Inhaltsverzeichnis[Ausblenden][Zeigen]
Unternehmen erfassen mehr Daten als je zuvor, da sie sich zunehmend darauf verlassen, um wichtige Geschäftsentscheidungen zu treffen, Produktangebote zu verbessern und einen besseren Kundenservice zu bieten.
Da die Datenmenge exponentiell erstellt wird, bietet die Cloud mehrere Vorteile für die Datenverarbeitung und -analyse, darunter Skalierbarkeit, Zuverlässigkeit und Verfügbarkeit.
Im Cloud-Ökosystem gibt es auch mehrere Tools und Technologien für die Datenverarbeitung und -analyse. Die beiden am häufigsten verwendeten Arten von Big-Data-Speicherstrukturen sind Data Warehouses und Data Lakes.
Obwohl die Verwendung eines Data Lake weniger attraktiv ist, da Sie das Modell und die Daten nicht abfragen können, solange sie noch relevant sind, ist die Verwendung eines Data Warehouse für die Speicherung von Streaming-Daten verschwenderisch.

WWelche Art von Cloud-Architektur wählen wir?
Sollen wir neuere Konzepte für das Data Lakehouse in Betracht ziehen, oder sollten wir uns mit den Beschränkungen des Warehouses oder der Beschränkungen des Sees begnügen?
Eine neuartige Datenspeicherarchitektur namens „Data Lakehouse“ kombiniert die Anpassungsfähigkeit von Data Lakes mit der Datenverwaltung von Data Warehouses.
Das Verständnis der verschiedenen Big-Data-Speichermethoden ist für den Aufbau einer zuverlässigen Datenspeicher-Pipeline für Business Intelligence (BI), Datenanalysen und andere unerlässlich Maschinelles Lernen (ML) Workloads, abhängig von den Anforderungen Ihres Unternehmens.
In diesem Beitrag werden wir uns Data Warehouse, Data Lake und Data Lakehouse mit ihren Vorteilen, Einschränkungen sowie Vor- und Nachteilen genau ansehen. Lass uns anfangen.
Was ist DataWarehouse?
Ein Data Warehouse ist ein zentralisiertes Datenrepository, das von einer Organisation verwendet wird, um enorme Datenmengen aus vielen Quellen zu speichern. Ein Data Warehouse fungiert als zentrale Quelle für „Datenwahrheit“ eines Unternehmens und ist für die Berichterstellung und Geschäftsanalyse unerlässlich.
In der Regel kombinieren Data Warehouses relationale Datensätze aus mehreren Quellen, z. B. Anwendungs-, Geschäfts- und Transaktionsdaten, um historische Daten zu speichern. Vor dem Laden in das Warehousing-System werden Daten in Data Warehouses transformiert und bereinigt, damit sie als Single Source of Data Truth genutzt werden können.
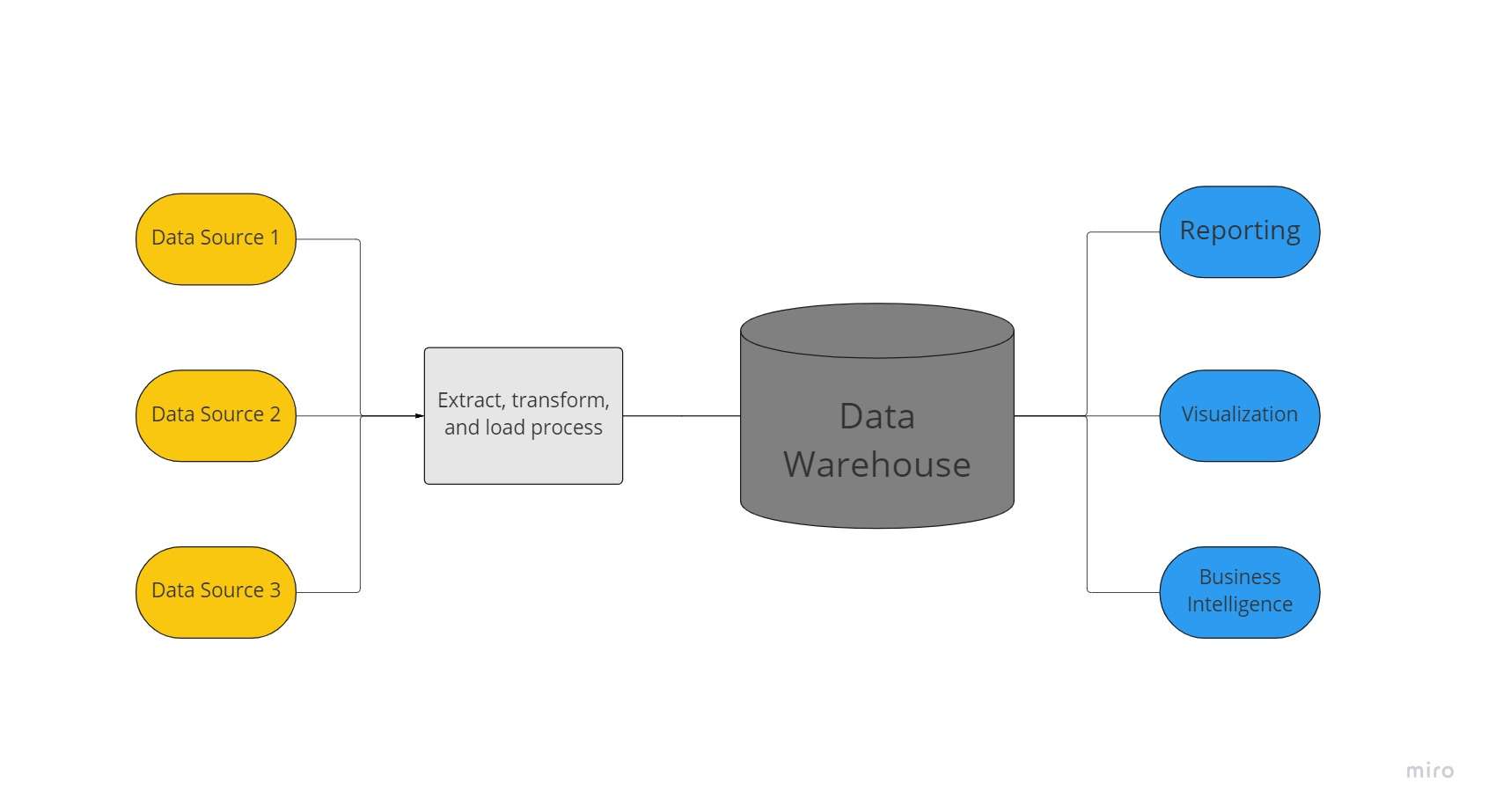
Aufgrund ihrer Fähigkeit, schnell geschäftliche Erkenntnisse aus allen Bereichen des Unternehmens bereitzustellen, investieren Unternehmen in Data Warehouses. Mit der Verwendung von BI-Tools, SQL-Clients und anderen weniger anspruchsvollen (d. h. nicht datenwissenschaftlichen) Analyselösungen, Wirtschaftsanalytiker, Data Engineers und Entscheidungsträger können auf Daten aus Data Warehouses zugreifen.
Es ist teuer, ein Warehouse mit dem ständig wachsenden Datenvolumen zu unterhalten, und ein Data Warehouse kann keine rohen oder unstrukturierten Daten verarbeiten. Darüber hinaus ist es nicht die ideale Option für anspruchsvolle Datenanalysetechniken wie maschinelles Lernen oder prädiktive Modellierung.
Ein Data Warehouse bietet daher schnellere Antworten auf Anfragen und Daten von höherer Qualität. Google Big Query, Amazon Redshift, Azure SQL Data Warehouse und Snowflake sind Cloud-Dienste, die für Data Warehouses verfügbar sind.
Vorteile von Data Warehouse
- Steigerung der Effizienz und Geschwindigkeit von Business-Intelligence- und Datenanalyse-Workloads: Data Warehouses verkürzen die Zeit für die Datenaufbereitung und -analyse. Sie können problemlos mit Datenanalyse- und Business-Intelligence-Tools verknüpft werden, da die Daten aus dem Data Warehouse zuverlässig und konsistent sind. Darüber hinaus sparen Data Warehouses die für die Datenerfassung benötigte Zeit und geben Teams die Möglichkeit, Daten für Berichte, Dashboards und andere Analyseanforderungen zu verwenden.
- Erhöhung der Konsistenz, Qualität und Standardisierung von Daten: Organisationen sammeln Daten aus einer Vielzahl von Quellen, einschließlich Benutzer-, Verkaufs- und Transaktionsdaten. Das Unternehmen kann den Daten für geschäftliche Anforderungen vertrauen, da Data Warehousing Unternehmensdaten in ein einheitliches, standardisiertes Format kompiliert, das als einzige Quelle für Datenwahrheit dienen kann.
- Verbesserung der Entscheidungsfindung im Allgemeinen: Data Warehousing erleichtert eine bessere Entscheidungsfindung, indem es einen zentralen Speicher für aktuelle und alte Daten bietet. Durch die Verarbeitung von Daten in Data Warehouses für präzise Erkenntnisse können Entscheidungsträger Risiken bewerten, Kundenwünsche verstehen und Waren und Dienstleistungen verbessern.
- Bereitstellung besserer Business Intelligence: Data Warehousing schließt die Lücke zwischen massiven Rohdaten, die häufig routinemäßig gesammelt werden, und den kuratierten Daten, die Erkenntnisse liefern. Sie bilden die Grundlage für die Datenspeicherung eines Unternehmens und ermöglichen es ihm, komplizierte Fragen zu seinen Daten zu beantworten und die Antworten zu nutzen, um vertretbare Geschäftsentscheidungen zu treffen.
Einschränkungen von Data Warehouse
- Mangel an Datenflexibilität: Data Warehouses zeichnen sich zwar durch den Umgang mit strukturierten Daten aus, aber halbstrukturierte und unstrukturierte Datenformate wie Log Analytics, Streaming und Social-Media-Daten können für sie eine Herausforderung darstellen. Dies macht die Empfehlung von Data Warehouses für Anwendungsfälle mit maschinellem Lernen und künstliche Intelligenz schwer.
- Teuer in der Installation und Wartung: Die Installation und Wartung von Data Warehouses kann teuer sein. Außerdem ist das Data Warehouse oft nicht statisch; es altert und muss häufig gewartet werden, was teuer ist.
Vorteile
- Daten sind einfach zu finden, abzurufen und abzufragen.
- Solange die Daten bereits sauber sind, ist die SQL-Datenvorbereitung einfach.
Nachteile
- Sie sind gezwungen, nur einen Analyseanbieter zu verwenden.
- Das Analysieren und Speichern von unstrukturierten oder fließenden Daten ist ziemlich kostspielig.
Was ist Data Lake?
Jede Art von Daten wird durch Data Lakes versprochen und ermöglicht. Es ist von Vorteil, Daten auf zugängliche Weise zentral gespeichert und zum Lesen verfügbar zu haben.
Ein Data Lake ist ein zentralisierter, äußerst anpassungsfähiger Speicherplatz, an dem riesige Mengen organisierter und unstrukturierter Daten in ihrer unverarbeiteten, unveränderten und unformatierten Form aufbewahrt werden.
Ein Data Lake verwendet eine flache Architektur und Objekte, die in ihrem unverarbeiteten Zustand gespeichert werden, um Daten zu speichern, im Gegensatz zu Data Warehouses, die relationale Daten speichern, die zuvor „bereinigt“ wurden.
Data Lakes sind im Gegensatz zu Data Warehouses, die Schwierigkeiten haben, Daten in diesem Format zu verarbeiten, anpassungsfähig, zuverlässig und erschwinglich und ermöglichen es Unternehmen, bessere Einblicke in unstrukturierte Daten zu erhalten.
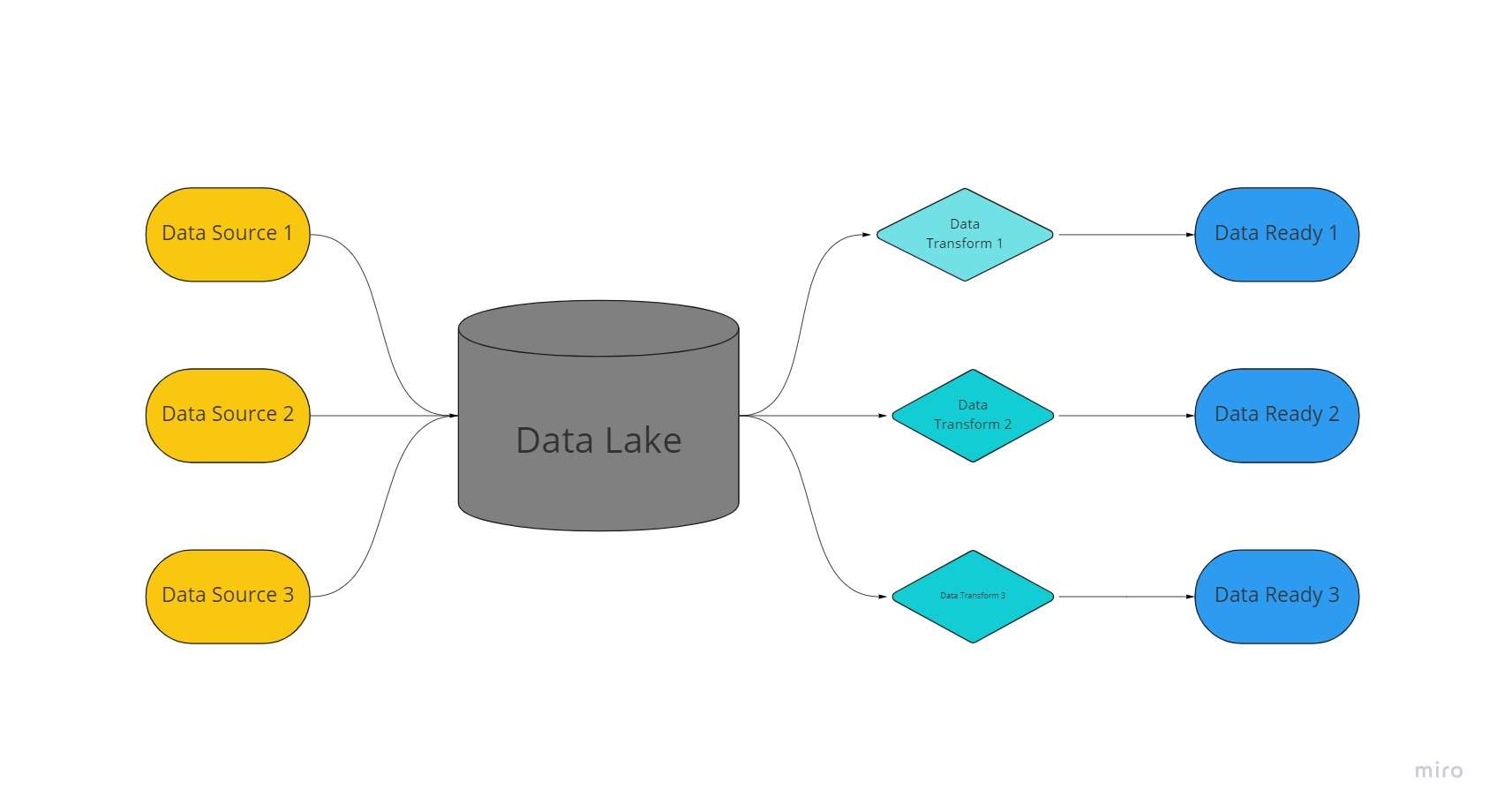
In Data Lakes werden Daten zu Analysezwecken extrahiert, geladen und transformiert (ELT), anstatt das Schema oder die Daten zum Zeitpunkt der Datenerfassung festzulegen.
Nutzung von Technologien für viele Datenarten von IoT-Geräten, Social Mediaund Streaming von Daten ermöglichen Data Lakes maschinelles Lernen und prädiktive Analysen.
Darüber hinaus kann ein Data Scientist, der Rohdaten verarbeiten kann, den Data Lake verwenden. Ein Data Warehouse hingegen ist für Unternehmen einfacher zu verwenden. Es ist perfekt für die Erstellung von Benutzerprofilen, Predictive analytics, maschinelles Lernen und andere Aufgaben.
Obwohl Data Lakes mehrere Probleme mit Data Warehouses lösen, ist ihre Datenqualität schlecht und ihre Abfragegeschwindigkeit unzureichend. Darüber hinaus sind zusätzliche Tools für Geschäftsbenutzer erforderlich, um SQL-Abfragen durchzuführen. Bei einem schlecht strukturierten Data Lake kann ein Problem mit Datenstagnation auftreten.
Vorteile von Data Lake
- Unterstützung für eine Vielzahl von Anwendungsfällen für maschinelles Lernen und Data Science Es ist einfacher, andere maschinelle und tiefe Lernalgorithmen zu verwenden, um die Daten in Data Lakes zu verarbeiten, da die Daten offen und roh gehalten werden.
- Ein großer Vorteil ist die Vielseitigkeit von Data Lakes, die es Ihnen ermöglicht, Daten in jedem Format oder Medium zu speichern, ohne dass ein voreingestelltes Schema erforderlich ist. Zukünftige Datenanwendungsfälle können unterstützt werden, und mehr Daten können analysiert werden, wenn die Daten in ihrem ursprünglichen Zustand belassen werden.
- Um nicht beide Arten von Daten in unterschiedlichen Kontexten speichern zu müssen, können Data Lakes sowohl strukturierte als auch unstrukturierte Daten enthalten. Für die Speicherung verschiedener Arten von Organisationsdaten bieten sie einen einzigen Ort.
- Im Vergleich zu herkömmlichen Data Warehouses sind Data Lakes kostengünstiger, da sie für die Aufbewahrung auf kostengünstiger Standardhardware wie Objektspeicher ausgelegt sind, der häufig auf niedrigere Kosten pro gespeichertem Gigabyte ausgelegt ist.
Einschränkungen von Data Lake
- Datenanalyse- und Business-Intelligence-Use-Cases schneiden schlecht ab: Data Lakes können unorganisiert werden, wenn sie nicht angemessen gepflegt werden, was es schwierig macht, sie mit Business-Intelligence- und Analysetools zu verknüpfen. Darüber hinaus, wenn dies für Berichts- und Analyseanwendungsfälle erforderlich ist, ein Mangel an Konsistenz Datenstrukturen und ACID-Transaktionsunterstützung (Atomicity, Consistency, Isolation, and Durability) kann zu einer suboptimalen Abfrageleistung führen.
- Die Inkonsistenz von Data Lakes macht es unmöglich, Datenzuverlässigkeit und -sicherheit durchzusetzen, was zu einem Mangel an beidem führt. Es kann schwierig sein, geeignete Datensicherheits- und Governance-Standards zu entwickeln, um sensible Datentypen zu berücksichtigen, da Data Lakes jede Datenform verarbeiten können.
Vorteile
- Lösungen, die für alle Arten von Daten erschwinglich sind.
- Kann mit Daten umgehen, die sowohl organisiert als auch halbstrukturiert sind.
- Ideal für komplizierte Datenverarbeitung und Streaming.
Nachteile
- Es muss eine ausgeklügelte Pipeline gebaut werden.
- Geben Sie den Daten etwas Zeit, um abfragbar zu werden.
- Es braucht Zeit, um die Datenzuverlässigkeit und -qualität zu gewährleisten.
Was ist Data Lakehouse?
Eine neuartige Big-Data-Speicherarchitektur namens „Data Lakehouse“ kombiniert die größten Aspekte von Data Lakes und Data Warehouses. Alle Ihre Daten, ob strukturiert, halbstrukturiert oder unstrukturiert, können dank eines Data Lakehouse an einem Ort mit den besten Möglichkeiten für maschinelles Lernen, Business Intelligence und Streaming gespeichert werden.
Data Lakes aller Art sind oft der Ausgangspunkt für Data Lakehouses; Danach werden die Daten in das Delta Lake-Format umgewandelt (eine Open-Source-Speicherschicht, die Data Lakes Zuverlässigkeit verleiht).
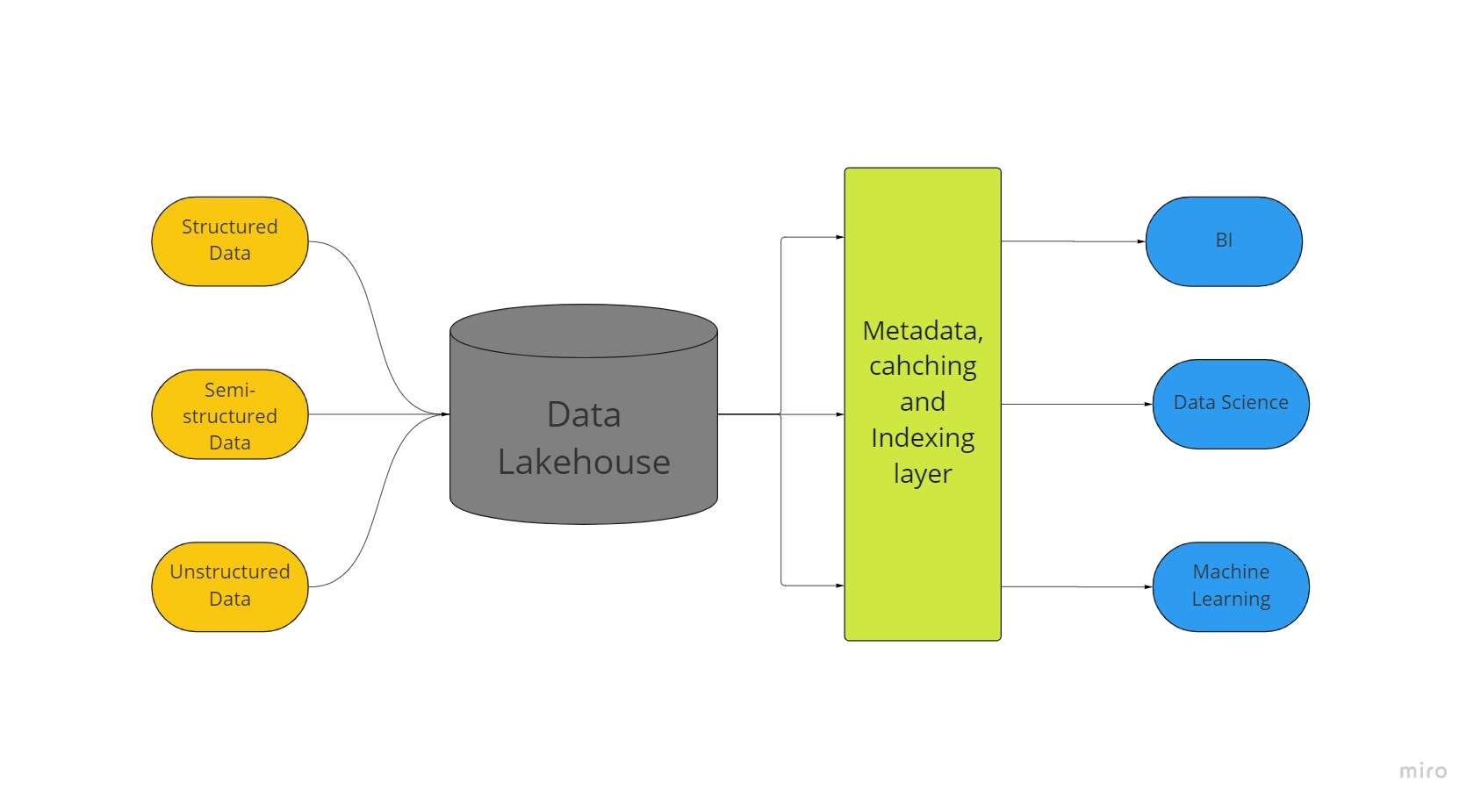
Data Lakes mit Delta Lakes ermöglichen ACID-Transaktionsverfahren aus herkömmlichen Data Warehouses. Im Wesentlichen verwendet das Lakehouse-System kostengünstigen Speicher, um große Datenmengen in ihrer ursprünglichen Form zu erhalten, ähnlich wie Data Lakes.
Das Hinzufügen der Metadatenschicht über dem Speicher verleiht auch Datenstruktur und stärkt Datenverwaltungstools, wie sie in Data Warehouses zu finden sind.
Dies ermöglicht vielen Teams den Zugriff auf alle Unternehmensdaten über ein einziges System für eine Vielzahl von Initiativen wie Data Science, maschinelles Lernen und Business Intelligence.
Vorteile von Data Lakehouse
- Unterstützung für ein größeres Spektrum an Workloads: Um anspruchsvolle Analysen zu ermöglichen, bieten Data Lakehouses Benutzern direkten Zugriff auf einige der beliebtesten Business-Intelligence-Tools (Tableau, PowerBI). Darüber hinaus können Datenwissenschaftler und Ingenieure für maschinelles Lernen die Daten problemlos verwenden, da Data Lakehouses offene Datenformate (z. B. Parquet) zusammen mit APIs und Frameworks für maschinelles Lernen wie Python/R verwenden.
- Kosteneffizienz: Data Lakehouses verwenden kostengünstige Objektspeicherlösungen, um die kostengünstigen Speichereigenschaften von Data Lakes zu implementieren. Durch das Angebot einer einzigen Lösung entfallen bei Data Lakehouses auch die Kosten und der Zeitaufwand für die Verwaltung verschiedener Datenspeichersysteme.
- Das Data-Lakehouse-Design gewährleistet die Schema- und Datenintegrität und vereinfacht den Aufbau effektiver Datensicherheits- und Governance-Systeme. Leichtigkeit von Datenversionierung, Verwaltung und Sicherheit.
- Data Lakehouses bieten eine einzige, vielseitige Datenspeicherplattform, die alle Datenanforderungen des Unternehmens erfüllen kann, wodurch Datenduplizierung reduziert wird. Die Mehrheit der Unternehmen entscheidet sich aufgrund der Vorteile sowohl des Data Warehouse als auch des Data Lake für eine Hybridlösung. Diese Strategie könnte unterdessen zu einer kostspieligen Datenduplizierung führen.
- Die Unterstützung offener Formate. Offene Formate sind Dateitypen, die von vielen Softwareanwendungen verwendet werden können und deren Spezifikationen öffentlich verfügbar sind. Berichten zufolge ist Lakehouses in der Lage, Daten in gängigen Dateiformaten wie Apache Parquet und ORC (Optimized Row Columnar) zu speichern.
Einschränkungen von Data Lakehouse
Der größte Nachteil eines Data Lakehouse ist, dass es sich um eine noch junge und sich entwickelnde Technologie handelt. Es ist ungewiss, ob es seine Verpflichtungen infolgedessen erfüllen wird. Bis Data Lakehouses mit etablierten Big-Data-Speichersystemen konkurrieren können, könnte es noch Jahre dauern.
Angesichts der Geschwindigkeit, mit der moderne Innovationen stattfinden, ist es jedoch schwierig zu sagen, ob ein anderes Datenspeichersystem sie nicht letztendlich ersetzen wird.
Vorteile
- Eine Plattform verfügt über alle Daten, was bedeutet, dass weniger Hostnamen verwaltet werden müssen.
- Atomarität, Konsistenz, Isolation und Zähigkeit werden nicht beeinflusst.
- Es ist deutlich günstiger.
- Eine Plattform verfügt über alle Daten, was bedeutet, dass weniger Hostnamen verwaltet werden müssen.
- Einfach zu verwalten und Probleme schnell zu beheben
- Machen Sie es einfacher, eine Pipeline zu konstruieren
Nachteile
- Die Einrichtung kann einige Zeit in Anspruch nehmen.
- Es ist zu jung und zu weit entfernt, um sich als etabliertes Speichersystem zu qualifizieren.
Data Warehouse vs. Data Lake vs. Data Lakehouse
Das Data Warehouse hat eine lange Geschichte in Corporate Intelligence-, Reporting- und Analyseanwendungen und ist die erste Big-Data-Speichertechnologie.
Data Warehouses hingegen sind kostspielig und haben Probleme beim Umgang mit vielfältigen und unstrukturierten Daten, wie z. B. Streaming-Daten. Für Machine-Learning- und Data-Science-Workloads wurden Data Lakes entwickelt, um Rohdaten in verschiedenen Formen auf erschwinglichem Speicher zu verwalten.
Obwohl Data Lakes mit unstrukturierten Daten effektiv sind, fehlen ihnen die ACID-Transaktionsfähigkeiten von Data Warehouses, was es schwierig macht, Datenkonsistenz und -zuverlässigkeit zu gewährleisten.
Die neueste Datenspeicherarchitektur, bekannt als „Data Lakehouse“, kombiniert die Zuverlässigkeit und Konsistenz von Data Warehouses mit der Erschwinglichkeit und Anpassungsfähigkeit von Data Lakes.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass es schwierig sein könnte, ein Data Lakehouse von Grund auf neu zu bauen. Darüber hinaus werden Sie mit ziemlicher Sicherheit eine Plattform verwenden, die entwickelt wurde, um eine Open-Data-Lakehouse-Architektur zu ermöglichen.
Achten Sie daher darauf, die vielen Funktionen und Implementierungen jeder Plattform zu untersuchen, bevor Sie einen Kauf tätigen. Unternehmen, die eine ausgereifte, strukturierte Datenlösung mit Fokus auf Anwendungsfälle für Business Intelligence und Datenanalyse suchen, können ein Data Warehouse in Betracht ziehen.
Unternehmen, die jedoch nach einer skalierbaren, erschwinglichen Big-Data-Lösung suchen, um Workloads für Data Science und maschinelles Lernen auf unstrukturierten Daten zu betreiben, sollten Data Lakes in Betracht ziehen.
Bedenken Sie, dass Ihr Unternehmen mehr Daten benötigt, als die Data-Warehouse- und Data-Lake-Technologien bereitstellen können, oder dass Sie nach einer Lösung suchen, um ausgefeilte Analysen und maschinelle Lernvorgänge in Ihre Daten zu integrieren. EIN Daten Lakehouse ist in der Situation eine sinnvolle Option.





Hinterlassen Sie uns einen Kommentar