Inhaltsverzeichnis[Ausblenden][Zeigen]
Daten sind überall um Sie herum. Im wahrsten Sinne des Wortes beeinflusst es jeden Aspekt Ihres Unternehmens. Es könnte sich anfühlen, als ob nicht genügend Zeit bleibt, um die Einzelheiten zu untersuchen, wie gut es Ihrem Unternehmen dient, wenn Sie mit Entscheidungen zum Umgang mit Ihren Daten beschäftigt sind.
Beachten Sie dies. Ihre Organisation nutzt Daten rund um die Uhr. Daher ist es entscheidend, zu verstehen, woher es kommt, wie es dorthin gelangt ist und wie es sich durch das Unternehmen bewegt, um seinen Wert zu verstehen.
Die Datenherkunft wird in dieser Situation wichtig. Es ist einfacher zu verstehen, wie Daten entstanden sind, woher sie kommen und wohin sie gehen, wenn wir die Ursprünge, Migrationen und Änderungen der Daten verfolgen können.
In diesem Beitrag werden wir uns Data Lineage genau ansehen, wie es funktioniert, seine Anwendungsfälle, Techniken und vieles mehr.
Was ist Data Lineage?
Data Lineage dient als eine Art digitaler Reisepass. Es ist der umfassendste Bericht über eine Datenreise, der alle Zwischenstopps, Umwege und Änderungen von seinem Ursprung bis zu seinem endgültigen Ziel detailliert beschreibt.
IIm Wesentlichen beschreibt die Datenherkunft den Ursprung, die Änderung und die Verwendung eines Datenelements über viele Systeme und Plattformen hinweg. Es fungiert als Detektivwerkzeug, indem es Benutzern Informationen darüber gibt, wie Daten produziert wurden, woher sie stammen und wie sie verwendet wurden. Diese Informationen ermöglichen Benutzern, mögliche Probleme zu erkennen und zu beheben.
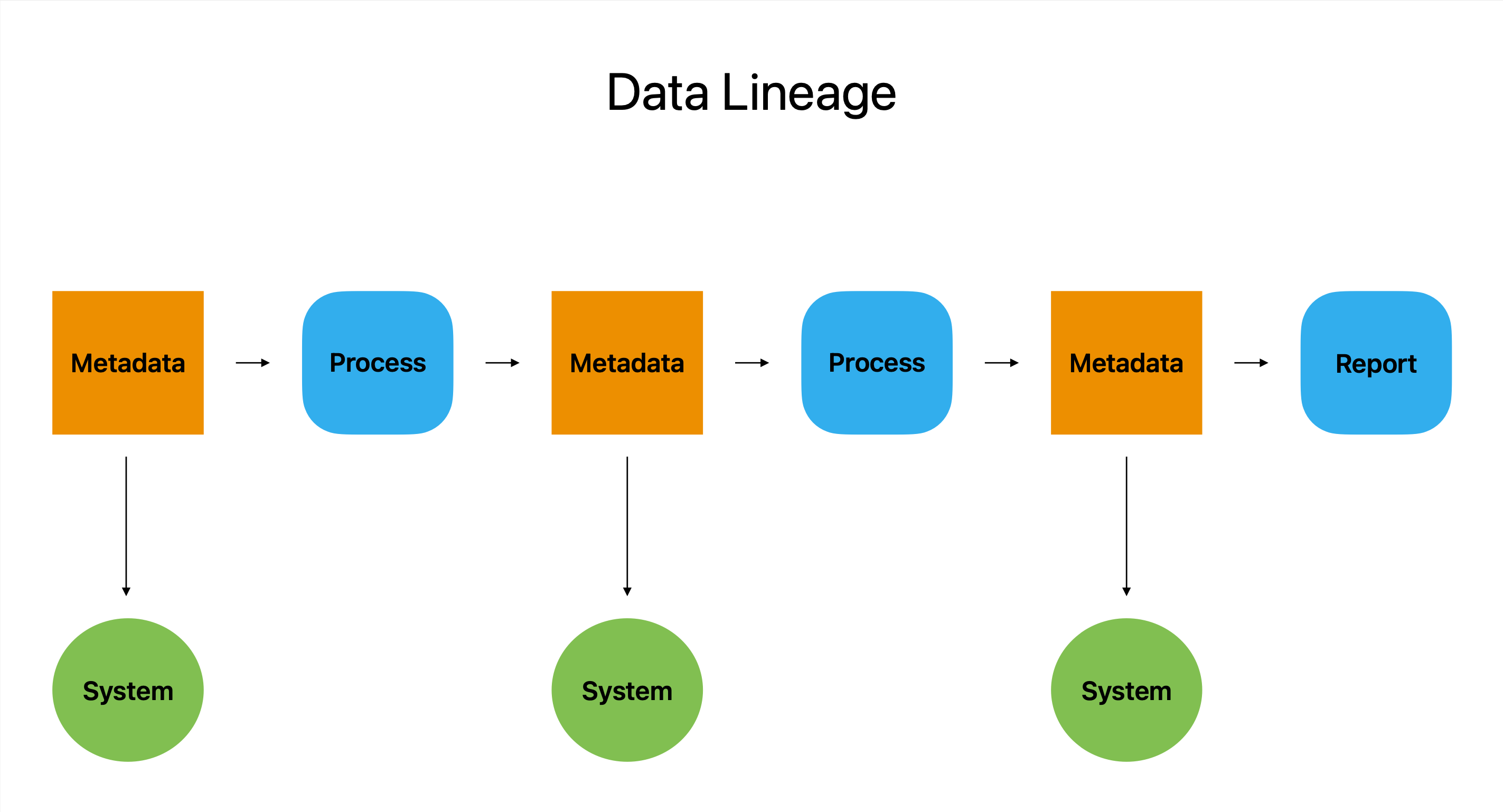
Die Datenherkunft ist eine unschätzbare Ressource für Unternehmen, die für ihre Geschäftstätigkeit auf Daten angewiesen sind, da sie es den Benutzern ermöglicht, auf wichtige Fragen wie Wer, Was, Wann und Wo zu antworten.
Die Datenherkunft ist, einfach ausgedrückt, der ultimative Datenpfad, der die Genauigkeit, Vollständigkeit und Konsistenz der Daten garantiert und gleichzeitig eine klare und prägnante Perspektive des vollständigen Pfads einer Daten bietet.
Wie funktioniert Data Lineage?
Die Datenherkunft ist die Roadmap, die es uns ermöglicht, ein Datenelement von seinem Ausgangspunkt bis zu seinem Endpunkt zu verfolgen. Betrachten Sie einen Datenpunkt als Reisenden und seinen Pass als seine Datenherkunft, um besser zu verstehen, wie er funktioniert.
Datenquellen, Datentransformation, Datenspeicherung und Datenausgabe bilden die vier Hauptkomponenten des Passes.
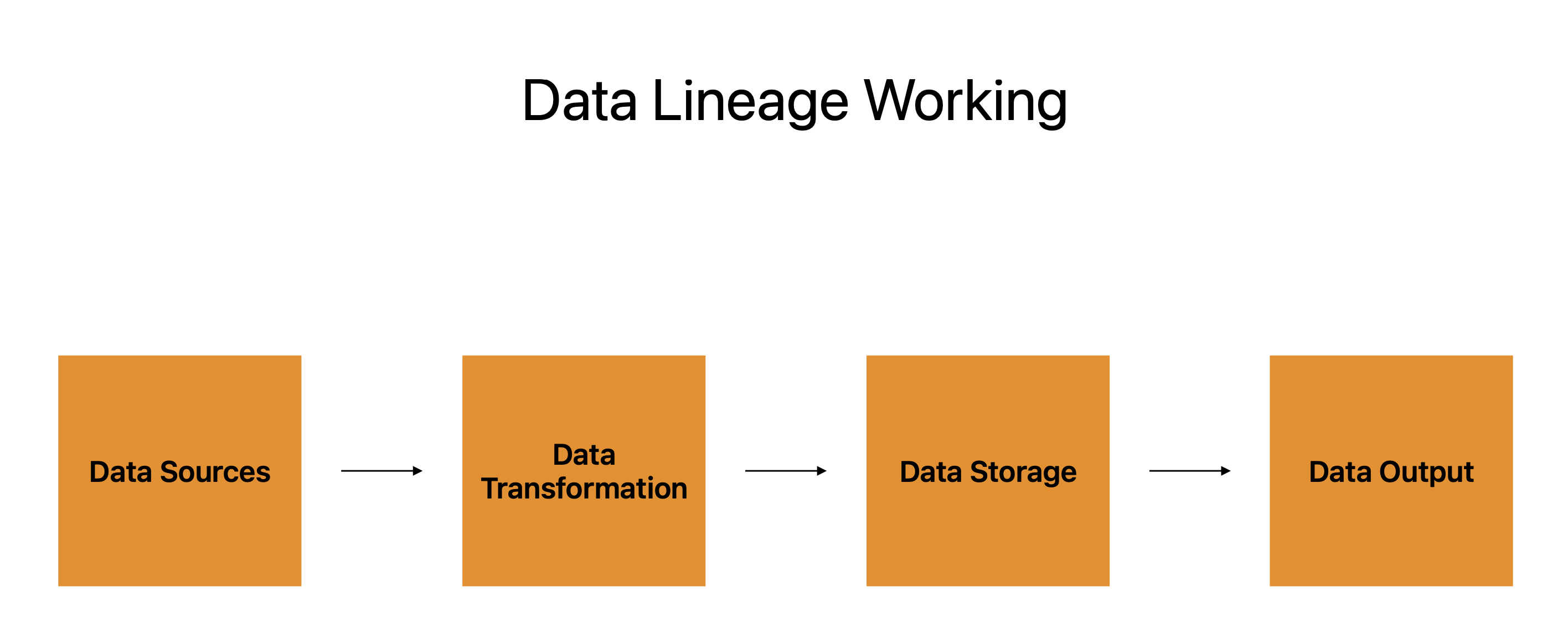
Die vielen Systeme, Anwendungen und Plattformen, aus denen die Daten stammen, werden durch Datenquellen repräsentiert, die als Ausgangspunkt für die Reise der Daten dienen. Die Datentransformation ist die nachfolgende Phase, und die Datenherkunft zeichnet den Fortschritt der Daten von diesen Quellen zu ihnen auf.
Datentransformation bezieht sich auf das Formen, Modifizieren und Manipulieren von Daten, um Benutzeranforderungen zu erfüllen. Es fungiert als Raststation während der Reise der Daten und bereitet sie auf die nächste Etappe vor.
Die Daten werden dann gespeichert, bevor sie an ihren endgültigen Ort gelangen. Es könnte auf Cloud-Servern, Datenbanken oder einer anderen Art von Speichergerät aufbewahrt werden. Die Datenherkunft verfolgt, wo die Daten gespeichert sind und wie sie geschützt, gesichert und wiederhergestellt werden.
Der letzte Schritt ist die Datenausgabe, bei der die Daten zur Verwendung gesendet werden. Zur Präsentation können Berichte, Infografiken oder andere Arten von Datenprodukten verwendet werden. Die Datenherkunft verfolgt die Ausgabe und garantiert die Konsistenz, Genauigkeit und Vollständigkeit der Daten.
Die Datenherkunft funktioniert im Grunde, indem jede Phase der Datenreise aufgezeichnet wird, von ihrem Anfang bis zu ihrer Ausgabe, und sichergestellt wird, dass sie während des gesamten Prozesses zuverlässig, konsistent und korrekt bleiben. Die Datenherkunft hilft Unternehmen, fundierte Entscheidungen zu treffen, Probleme zu beheben und gesetzliche Verpflichtungen einzuhalten, indem sie einen vollständigen Überblick über die Existenz von Daten bietet.
Metadaten sind ein entscheidender Bestandteil des Datenherkunftsprozesses, um die Datenbestände und ihren Weg durch die Datenpipeline zu verstehen.
Sie können sehen, wie Daten innerhalb der Organisation konvertiert und verwendet werden, indem Sie Datenherkunftstools verwenden, die Metadaten nutzen, um eine visuelle Darstellung des Datenflusses bereitzustellen. Auf diese Weise können Benutzer das Potenzial der Daten einschätzen und so fundiertere Entscheidungen treffen.
Arten der Datenherkunft
Es gibt drei grundlegende Formen der Datenherkunft: Vorwärtsdatenherkunft, Rückwärtsdatenherkunft und bidirektionale Datenherkunft.
Datenherkunft weiterleiten
Wie bei einer Einbahnstraße beinhaltet die Vorwärtsdatenabstammung das Verfolgen eines Datenstücks von seinem Anfangspunkt bis zu seinem Endpunkt. Ausgehend von der Datenquelle folgt es den Daten, während sie mehrere Transformationen und Speichersysteme durchlaufen, um ihre Ausgabe zu erreichen.
Das Verständnis der Verarbeitung und Transformation von Daten sowie etwaiger Probleme, die dabei aufgetreten sind, wird durch eine solche Datenherkunft erleichtert. Jeder Schritt führt zum nächsten; Es ist, als würde man einer Spur aus Brotkrümeln folgen.
Rückwärts-Datenherkunft
Die Rückwärts-Datenherkunft ähnelt einer Reise in umgekehrter Richtung, bei der wir die Ausgabe der Daten bis zu ihrer Quelle zurückverfolgen. Der Prozess beginnt am endgültigen Speicherort der Daten und bewegt sich rückwärts durch eine Vielzahl von Speicher- und Transformationstechniken, bis er die Datenquelle erreicht.
Mit Hilfe dieser Art von Data Lineage ist es möglich, die ursprüngliche Quelle der Daten zu identifizieren, ihre Transformation nachzuvollziehen und ihre Richtigkeit und Vollständigkeit zu überprüfen. Es funktioniert wie ein Detektivwerkzeug, mit dem wir den Pfad der Daten rückwärts verfolgen können.
Bidirektionale Datenherkunft
Eine wechselseitige, bidirektionale Datenherkunft kombiniert die Vorteile der Vorwärts- und Rückwärts-Datenherkunft. Es bietet einen umfassenden Überblick über die Route der Daten, indem es sie von ihrer Quelle bis zu ihrem Ziel sowie von diesem Ort bis zu ihrem Ausgangspunkt verfolgt.
Um die ursprüngliche Quelle der Daten zu bestimmen, zu verstehen, wie sie geändert wurden, und ihre Qualität, Konsistenz und Vollständigkeit auf dem gesamten Weg zu gewährleisten, ist es hilfreich, die Herkunft der Daten zu verfolgen. Mit Echtzeitinformationen zu Standort und Status ist es, als hätte man einen GPS-Tracker für Daten.
Implementierung von Data Lineage
Die Implementierung von Data Lineage in einer Organisation umfasst häufig die folgenden Phasen.
Definieren Sie die Datenquellen
Die Systeme und Datenbanken, die die Daten enthalten, die Sie verfolgen möchten, sollten alle identifiziert werden. Dazu müssen Sie zunächst die verschiedenen Datenquellen identifizieren, darunter Dateien, APIs und Cloud-Dienste.
Sammeln Sie die Metadaten
Die nächste Stufe besteht darin, Details zu den Daten zu erfassen, einschließlich Speicherort, Format und Organisation. Diese Metadaten ermöglichen es, die Eigenschaften der Daten und ihre Verwendung zu verstehen.
Identifizieren Sie Datenfehler
Es ist einfacher zu verstehen, wie Daten innerhalb der Organisation aktualisiert und verwendet werden, wenn der Datenfluss von seiner Quelle bis zu seinem Ziel abgebildet wird, einschließlich aller Transformationen oder Verarbeitungen, die entlang der Route stattfinden.
Datenzugriff verfolgen
Um Datensicherheit und Compliance aufrechtzuerhalten, verfolgen und aufzeichnen, wer auf die Daten zugreift.
Abstammung speichern und visualisieren
Verwenden Sie Visualisierungstools, um die Abstammung für ein einfaches Verständnis und eine einfache Analyse darzustellen. Speichern Sie die gesammelten Metadaten und Datenflussinformationen in einem einzigen Repository.
Implementieren Sie eine automatisierte Lösung
Sie können überprüfen, ob die Datenherkunft gesammelt und durch Automatisierung überwacht wird, was auch dazu beiträgt, Fehler zu reduzieren und die Produktivität zu steigern.
Überprüfen und aktualisieren
Stellen Sie sicher, dass die Abstammungsaufzeichnungen regelmäßig korrekt und aktuell sind, und aktualisieren Sie sie gegebenenfalls.
Der Implementierungsprozess muss möglicherweise geändert oder Phasen hinzugefügt werden, abhängig von den einzigartigen Anforderungen und Grenzen jeder Organisation.
Data Lineage-Techniken
Musterbasierte Abstammung
Bei dieser Methode wird die Abstammung durchgeführt, ohne mit der Programmierung interagieren zu müssen, die die Daten generiert oder transformiert hat. Metadatenauswertungen für Tabellen, Spalten und Geschäftsberichte gehören dazu. Es untersucht die Abstammung, indem es anhand dieser Metadaten nach Trends sucht.
Beispielsweise ist es sehr wahrscheinlich, dass eine Spalte in zwei Datensätzen mit demselben Namen und identischen Datenwerten dieselben Daten in unterschiedlichen Phasen ihrer Existenz darstellt. Ein Datenherkunftsdiagramm wird dann verwendet, um diese beiden Spalten zu verbinden.
Die musterbasierte Abstammung hat den erheblichen Vorteil, dass sie technologieunabhängig ist, da sie nur Daten überprüft, keine Datenverarbeitungsmethoden. Jede Datenbanktechnologie, einschließlich Oracle, MySQL und Spark, kann sie auf die gleiche Weise implementieren. Der Nachteil ist, dass dieser Ansatz nicht immer präzise ist.
Wenn die Datenverarbeitungslogik im Computercode verborgen und in menschenlesbaren Metadaten nicht ohne weiteres ersichtlich ist, kann sie gelegentlich Beziehungen zwischen Datensätzen übersehen.
Abstammung durch Datenkennzeichnung
Diese Methode basiert auf der Vorstellung, dass eine Transformationsmaschine Daten taggt oder anderweitig markiert. Es verfolgt das Tag von Anfang bis Ende, um die Abstammung zu finden. Dieser Ansatz kann nur erfolgreich sein, wenn Sie über ein zuverlässiges Transformationstool verfügen, das den gesamten Datentransfer verwaltet, und Sie mit der Tagging-Struktur vertraut sind, die das Tool verwendet.
Selbst wenn ein solches Tool existieren würde, könnten keine Daten, die ohne es erstellt oder geändert wurden, einer Abstammung durch Daten-Tagging unterzogen werden. Es beschränkt sich dabei auf die Durchführung von Data Lineage auf geschlossenen Datensystemen.
Eigenständige Abstammung
Einige Unternehmen verfügen über eine Datenumgebung, die Metadatenspeicherung, Verarbeitungslogik und Master Data Management (MDM) umfasst. Zu diesen Einstellungen gehören häufig a Daten See wo alle Daten während ihrer gesamten Lebensdauer aufbewahrt werden.
Abstammung kann natürlich durch diese Art von in sich geschlossenem System bereitgestellt werden, ohne dass zusätzliche Ressourcen erforderlich sind. Genau wie bei der Data-Tagging-Methode wird Lineage jedoch nichts mitbekommen, was außerhalb dieser regulierten Umgebung geschieht.
Datenherkunft durch Parsing
Die ausgefeilteste Art der Abstammung ist eine, die die Datenverarbeitungslogik automatisch liest. Für eine gründliche End-to-End-Verfolgung baut diese Methode die Datenumwandlungslogik zurück.
Da diese Lösung alle umfassen muss Programmiersprachen und Tools, die zum Konvertieren und Transportieren der Daten verwendet werden, ist ihre Bereitstellung kompliziert. Dies kann ETL-Logik (Extract-Transform-Load), SQL- und Java-basierte Lösungen, alte Datenformate, XML-basierte Lösungen und andere Techniken verwenden.
Anwendungsfälle der Datenherkunft
Datenmodellierung
Unternehmen müssen die zugrunde liegenden Datenstrukturen etablieren, die sie unterstützen, um die vielen Datenelemente und die Verbindungen zwischen ihnen innerhalb eines Unternehmens zu visualisieren. Diese Verbindungen werden mithilfe von Data Lineage modelliert, was auch die vielen Abhängigkeiten zeigt, die im Datenökosystem vorhanden sind.
Da sich Daten im Laufe der Zeit ändern, entstehen ständig neue Datenquellen, die neue Datenintegrationen erfordern usw. Aus diesem Grund müssen sich auch die allgemeinen Datenmodelle der Unternehmen zur Verwaltung ihrer Daten ändern, um sie an die Umgebung anzupassen.
Compliance
Data Lineage bietet eine Compliance-Methode zur Prüfung, Verbesserung des Risikomanagements und Sicherstellung, dass Daten in Übereinstimmung mit Data-Governance-Richtlinien und Gesetzen aufbewahrt und behandelt werden.
Einflussanalyse
Die Auswirkungen bestimmter geschäftlicher Änderungen, wie z. B. nachgelagerte Berichte, können mithilfe von Datenherkunftstools angezeigt werden. Die Datenherkunft beispielsweise könnte Führungskräften dabei helfen, festzustellen, wie viele Dashboards eine Namensänderung betreffen würde und wie viele Personen folglich auf diese Berichte zugreifen.
Datenmigration
Unternehmen nutzen die Datenmigration, um zu verstehen, wo sich die Daten befinden und wie lange sie dort waren, bevor sie auf ein neues Speichersystem verschoben oder neue Software implementiert werden.
Die Datenherkunft hilft Teams bei der Vorbereitung auf System-Upgrades oder -Migrationen, indem sie ihnen einen Überblick darüber geben, wie sich die Daten im gesamten Unternehmen bewegt haben. Dadurch wird die Übertragung auf die neue Speicherumgebung insgesamt beschleunigt.
Darüber hinaus gibt es Teams die Möglichkeit, das Datensystem zu entrümpeln, indem veraltete oder nutzlose Daten archiviert oder gelöscht werden. Dadurch wird das Datensystem insgesamt leistungsfähiger und benötigt weniger Datenverwaltung.
Herausforderungen bei der Implementierung von Data Lineage
- Datensicherheit: Die Datensicherheit ist ein Hauptanliegen beim Aufbau der Datenherkunft. Um eine Datenreise vom Ausgangspunkt bis zum endgültigen Ziel zu verfolgen, muss der Zugriff auf sensible Daten gewährt werden, und diese Daten müssen vor unbefugtem Zugriff und Verstößen geschützt werden.
- Fehlende Standardisierung: Eines der Haupthindernisse für die Übernahme der Datenherkunft ist das Fehlen von Standards. Da viele Plattformen, Apps und Systeme einzigartige Methoden zur Verfolgung und Aufzeichnung der Datenherkunft verwenden, kann es schwierig sein, ein zusammenhängendes Bild einer Datenreise zu erstellen.
- Datensilos: Datensilos sind ein weiteres Problem, das bei der Implementierung von Data Lineage auftritt. Wenn Daten über mehrere Anwendungen und Systeme verteilt sind, kann es schwierig sein, ihren Weg von einem zum anderen zu verfolgen. Dies kann zu einer ungenauen oder unvollständigen Datenherkunft führen.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass die Datenherkunft ein wesentlicher Bestandteil jedes datengesteuerten Unternehmens ist. Es bietet eine umfassende Perspektive des Datenpfads von seinem Anfangspunkt bis zu seinem Endpunkt und garantiert seine Genauigkeit, Vollständigkeit und Konsistenz.
Die zukünftige Automatisierung und Standardisierung der Datenherkunft wird voraussichtlich zunehmen, was die Implementierung und Wartung für Unternehmen vereinfacht. Am Ende kann die Bedeutung der Datenherkunft nicht betont werden.
Es gibt Unternehmen die Werkzeuge an die Hand, die sie benötigen, um kluge Entscheidungen zu treffen, ihre Abläufe effizienter zu führen und Erfolge zu erzielen.





Hinterlassen Sie uns einen Kommentar