Indholdsfortegnelse[Skjule][At vise]
Data er overalt omkring dig. I en reel forstand påvirker det alle aspekter af din virksomhed. Det kan føles, som om der ikke er tid nok til at undersøge detaljerne om, hvor godt det tjener din virksomhed, når du er optaget af beslutninger om, hvordan du skal håndtere dine data.
Bemærk dette. Din organisation bruger data 24 timer i døgnet. Så det er afgørende at forstå, hvor det kom fra, hvordan det kom dertil, og hvordan det bevæger sig gennem virksomheden, for at forstå dets værdi.
Dataafstamning bliver vigtig i denne situation. Det er lettere at forstå, hvordan data blev dannet, hvor de kom fra, og hvor de er på vej hen, når vi kan spore oprindelsen, migreringerne og ændringerne af dataene.
I dette indlæg vil vi se nærmere på Data Lineage, hvordan det virker, dets anvendelsesmuligheder, teknikker og meget mere.
Hvad er Data Lineage?
Dataafstamning fungerer som en slags digitalt pas. Det er den mest omfattende beretning om en datarejse, der beskriver alle dens stop, omveje og ændringer fra dens oprindelse til dens endelige destination.
Ii bund og grund beskriver datalinje oprindelsen, ændringen og brugen af et stykke data på tværs af mange systemer og platforme. Det fungerer som et detektivværktøj ved at give brugerne information om, hvordan data blev produceret, hvor det stammer fra, og hvordan det blev brugt. Disse oplysninger gør det muligt for brugerne at genkende og løse eventuelle problemer.
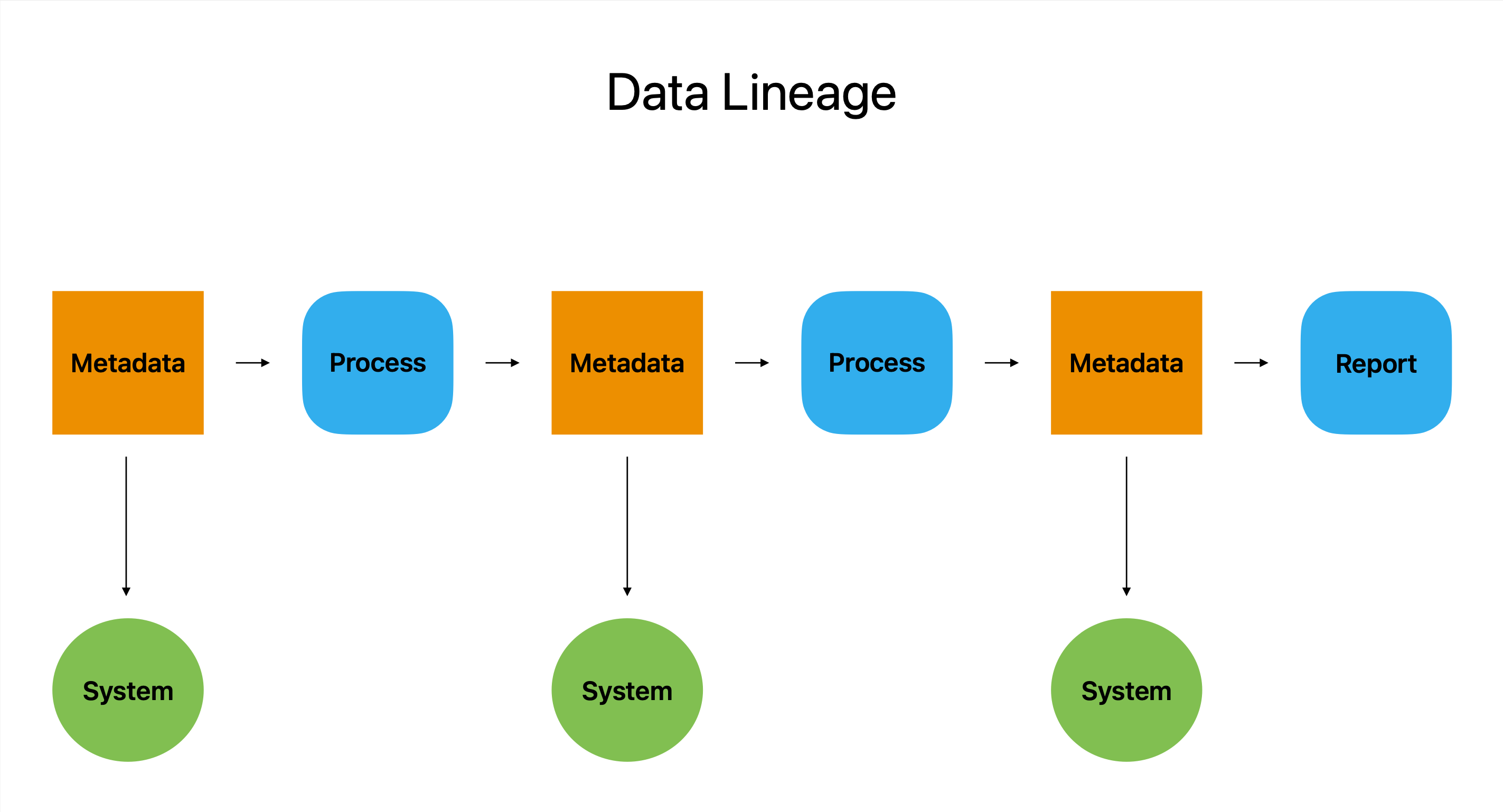
Dataafstamning er en uvurderlig ressource for virksomheder, der er afhængige af data for at drive deres drift, fordi det giver brugerne mulighed for at svare på afgørende spørgsmål som hvem, hvad, hvornår og hvor.
Dataafstamning er, for at sige det enkelt, det ultimative dataspor, der garanterer datanøjagtighed, fuldstændighed og konsistens, samtidig med at det tilbyder et klart og kortfattet perspektiv af en datas fulde vej.
Hvordan fungerer Data Lineage?
Dataafstamning er den køreplan, der gør os i stand til at følge et stykke data fra dets startpunkt til dets endepunkt. Betragt et datapunkt som en rejsende, og dets pas som dets datalinje for bedre at forstå, hvordan det fungerer.
Datakilder, datatransformation, datalagring og dataoutput udgør passets fire primære komponenter.
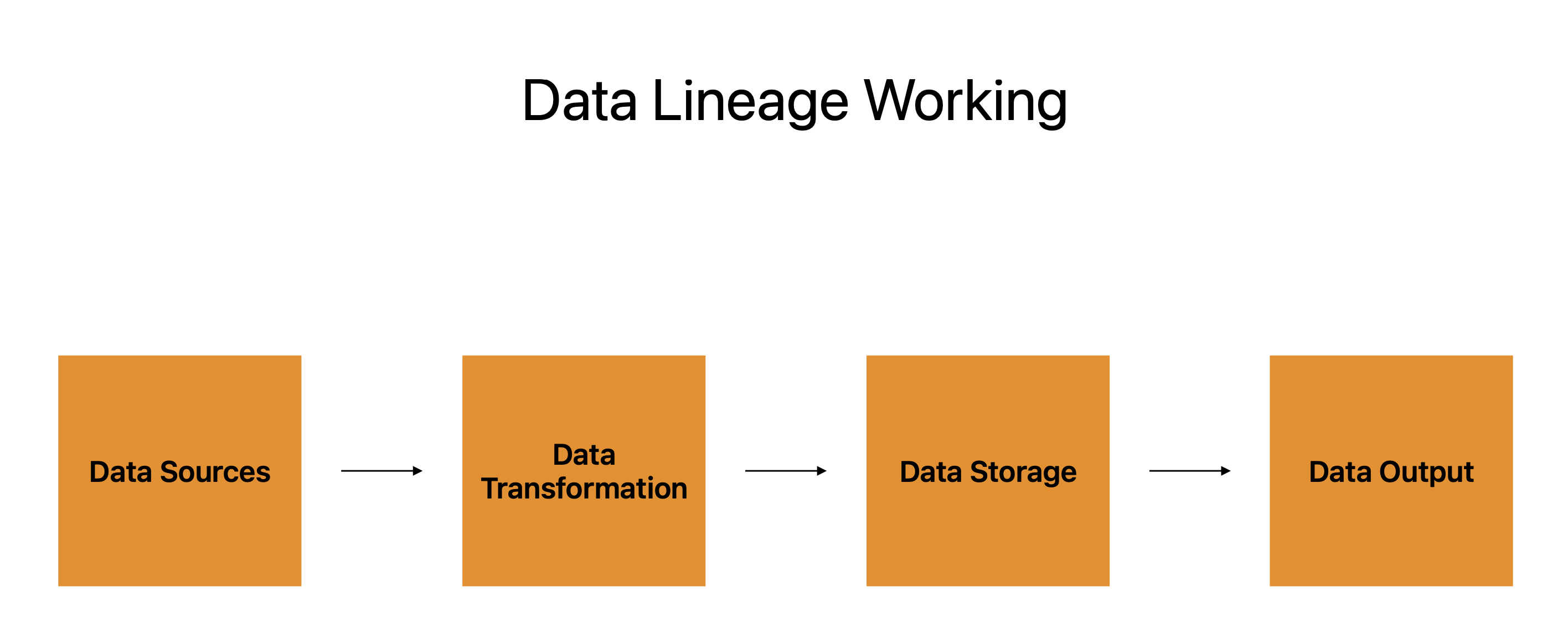
De mange systemer, applikationer og platforme, som dataene stammer fra, er repræsenteret af datakilder, som fungerer som udgangspunkt for dataens rejse. Datatransformation er den efterfølgende fase, og dataafstamning kortlægger dataens progression fra disse kilder til dem.
Datatransformation refererer til formning, ændring og manipulation af data for at imødekomme brugernes behov. Den fungerer som et hvilestop under dataens tur, der forbereder det til næste etape.
Dataene gemmes derefter, før de går til deres endelige placering. Det kan opbevares på cloud-servere, databaser eller en anden form for lagerenhed. Dataafstamning holder styr på, hvor dataene er gemt, samt hvordan de beskyttes, sikkerhedskopieres og gendannes.
Det sidste trin er dataoutput, som er, hvor dataene sendes til brug. Rapporter, infografik eller enhver anden type dataprodukt kan bruges til at præsentere det. Dataafstamning holder styr på outputtet og garanterer konsistensen, nøjagtigheden og fuldstændigheden af dataene.
Dataafstamning fungerer dybest set ved at registrere hvert trin af dataens rejse, fra dets begyndelse til dets output, og sikre, at det forbliver pålideligt, konsistent og korrekt hele vejen igennem. Dataafstamning hjælper organisationer med at træffe kvalificerede beslutninger, løse problemer og overholde juridiske forpligtelser ved at give et fuldt overblik over en datas eksistens.
For at forstå dataaktiverne, og hvordan de bevæger sig gennem datapipelinen, er metadata en afgørende del af dataafstamningsprocessen.
Du kan se, hvordan data konverteres og bruges i organisationen ved hjælp af datalinjeværktøjer, som udnytter metadata til at give en visuel skildring af datastrømmen. Dette gør det muligt for brugerne at vurdere dataens potentiale, hvilket hjælper dem med at træffe bedre informerede beslutninger.
Typer af dataafstamning
Der er tre grundlæggende former for dataafstamning: fremadgående dataafstamning, bagudgående dataafstamning og tovejs dataafstamning.
Videresend datalinje
Som med en ensrettet gade involverer fremadgående datalinje sporing af et stykke data fra dets startpunkt til dets slutpunkt. Begyndende fra datakilden følger den dataene, når de passerer gennem flere transformationer og lagersystemer for at nå deres output.
Forståelse af behandling og transformation af data samt eventuelle problemer, der måtte være opstået undervejs, lettes ved at have en datalinje af denne art. Hvert skridt fører til det næste; det er som at følge et spor af brødkrummer.
Baglæns datalinje
Baglæns datalinje ligner en rejse omvendt, hvor vi sporer dataens output tilbage til kilden. Processen begynder ved dataens endelige placering og bevæger sig baglæns gennem en række forskellige lagrings- og transformationsteknikker, indtil den når datakilden.
Identifikation af dataens oprindelige kilde, forståelse af deres transformation og verifikation af dens rigtighed og fuldstændighed er alle mulige ved hjælp af denne type datalinje. Det fungerer som en detektivs værktøj, der giver os mulighed for at følge dataenes vej baglæns.
Tovejs datalinje
En tovejs, tovejs datalinje kombinerer fordelene ved fremadgående og bagudgående datalinje. Det giver et omfattende overblik over ruten for dataene ved at spore dem fra dets kilde til dets destination såvel som fra det pågældende sted til dets udgangspunkt.
For at bestemme dataens oprindelige kilde, forstå, hvordan de blev ændret, og garantere dets kvalitet, konsistens og fuldstændighed hele vejen, er det nyttigt at spore dataens afstamning. Med realtidsinformation om dens placering og status er det som at have en GPS-tracker til data.
Implementering af Data Lineage
Implementering af datalinje i en organisation involverer ofte følgende faser.
Definer datakilderne
De systemer og databaser, der indeholder de data, du ønsker at spore, bør alle identificeres. For at gøre dette skal du først identificere de forskellige datakilder, herunder filer, API'er og cloud-tjenester.
Indsaml metadata
Det næste trin er at indhente detaljer om dataene, herunder dets placering, format og organisation. Forståelse af dataenes funktioner og hvordan de bruges, er muliggjort af disse metadata.
Identificer datafejl
Det er nemmere at forstå, hvordan data opdateres og bruges i organisationen, hvis datastrømmen kortlægges fra kilden til destinationen, inklusive enhver transformation eller behandling, der finder sted langs ruten.
Spor dataadgang
For at opretholde datasikkerhed og overholdelse skal du spore og registrere, hvem der har adgang til dataene.
Opbevar og visualiser slægten
Brug visualiseringsværktøjer til at præsentere slægten for enkel forståelse og analyse. Gem de indsamlede metadata og dataflowoplysninger i et enkelt lager.
Implementer en automatiseret løsning
Du kan bekræfte, at dataafstamning bliver indsamlet og overvåget gennem automatisering, hvilket også vil hjælpe med at skære ned på fejl og øge produktiviteten.
Gennemgå & Opdater
Sørg for, at slægtsposterne er korrekte og aktuelle med jævne mellemrum, og opdater dem efter behov.
Implementeringsprocessen skal muligvis ændres eller føjes til faser afhængigt af de unikke krav og begrænsninger for hver organisation.
Dataafstamningsteknikker
Mønsterbaseret afstamning
Med denne metode udføres lineage uden at skulle interagere med den programmering, der genererede eller transformerede dataene. Metadatavurdering for tabeller, kolonner og forretningsrapporter er alle en del af det. Den udforsker afstamning ved at lede efter trends ved hjælp af disse metadata.
For eksempel er det ret sandsynligt, at en kolonne i to datasæt med samme navn og identiske dataværdier repræsenterer de samme data i forskellige faser af dens eksistens. Et datalinjediagram bruges derefter til at forbinde disse to kolonner.
Mønsterbaseret afstamning har den væsentlige fordel ved at være teknologiuafhængig, fordi den kun tjekker data, ikke databehandlingsmetoder. Enhver databaseteknologi, inklusive Oracle, MySQL og Spark, kan implementere det på samme måde. Ulempen er, at denne tilgang ikke altid er præcis.
Når databehandlingslogikken er skjult i computerkoden og ikke umiddelbart indlysende i menneskelæselige metadata, kan den lejlighedsvis overse forhold mellem datasæt.
Afstamning ved datamærkning
Denne metode er baseret på ideen om, at en transformationsmotor tagger eller på anden måde markerer data. Den sporer mærket fra start til slut for at finde afstamning. Denne tilgang kan kun lykkes, hvis du har et pålideligt transformationsværktøj, der styrer al dataoverførsel, og du er bekendt med tagging-strukturen, som værktøjet anvender.
Selv hvis et sådant værktøj skulle eksistere, kunne ingen data, der blev oprettet eller ændret uden det, udsættes for afstamning via datamærkning. Det er begrænset i denne henseende til at udføre datalinje på lukkede datasystemer.
Selvstændig afstamning
Nogle virksomheder har et datamiljø, der inkluderer metadatalagring, behandlingslogik og masterdata management (MDM). Disse indstillinger inkluderer ofte en data sø hvor alle data opbevares i hele dens levetid.
Afstamning kan naturligvis leveres af denne form for selvstændigt system uden krav om yderligere ressourcer. Men ligesom med datamærkningsmetoden vil afstamning ikke være opmærksom på noget, der forekommer uden for dette regulerede miljø.
Dataafstamning ved parsing
Den mest sofistikerede type afstamning er en, der læser databehandlingslogik automatisk. For grundig, ende-til-ende-sporing omvendt manipulerer denne metode datatransformationslogikken.
Da denne løsning skal forstå alle de programmeringssprog og værktøjer, der bruges til at konvertere og transportere dataene, er implementeringen kompliceret. Dette kan bruge ETL-logik (extract-transform-load), SQL- og Java-baserede løsninger, gamle dataformater, XML-baserede løsninger og andre teknikker.
Dataafstamningsbrug
Datamodellering
Virksomheder skal etablere de underliggende datastrukturer, der understøtter dem, for at visualisere de mange dataelementer og sammenhængen mellem dem inde i en virksomhed. Disse forbindelser er modelleret ved hjælp af datalinje, som også viser de mange afhængigheder, der findes i dataøkosystemet.
Da data ændrer sig over tid, opstår der konstant nye datakilder, som kræver nye dataintegrationer osv. Derfor skal virksomheders generelle datamodeller til håndtering af deres data ligeledes ændre sig, så de afspejler miljøet.
Overholdelse
Datalinje tilbyder en overholdelsesmetode til revision, forbedring af risikostyring og sikring af, at data opbevares og håndteres i overensstemmelse med datastyringspolitikker og love.
Effektanalyse
Effekterne af visse forretningsændringer, såsom enhver downstream-rapportering, kan ses ved hjælp af datalinjeværktøjer. Dataafstamning kan f.eks. hjælpe ledere med at bestemme, hvor mange dashboards en navneændring vil påvirke og følgelig, hvor mange personer der får adgang til denne rapportering.
Dataoverførsel
Organisationer anvender datamigrering for at forstå, hvor dataene er placeret, og hvor længe de har været der, før de flyttes til et nyt lagersystem eller implementerer ny software.
Dataafstamning hjælper teams med at forberede sig på systemopgraderinger eller migreringer ved at give dem et overblik over, hvordan dataene har flyttet sig i hele organisationen. Dette fremskynder overførslen til det nye lagermiljø generelt.
Derudover giver det teams mulighed for at rydde op i datasystemet ved at arkivere eller eliminere forældede eller ubrugelige data. Ved at gøre det vil datasystemet generelt fungere bedre og kræve mindre styring af data.
Udfordringer ved at implementere datalinje
- Datasikkerhed: Datasikkerhed er en primær bekymring, mens du opbygger dataafstamning. For at følge en datarejse fra startpunkt til slutdestination skal der gives adgang til følsomme data, og disse data skal beskyttes mod uautoriseret adgang og brud.
- Manglende standardisering: En af de primære barrierer for at omfavne datalinje er manglen på standarder. Da mange platforme, apps og systemer anvender unikke metoder til at spore og registrere data herkomst, kan det være svært at sammensætte et sammenhængende billede af en datarejse.
- Datasiloer: Datasiloer er et andet problem, der opstår under implementering af datalinje. Når data er spredt på tværs af flere applikationer og systemer, kan det være udfordrende at spore deres rejse fra den ene til den anden. Dette kan føre til unøjagtige eller ufuldstændige dataafstamning.
Konklusion
Som konklusion er dataafstamning en væsentlig del af enhver datadrevet virksomhed. Det giver et omfattende perspektiv på en datas vej fra dets startpunkt til dets slutpunkt, hvilket garanterer dets nøjagtighed, fuldstændighed og konsistens.
Fremtidige automatisering og standardisering af datalinjer forventes at stige, hvilket gør implementering og vedligeholdelse lettere for organisationer. I sidste ende kan betydningen af dataafstamning ikke understreges.
Det giver virksomheder de værktøjer, de skal bruge til at træffe kloge valg, drive deres drift mere effektivt og opnå succes.





Giv en kommentar