Indholdsfortegnelse[Skjule][At vise]
Fremtiden er her. Og i denne fremtid forstår maskiner verden omkring dem på samme måde, som mennesker gør. Computere kan køre biler, diagnosticere sygdomme og præcist forudsige fremtiden.
Dette kan virke som science fiction, men deep learning-modeller gør det til en realitet.
Disse sofistikerede algoritmer afslører hemmelighederne kunstig intelligens, hvilket giver computere mulighed for selv at lære og udvikle sig. I dette indlæg vil vi dykke ned i de dybe læringsmodeller.
Og vi vil undersøge det enorme potentiale, de har for at revolutionere vores liv. Forbered dig på at lære om banebrydende teknologi, der ændrer menneskehedens fremtid.

Hvad er Deep Learning-modeller helt præcist?
Har du nogensinde spillet et spil, hvor du skal identificere forskellene mellem to billeder?
Det er sjovt, men det kan også være hårdt, ikke? Forestil dig at være i stand til at lære en computer at spille det spil og vinde hver gang. Deep learning-modeller opnår netop det!
Deep learning-modeller ligner super-smarte maskiner, der kan undersøge et stort antal billeder og bestemme, hvad de har til fælles. De opnår dette ved at skille billederne ad og studere hver enkelt individuelt.
De anvender derefter det, de har lært, til at identificere mønstre og lave forudsigelser om friske billeder, de aldrig har set før.

Deep learning-modeller er kunstige neurale netværk, der kan lære og udtrække komplicerede mønstre og karakteristika fra massive datasæt. Disse modeller består af flere lag af sammenkædede noder eller neuroner, der analyserer og ændrer indgående data for at generere et output.
Deep learning-modeller er særligt velegnede til job, der kræver stor nøjagtighed og præcision, såsom billedidentifikation, talegenkendelse, naturlig sprogbehandling og robotteknologi.
De er blevet brugt i alt fra selvkørende biler til medicinsk diagnostik, anbefalingssystemer og predictive analytics.
Her er en forenklet version af visualiseringen for at illustrere dataflow i en dyb læringsmodel.
Inputdataene flyder ind i modellens inputlag, som derefter sender dataene gennem en række skjulte lag, før de giver en outputforudsigelse.
Hvert skjult lag udfører en række matematiske operationer på inputdataene, før de overføres til det næste lag, som giver den endelige forudsigelse.
Lad os nu se, hvad deep learning-modeller er, og hvordan vi kan bruge dem i vores liv.
1. Convolutional Neural Networks (CNN'er)
CNN'er er en dyb læringsmodel, der har transformeret området for computersyn. CNN'er bruges til at klassificere billeder, genkende objekter og segmentere billeder. Strukturen og funktionen af den menneskelige visuelle cortex informerede designet af CNN'er.
Hvordan fungerer de?
Et CNN består af et antal foldningslag, poolinglag og fuldt forbundne lag. Inputtet er et billede, og outputtet er en forudsigelse af billedets klasselabel.
Et CNN's foldningslag bygger et funktionskort ved at udføre et prikprodukt mellem inputbilledet og et sæt filtre. Poolinglagene sænker størrelsen af featurekortet ved at nedsample det.
Endelig bruges funktionskortet af de fuldt forbundne lag til at forudsige billedets klassebetegnelse.

Hvorfor er CNN'er vigtige?
CNN'er er essentielle, fordi de kan lære at opdage mønstre og karakteristika i billeder, som folk har svært ved at lægge mærke til. CNN'er kan læres at genkende karakteristika som kanter, hjørner og teksturer ved hjælp af store datasæt. Efter at have lært disse egenskaber, kan en CNN bruge dem til at identificere objekter i friske billeder. CNN'er har demonstreret banebrydende ydeevne på en række forskellige billedidentifikationsapplikationer.
Hvor bruger vi CNN'er
Sundhedspleje, bilindustrien og detailhandel er blot nogle få sektorer, der beskæftiger CNN'er. I sundhedssektoren kan de være gavnlige til sygdomsdiagnostik, medicinudvikling og medicinsk billedanalyse.
I bilsektoren hjælper de med vognbaneregistrering, objektdetektionog autonom kørsel. De er også meget brugt i detailhandlen til visuel søgning, billedbaseret produktanbefaling og lagerstyring.
For eksempel; Google bruger CNN'er i en række forskellige applikationer, bl.a Google Lens, et vellidt billedidentifikationsværktøj. Programmet bruger CNN'er til at evaluere fotografier og give brugerne oplysninger.
Google Lens kan for eksempel genkende ting i et billede og tilbyde detaljer om dem, såsom typen af blomst.

Det kan også oversætte teksten, der er udtrukket fra et billede, til flere sprog. Google Lens er i stand til at give forbrugerne nyttige oplysninger på grund af CNN'ers hjælp til nøjagtigt at identificere genstande og udtrække karakteristika fra fotos.
2. Long Short-Term Memory (LSTM) netværk
LSTM-netværk (Long Short-Term Memory) oprettes for at afhjælpe manglerne ved regulære tilbagevendende neurale netværk (RNN'er). LSTM-netværk er ideelle til opgaver, der kræver behandling af datasekvenser på tværs af tid.
De fungerer ved at anvende en specifik hukommelsescelle og tre portmekanismer.
De regulerer strømmen af information ind og ud af cellen. Indgangsporten, glemporten og udgangsporten er de tre porte.
Indgangsporten regulerer strømmen af data ind i hukommelsescellen, glemmeporten regulerer sletningen af data fra cellen, og outputporten regulerer strømmen af data ud af cellen.
Hvad er deres betydning?
LSTM-netværk er nyttige, fordi de med succes kan repræsentere og forudsige datasekvenser med langsigtede relationer. De kan registrere og opbevare information om tidligere input, så de kan lave mere præcise forudsigelser om fremtidige input.
Talegenkendelse, håndskriftsgenkendelse, naturlig sprogbehandling og billedtekstning er blot nogle få af de programmer, der har gjort brug af LSTM-netværk.
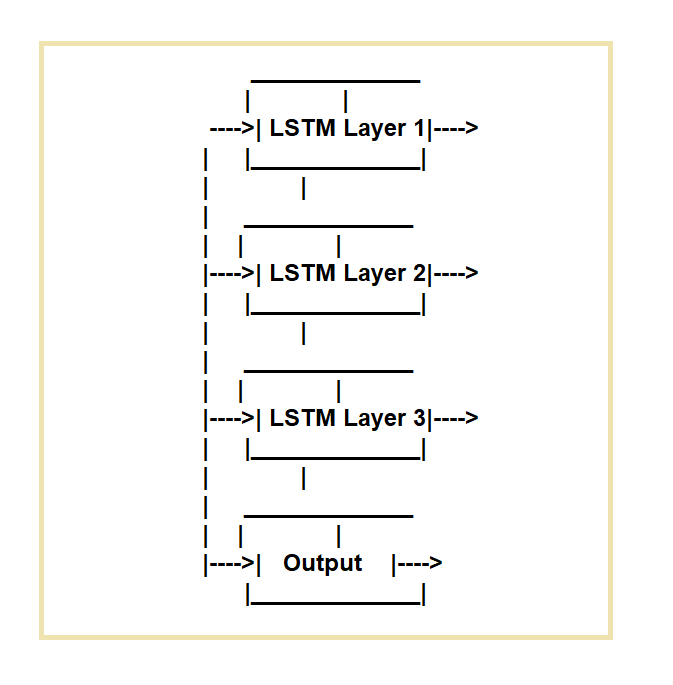
Hvor bruger vi LSTM-netværk?
Mange software- og teknologiapplikationer anvender LSTM-netværk, herunder talegenkendelsessystemer, værktøjer til behandling af naturlige sprog som f.eks. følelser analyse, maskinoversættelsessystemer og tekst- og billedgenereringssystemer.
De er også blevet brugt i skabelsen af selvkørende biler og robotter, såvel som i finansindustrien til at opdage svindel og forudse aktiemarkedet bevægelser.
3. Generative Adversarial Networks (GAN'er)
GAN'er er en dyb læring teknik, der bruges til at generere nye dataeksempler, der ligner et givet datasæt. GAN'er består af to neurale netværk: en, der lærer at producere nye prøver og en, der lærer at skelne mellem ægte og genererede prøver.
I en lignende tilgang trænes disse to netværk sammen, indtil generatoren kan generere prøver, der ikke kan skelnes fra faktiske.
Hvorfor bruger vi GAN'er
GAN'er er vigtige på grund af deres evne til at producere høj kvalitet syntetiske data som kan bruges til en række applikationer, herunder billed- og videoproduktion, tekstgenerering og endda musikgenerering.
GAN'er er også blevet brugt til dataforøgelse, som er genereringen af syntetiske data at supplere virkelige data og forbedre ydeevnen af maskinlæringsmodeller.
Ved at skabe syntetiske data, der kan bruges til at træne modeller og efterligne forsøg, har GAN'er desuden potentialet til at transformere sektorer som medicin og lægemiddeludvikling.

Anvendelser af GAN'er
GAN'er kan supplere datasæt, skabe nye billeder eller film og endda generere syntetiske data til videnskabelige simuleringer. Desuden har GAN'er potentialet til at blive ansat i en række forskellige applikationer lige fra underholdning til medicinsk.
aldre og videoer. NVIDIAs StyleGAN2 er for eksempel blevet brugt til at skabe højkvalitetsfotografier af berømtheder og kunstværker.
4. Deep Belief Networks (DBN'er)
Deep Belief Networks (DBN'er) er kunstig intelligens systemer, der kan lære at spotte mønstre i data. De opnår dette ved at segmentere dataene i mindre og mindre bidder, og få et mere grundigt greb om det på hvert niveau.
DBN'er kan lære af data uden at blive informeret om, hvad det er (dette omtales som "uovervåget læring"). Dette gør dem ekstremt værdifulde til at opdage mønstre i data, som en person ville finde vanskelige eller umulige at gennemskue.
Hvad gør DBN'er væsentlige?
DBN'er er vigtige på grund af deres evne til at lære hierarkiske datarepræsentationer. Disse repræsentationer kan bruges til en række forskellige applikationer som klassificering, anomalidetektion og dimensionsreduktion.
DBN'ers kapacitet til at gennemføre uovervåget fortræning, som kan øge ydeevnen af deep learning-modeller med minimalt mærkede data, er en væsentlig fordel.

Hvad er anvendelserne af DBN'er?
En af de mest betydningsfulde applikationer er objektdetektion, hvor DBN'er bruges til at genkende visse typer ting såsom flyvemaskiner, fugle og mennesker. De bruges også til billedgenerering og -klassificering, bevægelsesdetektion i film og naturlig sprogforståelse til stemmebehandling.
Desuden er DBN'er almindeligvis anvendt i datasæt til at vurdere menneskelige stillinger. DBN'er er et fantastisk værktøj til en række forskellige industrier, herunder sundhedspleje og bankvirksomhed og teknologi.
5. Deep Reinforcement Learning Networks (DRL'er)
Dyb Forstærkningslæring Netværk (DRL'er) integrerer dybe neurale netværk med forstærkende læringsteknikker for at give agenter mulighed for at lære i et kompliceret miljø via forsøg og fejl.
DRL'er bruges til at lære agenter, hvordan de optimerer et belønningssignal ved at interagere med deres omgivelser og lære af deres fejl.
Hvad gør dem bemærkelsesværdige?
De er blevet brugt effektivt i en række applikationer, herunder spil, robotteknologi og autonom kørsel. DRL'er er vigtige, fordi de kan lære direkte af rå sensoriske input, hvilket giver agenter mulighed for at træffe beslutninger baseret på deres interaktioner med miljøet.
Vigtige applikationer
DRL'er anvendes under virkelige omstændigheder, fordi de kan håndtere vanskelige problemer.
DRL'er er blevet inkluderet i flere fremtrædende software- og teknologiplatforme, herunder OpenAI's Gym, Unitys ML-agenter, og Googles DeepMind Lab. AlphaGo, bygget af Google DeepMind, for eksempel ansætter DRL til at spille brætspillet Go på verdensmesterniveau.

En anden anvendelse af DRL er inden for robotteknologi, hvor den bruges til at kontrollere robotarmenes bevægelser til at udføre opgaver såsom at gribe ting eller stable blokke. DRL'er har mange anvendelsesmuligheder og er et nyttigt værktøj til træne agenter til at lære og træffe beslutninger i komplicerede omgivelser.
6. Autoencodere
Autoencodere er en interessant type neurale netværk som har fanget både forskeres og dataforskeres interesse. De er grundlæggende designet til at lære at komprimere og gendanner data.
Inputdataene føres gennem en række af lag, der gradvist sænker dimensionaliteten af dataene, indtil de komprimeres til et flaskehals-lag med færre noder end input- og outputlagene.
Denne komprimerede repræsentation bruges derefter til at genskabe de originale inputdata ved hjælp af en sekvens af lag, der gradvist hæver dataens dimensionalitet tilbage til dens oprindelige form.
Hvorfor er det vigtigt?
Autoencodere er en afgørende komponent i dyb læring fordi de gør udtræk af funktioner og datareduktion mulig.
De er i stand til at identificere nøgleelementerne i de indgående data og oversætte dem til en komprimeret form, der derefter kan anvendes til andre opgaver som klassificering, gruppering eller oprettelse af nye data.
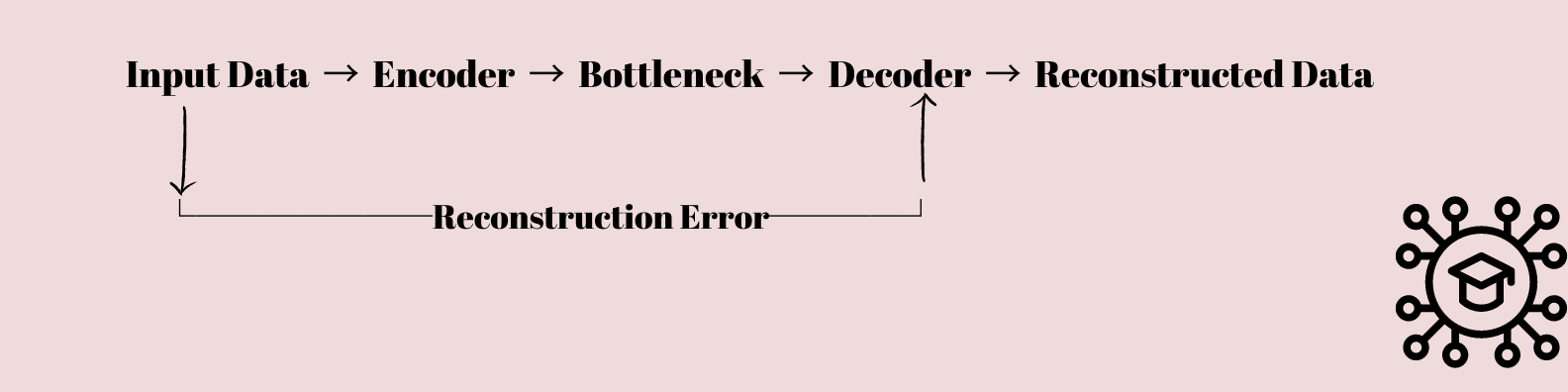
Hvor bruger vi autoencodere?
Anomalidetektion, naturlig sprogbehandling og computersyn er blot nogle få af de discipliner, hvor autoencodere bruges. Autoencodere kan for eksempel bruges til billedkomprimering, billednedbrydning og billedsyntese i computervision.
Vi kan bruge Autoencoders i opgaver som tekstoprettelse, tekstkategorisering og tekstresumé i naturlig sprogbehandling. Det kan identificere uregelmæssig aktivitet i data, der afviger fra normen i uregelmæssig identifikation.
7. Kapselnetværk
Capsule Networks er en ny deep learning-arkitektur, der blev udviklet som en erstatning for Convolutional Neural Networks (CNN'er).
Kapselnetværk er baseret på ideen om at gruppere hjerneenheder kaldet kapsler, der er ansvarlige for at genkende eksistensen af et bestemt element i et billede og indkode dets attributter, såsom orientering og position, i deres outputvektorer. Capsule Networks kan derfor håndtere rumlige interaktioner og perspektivudsving bedre end CNN'er.
Hvorfor vælger vi Capsule Networks frem for CNN's?
Capsule Networks er nyttige, fordi de overvinder CNN's vanskeligheder med at fange hierarkiske forhold mellem elementer i et billede. CNN'er kan genkende ting af forskellige størrelser, men har svært ved at forstå, hvordan disse genstande forbindes med hinanden.
Capsule Networks, på den anden side, kan lære at genkende ting og deres stykker, såvel som hvordan de placeres rumligt i et billede, hvilket gør dem til en levedygtig udfordrer til computervision-applikationer.
Anvendelsesområder
Capsule Networks har allerede vist lovende resultater inden for en række forskellige applikationer, herunder billedklassificering, objektidentifikation og billedsegmentering.
De er blevet brugt til at skelne ting på medicinske fotos, genkende mennesker i film og endda skabe 3D-modeller ud fra 2D-billeder.
For at øge deres ydeevne er Capsule Networks blevet kombineret med andre deep learning-arkitekturer såsom Generative Adversarial Networks (GAN'er) og Variational Autoencoders (VAE'er). Capsule Networks forventes at spille en stadig vigtigere rolle i at forbedre computervisionsteknologier, efterhånden som videnskaben om dyb læring udvikler sig.
For eksempel; Nibabel er et velkendt Python-værktøj til at læse og skrive neuroimaging filtyper. Til billedsegmentering anvender den Capsule Networks.
8. Opmærksomhedsbaserede modeller
Deep learning-modeller kendt som opmærksomhedsbaserede modeller, også kendt som opmærksomhedsmekanismer, stræber efter at øge nøjagtigheden af maskinlæringsmodeller. Disse modeller fungerer ved at koncentrere sig om visse funktioner i indgående data, hvilket resulterer i mere effektiv og effektiv behandling.
I naturlige sprogbehandlingsopgaver som maskinoversættelse og sentimentanalyse har opmærksomhedsmetoder vist sig at være ret vellykkede.
Hvad er deres betydning?
Opmærksomhedsbaserede modeller er nyttige, fordi de muliggør en mere effektiv og effektiv behandling af komplicerede data.
Traditionelle neurale netværk vurdere alle inputdata som lige vigtige, hvilket resulterer i langsommere behandling og nedsat nøjagtighed. Opmærksomhedsprocesser koncentrerer sig om vigtige aspekter af inputdata, hvilket giver mulighed for hurtigere og mere præcise forudsigelser.

Anvendelsesområder
Inden for kunstig intelligens har opmærksomhedsmekanismer en bred vifte af anvendelser, herunder naturlig sprogbehandling, billed- og lydgenkendelse og endda førerløse køretøjer.
Opmærksomhedsmetoder kan for eksempel bruges til at forbedre maskinoversættelse i naturlig sprogbehandling ved at lade systemet fokusere på bestemte ord eller sætninger, der er essentielle for konteksten.
Opmærksomhedsmetoder i autonome biler kan bruges til at hjælpe systemet med at fokusere på bestemte emner eller udfordringer i omgivelserne.
9. Transformer netværk
Transformernetværk er deep learning-modeller, der undersøger og producerer datasekvenser. De fungerer ved at behandle inputsekvensen ét element ad gangen og producere en outputsekvens af samme eller forskellige længder.
Transformernetværk behandler, i modsætning til standardsekvens-til-sekvens-modeller, ikke sekvenser ved hjælp af tilbagevendende neurale netværk (RNN'er). I stedet bruger de selvopmærksomhedsprocesser for at lære sammenhængene mellem sekvensens stykker.
Hvad er betydningen af transformatornetværk?
Transformer-netværk er vokset i popularitet i de seneste år som et resultat af deres bedre ydeevne i naturlige sprogbehandlingsjob.
De er særligt velegnede til tekstskabelsesopgaver som sprogoversættelse, tekstresumé og samtaleproduktion.
Transformatornetværk er betydeligt mere effektive beregningsmæssigt end RNN-baserede modeller, hvilket gør dem til et foretrukket valg til store applikationer.

Hvor kan du finde Transformer Networks?
Transformatornetværk er meget udbredt i en bred vifte af applikationer, især naturlig sprogbehandling.
GPT-serien (Generative Pre-trained Transformer) er en fremtrædende transformer-baseret model, der er blevet brugt til opgaver som sprogoversættelse, tekstresumé og chatbotgenerering.
BERT (Bidirectional Encoder Representations from Transformers) er en anden almindelig transformer-baseret model, der er blevet brugt til naturlige sprogforståelsesapplikationer såsom besvarelse af spørgsmål og sentimentanalyse.
Både GPT og BERT blev skabt med PyTorch, en open source-deep-learning-ramme, der har været populær til udvikling af transformatorbaserede modeller.
10. Begrænsede Boltzmann-maskiner (RBM'er)
Begrænsede Boltzmann-maskiner (RBM'er) er en slags uovervåget neuralt netværk, der lærer på en generativ måde. På grund af deres evne til at lære og udtrække væsentlige egenskaber fra højdimensionelle data, har de været udbredt ansat inden for maskinlæring og deep learning.
RBM'er består af to lag, synlige og skjulte, hvor hvert lag består af en gruppe neuroner forbundet med vægtede kanter. RBM'er er designet til at lære en sandsynlighedsfordeling, der beskriver inputdataene.
Hvad er begrænsede Boltzmann-maskiner?
RBM'er anvender en generativ læringsstrategi. I RBM'er afspejler det synlige lag inputdataene, mens det nedgravede lag koder for inputdataens karakteristika. Vægten af de synlige og skjulte lag viser styrken af deres led.
RBM'er justerer vægten og skævhederne mellem lagene under træning ved hjælp af en teknik kendt som kontrastiv divergens. Kontrastiv divergens er en uovervåget læringsstrategi, der maksimerer modellens forudsigelsessandsynlighed.
Hvad er betydningen af begrænsede Boltzmann-maskiner?
RBM'er er betydelige i machine learning og dyb læring, fordi de kan lære og udtrække relevante karakteristika fra store mængder data.
De er meget effektive til billed- og talegenkendelse, og de er blevet brugt i en række forskellige applikationer, såsom anbefalingssystemer, anomalidetektion og dimensionsreduktion. RBM'er kan finde mønstre i store datasæt, hvilket resulterer i overlegne forudsigelser og indsigter.

Hvor kan begrænsede Boltzmann-maskiner bruges?
Ansøgninger om RBM'er omfatter dimensionsreduktion, anomalidetektion og anbefalingssystemer. RBM'er er særligt nyttige til sentimentanalyse og emnemodellering i forbindelse med naturlig sprogbehandling.
Deep belief-netværk, en slags neurale netværk, der bruges til stemme- og billedgenkendelse, anvender også RBM'er. The Deep Belief Network Toolbox, TensorFlowog Theano er nogle særlige eksempler på software eller teknologi, der bruger RBM'er.
Wrap Up
Deep Learning-modeller bliver mere og mere afgørende i en række forskellige brancher, herunder talegenkendelse, naturlig sprogbehandling og computersyn.
Convolutional Neural Networks (CNN'er) og Recurrent Neural Networks (RNN'er) har vist det mest lovende og er flittigt brugt i mange applikationer, dog har alle Deep Learning-modeller deres fordele og ulemper.
Forskere undersøger dog stadig begrænsede Boltzmann-maskiner (RBM'er) og andre varianter af Deep Learning-modeller, fordi de også har særlige fordele.
Nye og kreative modeller forventes at blive skabt, efterhånden som området for dyb læring fortsætter med at udvikle sig for at håndtere sværere problemer





Giv en kommentar