Da es in der Datenwissenschaft darum geht, tatsächliche Probleme anzugehen, ist es sinnvoll, dass einige Fähigkeiten nützliche Ressourcen in ihrem sich ständig weiterentwickelnden Toolset sind.
Jeder angehende Datenwissenschaftler sollte sich im Rahmen seiner Ausbildung auf Computational Thinking konzentrieren, da es grundlegende Ideen der Informatik vermittelt und wie man komplizierte Probleme durch Abstraktion und Dekonstruktion angeht.
Computational Thinking ist eine entscheidende Fähigkeit im Zeitalter der Digital-First-Technologie, nicht nur für aufstrebende Data Scientists, sondern für alle, die an der Computational World teilnehmen möchten.
Um für die Entwicklung des Arbeitsmarktes und die Zukunft der Arbeit gerüstet zu sein, die von durchdringender Automatisierung geprägt sein wird, künstliche Intelligenz, und maschinelles Lernen, ist es unerlässlich, die Fähigkeiten des computergestützten Denkens als Schlüsselkomponente der Bildung und beruflichen Entwicklung hervorzuheben.
In diesem Artikel werden wir uns detailliert mit Computational Thinking befassen und seine Elemente, seinen Wert und vieles mehr behandeln.
Also, was ist Computational Thinking?
Computational Thinking, auch bekannt als algorithmisches Denken, ist eine methodische Technik, um ein komplexes Problem anzugehen, indem es in kleinere, einfachere Prozesse zerlegt wird, die von einem Computer oder einer Maschine ausgeführt werden können.
Es ist entscheidend, ein Problem so zu lösen, dass ein Computer den Prozess ausführen kann, da dies bedeutet, dass die Antwort auf ähnliche Probleme in anderen Kontexten angewendet werden kann.
Computational Thinking beinhaltet eine agile, innovative und flexible Haltung, um Herausforderungen und Lösungsansätze möglichst effizient zu bearbeiten sowie Daten erfolgreich zu nutzen und zu analysieren.
Der Begriff „Computational Thinking“ stammt aus der Denkweise von Informatikern, ist aber heute als Denkweise anerkannt, die jeder anwenden kann, um Probleme in seinem persönlichen oder beruflichen Leben zu lösen.
Es geht also nicht um ein maschinenähnliches Denken, sondern darum, Problemlösungsstrategien zu schaffen, die Informatiker gemeinhin verwenden.
Computational Thinking ist ein entscheidendes Werkzeug für Data Scientists, da es zur Bewältigung einer Vielzahl quantitativer und datenintensiver Herausforderungen eingesetzt werden kann.
Diese Methode kann verwendet werden, um Probleme in einer Vielzahl von Bereichen zu lösen, einschließlich Mathematik und künstlicher Intelligenz. Dieser Ansatz verwendet auch die Programmiersprache Python, die verwendet wird, um die Antwort während des statistischen Analyseschritts auf einem Computer darzustellen.
Warum ist Computational Thinking unerlässlich?
Diese Problemlösungsmethoden lassen sich mit Computational Thinking auf eine Reihe von Themen anwenden. Darüber hinaus gibt es Fähigkeiten, die das Computerdenken mit denen teilt, die in anderen MINT-Bereichen sowie in den Künsten, Sozial- und Geisteswissenschaften verwendet werden.
Die Nutzung der Leistungsfähigkeit von Computern außerhalb des Bildschirms und der Tastatur wird durch rechnerisches Denken gefördert. Darüber hinaus könnte es uns helfen, die Chancengleichheit in der Informatikausbildung zu verbessern.
Wir können die Integration der Informatik in andere Fachgebiete fördern und mehr Studenten an das Potenzial der Informatik heranführen, indem wir uns auf die Problemlösungsfähigkeiten konzentrieren, die im Kern der Informatik stehen.
Darüber hinaus ermöglicht uns Computational Thinking, das Potenzial und die Grenzen der Technologie zu untersuchen, während sie produziert wird.
Wir können beurteilen, wer Technologie entwickelt und warum, und wir können kritisch prüfen, wie sie sich auf die Gesellschaft auswirken kann.
Kernkomponenten des Computational Thinking
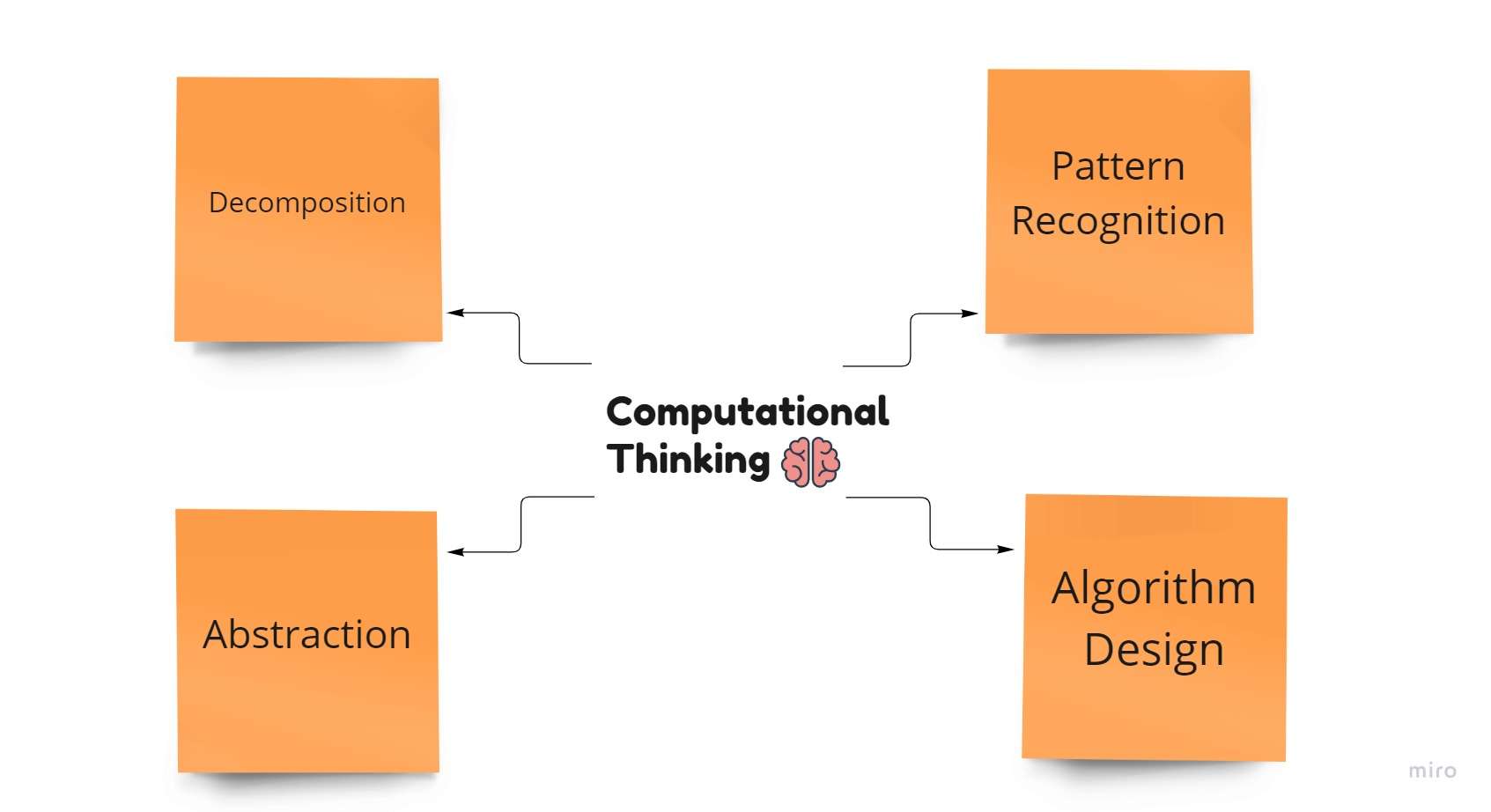
1. Zersetzung
Dekomposition ist das grundlegende Element des Computational Thinking. Um das Problem leichter lösbar zu machen, wird es in dieser Phase in kleinere Komponenten zerlegt.
Ein Problem ist umso einfacher zu beheben, je mehr Sie es analysieren können. Die Teile eines Fahrrads können als nützliche Zerlegungspraxis zerlegt werden. Der Rahmen, die Räder, der Lenker und die Schaltung eines Fahrrads können zunächst seziert werden.
Sie können jedoch jede Komponente weiter in ihre Bestandteile unterteilen. Beispielsweise kann künstliche Intelligenz weiter unterteilt werden in maschinelles Lernen, Deep Learning, Computer Vision und Verarbeitung natürlicher Sprache.
Dieser Schritt hilft Ihnen auch, ein tieferes Verständnis des Problems aufzubauen, indem Sie alle Komponenten eingehend identifizieren.
2. Mustererkennung
In der zweiten Stufe, der sogenannten Mustererkennung, werden Gemeinsamkeiten und Trends des Problems gefunden.
Es besteht eine hohe Wahrscheinlichkeit, dass sie unter Verwendung ähnlicher oder wiederkehrender Verfahren gehandhabt werden können, wenn bestimmte Schwierigkeiten ähnlicher Natur sind – sowohl innerhalb des Problems, das gerade angegangen wird, als auch innerhalb früherer Probleme.
Dies ist ein entscheidendes Element, um effektive Lösungen zu entwickeln und Ihnen letztendlich Zeit zu sparen.
Stellen Sie sich folgendes Szenario vor: Sie sollen ein kleines Programm entwickeln, das ein Quadrat zeichnet. Anstatt die Anweisung viermal hintereinander zu schreiben, kann das Muster, eine Linie zu ziehen und den Stift um 90 Grad zu drehen, viermal hintereinander wiederholt werden.
Mustererkennung ist ein entscheidendes Talent für die Entwicklung effizienter und effektiver Problemlösungen.
3. Abstraktion
Die Identifizierung wichtiger Elemente der Lösung erfolgt im dritten Abstraktionsschritt.
Es erfordert die Fähigkeit, überflüssige Teile eines Problems herauszufiltern, sodass Sie sich nur auf die wesentlichen Elemente konzentrieren können, anstatt auf genaue Einzelheiten zu schauen.
Ein weiteres hervorragendes Beispiel ist, wenn Sie Sport treiben, versuchen Sie, sich auf die Strategien zu konzentrieren, die Sie anwenden sollten, und Sie ignorieren alle Hänseleien Ihrer Gegner.
Vor der Entwicklung der endgültigen Lösung ermöglicht Ihnen die Abstraktion, alle wichtigen Faktoren zu berücksichtigen und überflüssige Elemente zu vernachlässigen.
4. Algorithmusdesign
Die Erstellung einer gründlichen Reihe von Schritt-für-Schritt-Anweisungen, die beschreiben, wie das Problem gelöst werden kann, erfolgt während der Phase des Algorithmusdesigns, der letzten Phase im Computational Thinking-Prozess.
Ein effektiver Algorithmus ist einer, der jemand anderem gegeben und ohne weitere Erklärung befolgt werden kann.
Die Welt ist voller Algorithmen, egal ob Sie nach einem Rezept kochen, Möbel zusammenbauen, in einem Drive-Through-Restaurant essen oder Ihre Lebensmittel an einer Selbstbedienungstheke bezahlen
Debugging ist eine entscheidende Fähigkeit, die es zu beherrschen gilt, da es sich um einen zusätzlichen Prozess handelt, der an der Algorithmuserstellung beteiligt ist. Das Erkennen und Beheben algorithmischer Fehler wird als Debugging bezeichnet.
Debugging ist eine übertragbare Fähigkeit, die im gesamten Lehrplan erworben werden kann, indem man auf Aktionen reagiert und Feedback gibt, ähnlich wie die anderen Komponenten des rechnerischen Denkens. Mithilfe von Algorithmen können wir unsere Umgebung verstehen.
Zusammenfassung
Zusammenfassend lässt sich sagen, dass die folgende Generation von Datenwissenschaftler müssen die Fähigkeiten erwerben, die es ihnen ermöglichen, sich erfolgreicher an den sich entwickelnden Arbeitsmarkt und die sich entwickelnde digitale Wirtschaft anzupassen.
Zukünftige Datenwissenschaftler werden computergestütztes Denken als nützliches Werkzeug empfinden, da sie ihre Positionen ständig ändern, um dem technologischen Fortschritt und mehr Interoperabilität zwischen Menschen und Maschinen Rechnung zu tragen.
Am Ende ist rechnerisches Denken für jeden bei seinen täglichen Aufgaben unerlässlich.





Hinterlassen Sie uns einen Kommentar