Das Verschieben und Speichern von Daten hat aufgrund der ständigen Expansion der IT-Branche und der Millionen von Datenpunkten, die jede Sekunde produziert werden, an Bedeutung gewonnen.
Darüber hinaus müssen diese Daten klar und einfach zu verstehen sein, um eine präzise Entscheidungsfindung zu unterstützen.
Um wettbewerbsfähig zu bleiben und langfristigen Erfolg zu erzielen, muss Ihr Unternehmen Daten mit den effizientesten verfügbaren Lösungen speichern und verschieben.
Aus diesem Grund nutzen immer mehr Unternehmen Data Fabrics. Eine der besten Möglichkeiten, Zeit, Geld und Ressourcen zu sparen, besteht darin, eine Datenstruktur zu verwenden, um Daten zu verarbeiten und maschinelles KI-Lernen zu ermöglichen.
In diesem Artikel werfen wir einen tiefen Blick auf Data Fabric, einschließlich seiner Verwendung, Hauptkomponenten, Vorteile und anderer wichtiger Details.
Also, was ist Data Fabric?
Unabhängig davon, wo sie sich befinden, verwalten und überwachen Sie Ihre Daten und Apps. Im Kern ist eine Data Fabric eine integrierte Datenarchitektur, die sicher, vielseitig und anpassungsfähig ist.
Eine Data Fabric, die das Beste aus Cloud, Core und Edge kombiniert, ist in vielerlei Hinsicht ein neuer strategischer Ansatz für Ihren geschäftlichen Speicherbetrieb.
Während es zentral gesteuert wird, kann es überall erreichen, einschließlich lokaler, öffentlicher und privater Clouds sowie Edge- und IoT-Geräte.
Wolkenkratzergroße Datensilos und vielfältige, nicht vernetzte Infrastrukturen gehören der Vergangenheit an. Eine Datenstruktur basiert auf einer umfassenden Sammlung von Datenverwaltungstools, die Konsistenz in Ihren verknüpften Umgebungen gewährleisten.
Optimiert durch Automatisierung die zeitaufwändige Verwaltung, beschleunigt die Entwicklung, das Testen und die Bereitstellung und schützt Ihre Ressourcen rund um die Uhr.
Unabhängig davon, wo sich Ihre Daten und Apps befinden, können Sie Speicherkosten, Leistung und Effizienz von einer einzigen Plattform aus verfolgen.
Sie können schnell (und in einigen Fällen automatisch) Änderungen an Ihrer Hybrid-Cloud-Infrastruktur vornehmen, sobald Sie umsetzbare Kenntnisse darüber haben, wie z.
Kurz gesagt, Data Fabric verbessert die Infrastrukturbereitstellung und -wartungseffizienz, senkt die Kosten und steigert die Leistung.
Warum sollten Sie eine Data Fabric verwenden?
Jedes datenzentrierte Unternehmen benötigt eine umfassende Strategie, die Hindernisse wie Zeit, Platz, verschiedene Softwarearten und Datenstandorte überwindet. Daten sollten nicht hinter Firewalls versteckt oder auf mehrere Orte verteilt sein, sondern für Personen verfügbar sein, die sie benötigen.
Um erfolgreich zu sein, benötigen Unternehmen eine zukunftssichere Datenlösung und eine sichere, effektive und einheitliche Umgebung. Dies kann mit einer Datenstruktur erfolgen.
Die Bedürfnisse moderner Unternehmen nach Echtzeitverbindung, Self-Service, Automatisierung und universellen Änderungen können nicht durch herkömmliche Datenintegration erfüllt werden.
Während das Sammeln von Daten aus vielen Quellen oft kein Problem darstellt, haben viele Unternehmen Schwierigkeiten, Daten mit Daten aus anderen Quellen zu integrieren, zu verarbeiten, zu kuratieren und zu transformieren.
Um ein tiefgreifendes Verständnis von Verbrauchern, Partnern und Waren zu erhalten, muss dieser entscheidende Schritt im Datenverwaltungsprozess stattfinden. Aufgrund ihrer Fähigkeit, ihre Systeme zu aktualisieren, Kunden besser zu bedienen und zu nutzen Cloud Computing, Unternehmen erhalten dadurch einen Wettbewerbsvorteil.
Wo immer sich die Benutzer der Organisation befinden, kann man sich die Datenstruktur als ein global ausgebreitetes Tuch vorstellen. In diesem Netzwerk kann sich der Benutzer an jedem Ort befinden und trotzdem uneingeschränkten Echtzeitzugriff auf Daten an jedem anderen Ort haben.
Kernkomponenten von Data Fabric
Die Kernkomponenten, aus denen eine Datenstruktur besteht, können auf verschiedene Weise ausgewählt und gesammelt werden. Die Datenstruktur kann somit auf vielfältige Weise implementiert werden. Sehen wir uns die Hauptelemente einer Datenstruktur an.
- Erweiterter Datenkatalog
- Persistenzschicht
- Wissen Graph
- Insights- und Empfehlungs-Engine
- Datenvorbereitungs- und Datenbereitstellungsschicht
- Orchestrierung und Datenoperationen
Sie können sich die wichtigsten Säulen der Data-Fabric-Architektur gemäß ansehen Gartner.
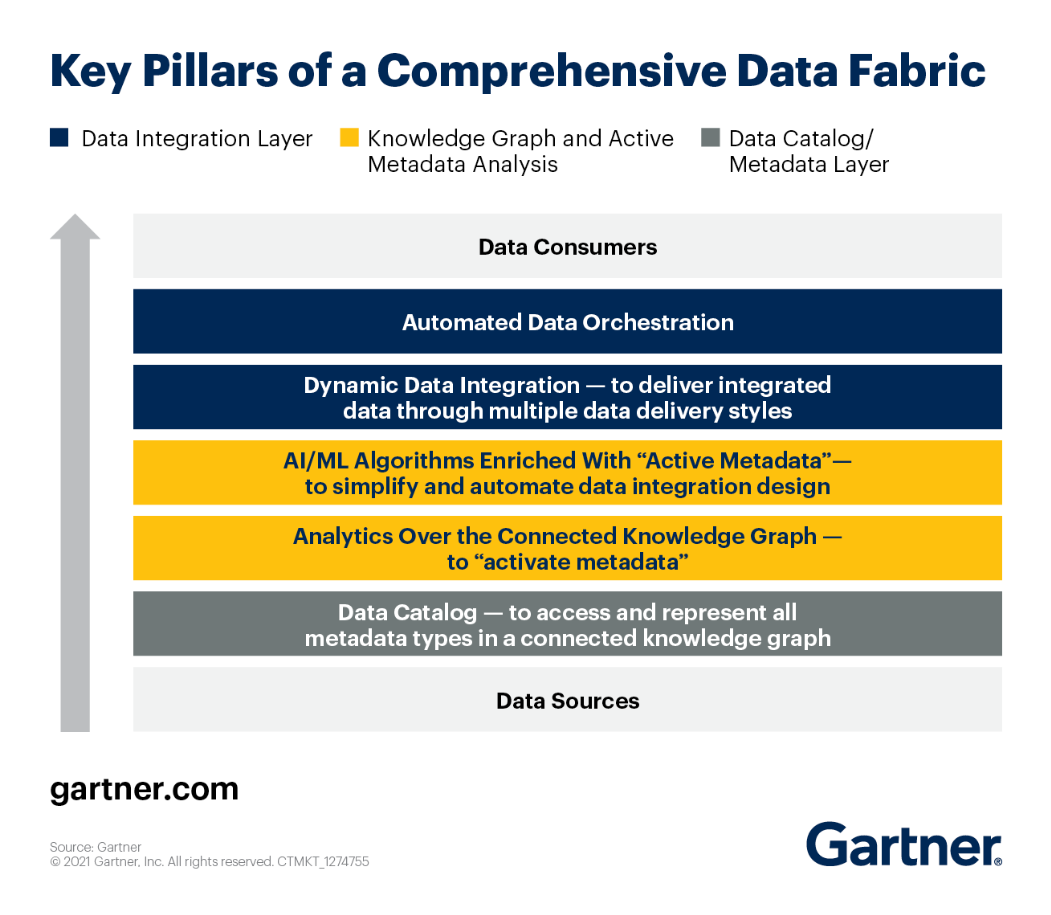
Schauen wir uns jeden von ihnen genau an.
- Erweiterter Datenkatalog – bietet Benutzern Zugriff auf alle Arten von Metadaten durch einen starken Wissensgraphen. Darüber hinaus entwickelt es eindeutige Assoziationen zwischen vorhandenen Informationen und zeigt diese auf verständliche Weise visuell an. Durch die Nutzung Maschinelles Lernen Um Datenbestände mit organisatorischer Terminologie zu verknüpfen, erstellen erweiterte Datenkataloge die semantische Geschäftsschicht für die Datenstruktur.
- Persistenzschicht – Je nach Anwendungsfall können verschiedene relationale und nicht-relationale Modelle verwendet werden, um Daten dynamisch zu speichern.
- Aktive Metadaten – ein markanter Teil einer Datenstruktur. gibt der Datenstruktur die Möglichkeit, viele Arten von Metadaten zu sammeln, zu teilen und zu analysieren. Im Gegensatz zu passiven Metadaten verfolgen aktive Metadaten die laufende Nutzung von Daten durch Systeme und Personen (designbasierte und Laufzeit-Metadaten).
- Wissen Graph – Eine weitere grundlegende Einheit für Data Fabrics. Sie verwenden Standard-IDs, anpassbare Schemas usw., um eine verknüpfte Datenumgebung anzuzeigen. Wissensgraphen machen die Datenstruktur durchsuchbar und helfen bei ihrem Verständnis.
- Insights- und Empfehlungs-Engine – baut zuverlässige, starke Datenpipelines für operative und analytische Anwendungsfälle auf.
- Datenvorbereitungs- und Datenbereitstellungsschicht – Daten können aus jeder Quelle abgerufen und mit jedem Mechanismus an jedes Ziel gesendet werden, einschließlich ETL (Bulk), Messaging, CDC, Virtualisierung und API.
- Orchestrierung und Datenoperationen – Diese Komponente verwendet Daten, um alle Aufgaben in jeder Phase des End-to-End-Workflows zu koordinieren. Sie können auswählen, wann und wie oft Pipelines ausgeführt werden sollen, und wie die von diesen Pipelines erzeugten Daten verwaltet werden.
Benefits
Gesunde Daten in einem verteilten Kontext sind über eine Datenstruktur zugänglich, werden geladen, integriert und gemeinsam genutzt. Auf diese Weise können Unternehmen den digitalen Übergang beschleunigen und den Wert ihrer Daten maximieren.
Im Folgenden werden die wichtigsten Vorteile des Data-Fabric-Modells skizziert.
Effizienz:
Eine Datenstruktur kann Ergebnisse aus früheren Abfragen zusammenstellen, sodass das System die aggregierte Tabelle anstelle der Rohdaten im Backend scannen kann.
Aufgrund der schnelleren Antwortzeiten einzelner Anfragen löst es auch das Problem mehrerer gleichzeitiger Anfragen, Anfragen auf kleinere Datensätze zugreifen zu lassen, anstatt die Rohdaten des gesamten Speichers scannen zu müssen.
Unternehmen können schnell auf dringende Anfragen reagieren, da die Datenstruktur die Antwortzeiten für Anfragen erheblich verkürzen kann.
Intelligente Integration
Um Daten über verschiedene Datenarten und Endpunkte hinweg zu integrieren, nutzen Data Fabrics semantische Wissensgraphen, Metadatenverwaltung und maschinelles Lernen.
Dies hilft Datenmanagementteams, relevante Datensätze zusammenzufassen und brandneue Datenquellen in das Datenökosystem eines Unternehmens zu integrieren.
Diese Funktion automatisiert Teile des Datenaufgabenmanagements, was zu den oben genannten Produktivitätseinsparungen führt, aber sie hilft auch dabei, Datensystemsilos aufzubrechen, Data-Governance-Verfahren zu zentralisieren und die allgemeine Datenqualität zu verbessern.
Effektivere Datensicherheit
Es bedeutet auch nicht, Datensicherheit und Datenschutz zu opfern, um den Datenzugriff zu erweitern.
Tatsächlich erfordert es die Verschärfung der Zugangskontrollleitplanken und die Implementierung weiterer Data-Governance-Maßnahmen, um sicherzustellen, dass bestimmte Rollen die einzigen sind, die Zugriff auf einen bestimmten Datensatz haben.
Darüber hinaus ermöglichen Data-Fabric-Architekturen technische und Sicherheitsteams zur Implementierung der Datenmaskierung und Verschlüsselung vertraulicher und sensibler Informationen, wodurch die Wahrscheinlichkeit von Datenaustausch und Systemhacks verringert wird.
Demokratisierung von Daten
Self-Service-Anwendungen werden durch Data-Fabric-Designs erleichtert, wodurch die Reichweite des Datenzugriffs über mehr technisches Personal wie Dateningenieure, Entwickler und Datenanalyseteams hinaus erweitert wird.
Indem Geschäftsanwendern ermöglicht wird, schneller geschäftliche Entscheidungen zu treffen, und indem sie technischen Anwendern die Möglichkeit geben, Aktivitäten zu priorisieren, die ihre Fähigkeiten am besten nutzen, führt die Eliminierung von Datenengpässen zu einer Steigerung der Produktivität.
Anwendungsszenarien
Eine Data-Fabric-Architektur soll eine übergreifende Struktur für die Handhabung aller Formen der gespeicherten Informationen bieten, damit sie bei Bedarf nutzbar gemacht werden können.
Diese Art von Daten kann für alles verwendet werden, von einer Umsatzprognose bis hin zu einem Bericht über den Zustand der IT-Infrastruktur oder der Benutzerendpunkte eines Unternehmens.
Anwendungsfälle für die Data-Fabric-Architektur sind identisch mit Anwendungsfällen für jede andere Art von Daten in einem Unternehmen, einschließlich Vertrieb, Marketing, IT, Cybersicherheit und mehr.
Daten in einer Organisation sind jedoch in fast allen Anwendungsfällen oft organisiert, halbstrukturiert oder unstrukturiert. Eine relationale Datenbank kann strukturierte Daten speichern und sofort verwendet werden, wie etwa Datenbankaufzeichnungen.
Daten, die nicht bereinigt oder kategorisiert wurden, werden als unstrukturierte Daten bezeichnet und müssen bei Bedarf für die Verwendung aufbereitet werden.
Zu den verschiedenen Formen unstrukturierter Daten, die viele Unternehmen erwerben und für die zukünftige Verwendung speichern können, gehören: Maschinelles Lernen, Analysen, Sensordaten, Cloud Computing und Produktivitäts-Apps.
Bei halbstrukturierten Daten, also Daten anerkannter Art, die zusammen mit unstrukturierten Daten gespeichert werden (z. B. Zip-Dateien, Webseiten und E-Mails), sind beide Aspekte vorhanden.
Zahlreiche mögliche Anwendungsfälle basierend auf der Fähigkeit der Data Fabric, Unternehmen dabei zu unterstützen, schneller und effektiver auf ihre Daten zuzugreifen und diese zu nutzen, können durch die Erforschung ihrer Nutzung gefunden werden.
Typische Beispiele sind:
- Entdeckung eines Betruges
- IoT-Analyse
- Lieferkettenlogistik
- Datenanalyse in Echtzeit
- Kundeninformationen
- Steigerung der betrieblichen Effizienz
- Analyse der vorbeugenden Wartung
- Zusätzlich Risikomodelle für die Rückkehr an den Arbeitsplatz
- Absicherung von Transaktionen mit Kreditkarten
- Abwanderungsvorhersage, Betrugserkennung und Kreditwürdigkeitsprüfung
Zusammenfassung
Zusammenfassend lässt sich sagen, dass Datensilos mit zunehmender Datennutzung schrittweise aufgelöst werden müssen, um Platz für vernetzte Unternehmen zu schaffen.
Der Einsatz von Data Fabrics stellt einen bedeutenden Fortschritt auf diesem Weg dar und zählt zu den bahnbrechendsten Entdeckungen seit der Entwicklung relationaler Datenbanken in den 1970er Jahren.
Dies liegt daran, dass Data Fabric mehr als eine Technologie oder ein einzelnes Element ist.
Daten und Geschäftsbetrieb werden durch die Gestaltung der Architektur, ein systematisches Vorgehen und einen Mentalitätswandel eng miteinander verwoben.
Data Fabric reduziert Kosten, steigert die Leistung und ermöglicht eine effektivere Bereitstellung und Wartung der Infrastruktur. Es könnte die Schlüsselkomponente sein, um sicherzustellen, dass jeder Prozess, jede Anwendung und jede Geschäftsentscheidung datengesteuert ist.





Hinterlassen Sie uns einen Kommentar