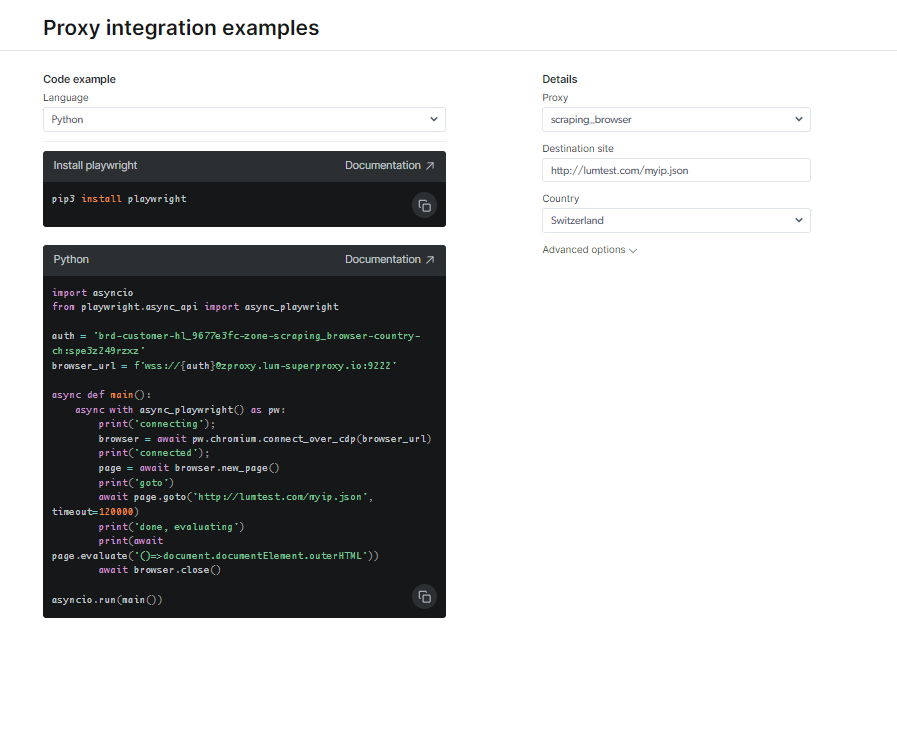
Beachten Sie, dass Sie bei der Verwendung von Scraping Browser die vollständige Kontrolle über die Browsersitzungen haben und alle Vorgänge ausführen können, die von Puppeteer, Playwright oder der direkten Verwendung des Chrome DevTools-Protokolls unterstützt werden.
Website-Entsperrung ohne Blockierungen
Der Scraping-Browser ist so konzipiert, dass er im großen Maßstab und nach Bedarf funktioniert. Sie müssen sich keine Sorgen machen, dass Sie gesperrt werden. Sie können so viele Browsersitzungen starten, wie Sie benötigen.
Diese Kapazität garantiert in Kombination mit der Stärke von Proxys eine kontinuierliche Datenerfassung, sodass Sie die gewünschten Daten effektiv abrufen können.
Die integrierten Entsperrfähigkeiten und das robuste Proxy-Netzwerk des Scraping-Browsers helfen Ihnen, Zeit zu sparen, die Produktivität zu steigern und neue Möglichkeiten zu entdecken.
Sie können die Statistiken auch direkt auf derselben Seite überprüfen.
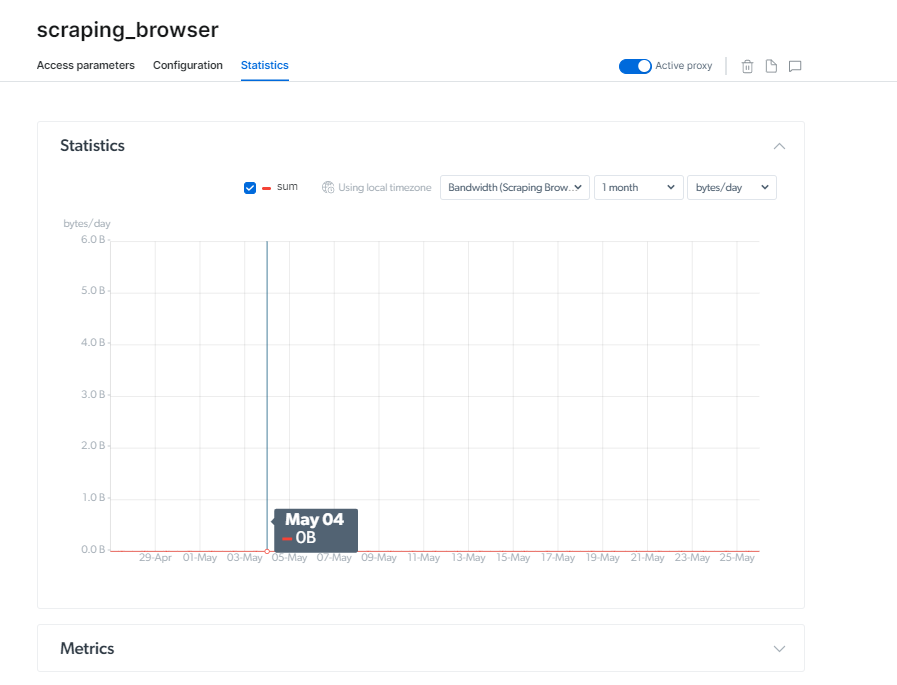
Preise für den Scraping-Browser
Bright Data bietet anpassbare Preisoptionen für eine Vielzahl von Zwecken. Sie können zwischen einem monatlichen oder einem jährlichen Abrechnungszeitraum wählen.
Mit der Option „Pay as You Go“ können Sie ab 20.00 $/GB und 0.1 $/Stunde nur für das bezahlen, was Sie nutzen, ohne dass eine Verpflichtung erforderlich ist.
Der 500-Dollar-Wachstumsplan eignet sich für wachsende Unternehmen mit einer ermäßigten Gebühr von 15.30 Dollar/GB und 0.1 Dollar/Stunde.
Das Business-Paket, Die beliebteste Option ist die, die 1000 US-Dollar kostet. Die Scraping-Browser-API kostet 13.50 US-Dollar pro GB und 0.1 US-Dollar pro Stunde.
Durch die direkte Kontaktaufnahme mit dem Team von Bright Data können Unternehmensanwender von unbegrenzter Skalierung und personalisierten Preisen profitieren. Starten Sie noch heute eine kostenlose Testversion, um das Potenzial des Scraping-Browsers von Bright Data zu entdecken und Ihre Online-Scraping-Bemühungen zu ändern.
Website-Unlocker
Web Unlocker ist ein leistungsstarkes Tool, das entwickelt wurde, um Website-Einschränkungen zu überwinden und eine einfache Datenerfassung zu ermöglichen. Es überwindet mehrere Herausforderungen, darunter Cookies, standortspezifische Browser-Benutzeragenten und Captcha-Lösungen, indem es automatisierte Verfahren nutzt.
Durch die Verwendung der automatischen IP-Adressrotation können Benutzer von Web Unlocker kontinuierlich Zielwebsites scannen und so einen ständigen Zugriff auf wichtige Daten gewährleisten.
Verbesserung der Developer Request Journeys
Mehrere Funktionen machen Web Unlocker bei Entwicklern beliebt. Das Programm optimiert den Datenerfassungsprozess, indem es automatisch die für jede Website benötigten Benutzeragenten identifiziert und so wertvolle Zeit und Ressourcen spart.
Web Unlocker passt sich in Echtzeit an, um eine Erkennung als Reaktion auf die sich ständig ändernden Strategien der Blockierungs-Bots zu vermeiden und so einen kontinuierlichen Zugriff auf die Websites von Interesse zu gewährleisten. Die maschinellen Lernalgorithmen der Plattform können Captchas schnell auflösen, ein häufiges Hindernis für Datenerfassungsinitiativen.

Preise für Web Unlocker
Ab etwa 2.03 US-Dollar pro tausend Anfragen (CPM) bietet Web Unlocker mehrere Preisoptionen, um unterschiedlichen Anforderungen gerecht zu werden. Für den Einstieg steht Benutzern eine 7-tägige kostenlose Testversion zur Verfügung, mit der sie die Funktionen von Web Unlocker testen können, bevor sie sich entscheiden.
Web Unlocker bietet die Anpassungsfähigkeit, um verschiedene Nutzungsmuster zu unterstützen, unabhängig davon, ob Verbraucher einen Pay-as-you-go-Ansatz wünschen oder einen maßgeschneiderten Plan benötigen, der auf ihre besonderen Anforderungen zugeschnitten ist. Darüber hinaus könnten diejenigen, die sich für langfristige Preispläne entscheiden, 32 % sparen.
Vergleich zwischen Web Unlocker und selbstverwalteten Proxys
Web Unlocker bietet zahlreiche sofortige Vorteile gegenüber selbstverwalteten Proxys. Für eine reibungslose Implementierung bietet es eine umfangreiche Integrationstechnik, die Super-Proxy- und Proxy-Manager-Funktionen kombiniert. Benutzer können ihre Datenerfassungsvorgänge effektiv mit einer unendlichen Anzahl gleichzeitiger Verbindungen skalieren.
Web Unlocker ermöglicht die automatische Entsperrung, löst CAPTCHAs und verwaltet erfolgreich Markup-Änderungen auf Zielwebsites.
Die Plattform garantiert eine kontinuierliche und zuverlässige Datenextraktion, indem sie ein Auto-Retry-System implementiert und asynchrone Aufrufe für bestimmte Domänen durchführt. Darüber hinaus sorgt die wachsende Sammlung von HTTP-Header-Anfragen, standortspezifischen Browser-Cookies und simulierten Gadgets von Online Unlocker dafür, dass Benutzer unentdeckt bleiben und gleichzeitig Online-Daten in Echtzeit erfassen können.
Abschließende Gedanken und wichtige Dinge, an die Sie sich erinnern sollten
Schließlich ist es bei der Verwendung von Bright Data für das Instagram-Scraping wichtig, einige wichtige Punkte zu beachten.
Bitte beachten Sie, dass ihre Scraping-Funktionen aus ethischen Gründen auf öffentlich verfügbare Daten beschränkt sind.
Sie sollten stets die Nutzungsbedingungen und Datenschutzrichtlinien von Instagram befolgen. Scraping sollte ethisch und verantwortungsvoll erfolgen, ohne in die Rechte der Nutzer einzugreifen oder gegen Gesetze zu verstoßen.
Zweitens aktualisieren und optimieren Sie Ihre Scraping-Parameter regelmäßig, um die Genauigkeit und Relevanz der abgerufenen Daten sicherzustellen. Die Plattform und die Algorithmen von Instagram können sich ändern. Daher müssen Sie Ihre Scraping-Strategien entsprechend anpassen.
Nutzen Sie schließlich die Hilfe und Ressourcen der Plattform von Bright Data, um den Erfolg Ihrer Instagram-Scraping-Bemühungen zu optimieren. Nutzen Sie deren Dokumentation, Tutorials und Kundenservice, um Ihr Wissen über ihre Scraping-Tools zu verbessern.
Sie können nützliche Erkenntnisse gewinnen, kluge Entscheidungen beeinflussen und Ihre datengesteuerten Initiativen auf der Instagram-Plattform erfolgreich umsetzen, indem Sie diese Best Practices befolgen und die Stärke der Instagram-Scraping-Funktionen von Bright Data nutzen.





Hinterlassen Sie uns einen Kommentar