Obsah[Skrýt][Ukázat]
Techniky hlubokého učení známé jako „grafové neuronové sítě“ (GNN) fungují v doméně grafů. Tyto sítě v poslední době našly využití v různých oblastech, včetně počítačového vidění, doporučovacích systémů a kombinatorické optimalizace, abychom jmenovali alespoň některé.
Kromě toho lze tyto sítě použít k reprezentaci komplexních systémů, včetně sociálních sítí, interakčních sítí protein-protein, znalostních grafů a dalších v několika oborech.
Neeuklidovský prostor je místo, kde fungují grafová data, na rozdíl od jiných typů dat, jako jsou obrázky. Aby bylo možné klasifikovat uzly, predikovat vazby a shluková data, používá se grafová analýza.
V tomto článku se podíváme na graf Nervová síť podrobně, jeho typy, stejně jako poskytují praktické příklady pomocí PyTorch.
Co je tedy Graph?
Graf je typ datové struktury složený z uzlů a vrcholů. Spojení mezi různými uzly jsou určeny vrcholy. Pokud je v uzlech vyznačen směr, říká se, že graf je orientovaný; jinak je neorientovaný.
Dobrou aplikací grafů je modelování vztahů mezi různými jednotlivci v a sociální síť. Při řešení složitých okolností, jako jsou odkazy a výměny, jsou grafy velmi užitečné.
Používají je systémy doporučení, sémantická analýza, analýza sociálních sítí a rozpoznávání vzorů
. Vytváření řešení založených na grafech je zbrusu novým oborem, který nabízí pronikavé pochopení složitých a vzájemně souvisejících dat.
Graf neuronové sítě
Grafové neuronové sítě jsou specializované typy neuronových sítí, které mohou pracovat na datovém formátu grafu. Významný vliv na ně má vkládání grafů a konvoluční neuronové sítě (CNN).
Grafové neuronové sítě se používají v úlohách, které zahrnují predikci uzlů, hran a grafů.
- CNN se používají ke klasifikaci obrázků. Podobně pro predikci třídy se GNN aplikují na mřížku pixelů, která představuje strukturu grafu.
- Kategorizace textu pomocí rekurentních neuronových sítí. GNN se také používají s grafovými architekturami, kde každé slovo ve frázi je uzel.
Aby bylo možné předpovídat uzly, hrany nebo kompletní grafy, používají se k vytvoření GNN neuronové sítě. Předpověď na úrovni uzlu může například vyřešit problém, jako je detekce spamu.
Predikce spojení je typickým případem v systémech doporučování a může být příkladem problému s předpovědí na okrajích.
Graf typů neuronových sítí
Existuje mnoho typů neuronových sítí a konvoluční neuronové sítě jsou přítomny ve většině z nich. V tomto díle se seznámíme s nejznámějšími GNN.
Graf konvolučních sítí (GCN)
Jsou srovnatelné s klasickými CNN. Charakteristiky získává pohledem na blízké uzly. Aktivační funkci používají GNN k přidání nelinearity po agregaci uzlových vektorů a odeslání výstupu do husté vrstvy.
Skládá se z konvoluce grafu, lineární vrstvy a v podstatě neučící se aktivační funkce. Sítě GCN existují ve dvou hlavních variantách: spektrální konvoluční sítě a prostorové konvoluční sítě.
Graf Auto-Encoder Networks
Používá kodér, aby se naučil reprezentovat grafy, a dekodér, který se snaží rekonstruovat vstupní grafy. Existuje úzká vrstva spojující kodér a dekodér.
Vzhledem k tomu, že automatické kodéry odvádějí vynikající práci s vyvážením tříd, často se používají při predikci spojení.
Opakující se grafové neuronové sítě (RGNN)
V multirelačních sítích, kde má jeden uzel četné vztahy, se naučí optimální difúzní vzor a může spravovat grafy. Za účelem zvýšení plynulosti a snížení nadměrné parametrizace se v této formě grafové neuronové sítě používají regularizátory.
Aby bylo možné dosáhnout lepších výsledků, RGNN vyžadují menší výpočetní výkon. Používají se pro generování textu, rozpoznávání řeči, strojový překlad, popis obrázků, označování videa a sumarizaci textu.
Sítě GGNN (Gated Neural Graph Networks)
Pokud jde o dlouhodobé závislé úkoly, překonávají RGNN. Zahrnutím uzlových, okrajových a časových hradel na dlouhodobé závislosti vylepšují neuronové sítě s hradlovým grafem rekurentní grafové neuronové sítě.
Hradla fungují podobně jako Gated Recurrent Units (GRU) v tom, že se používají k vyvolání a zapomenutí dat v různých fázích.
Implementace Graph Neuron Network pomocí Pytorch
Konkrétní problém, na který se zaměříme, je běžný problém kategorizace uzlů. Máme velkou sociální síť tzv musae-github, který byl zkompilován z otevřeného API pro vývojáře GitHubu.
Hrany znázorňují vzájemné vztahy následovníků mezi uzly, které představují vývojáře (uživatele platformy), kteří mají hvězdičku alespoň v 10 úložištích (všimněte si, že slovo vzájemný označuje neorientovaný vztah).
Na základě umístění uzlu, úložišť označených hvězdičkou, zaměstnavatele a e-mailové adresy jsou načteny charakteristiky uzlu. Předpovídání, zda je uživatel GitHubu webový vývojář nebo a vývojář strojového učení je naším úkolem.
Jako základ pro tuto funkci cílení sloužila pracovní pozice každého uživatele.
Instalace PyTorch
Abychom mohli začít, musíme nejprve nainstalovat PyTorch. Můžete jej nakonfigurovat podle vašeho stroje zde. Tady je můj:
Import modulů
Nyní importujeme potřebné moduly
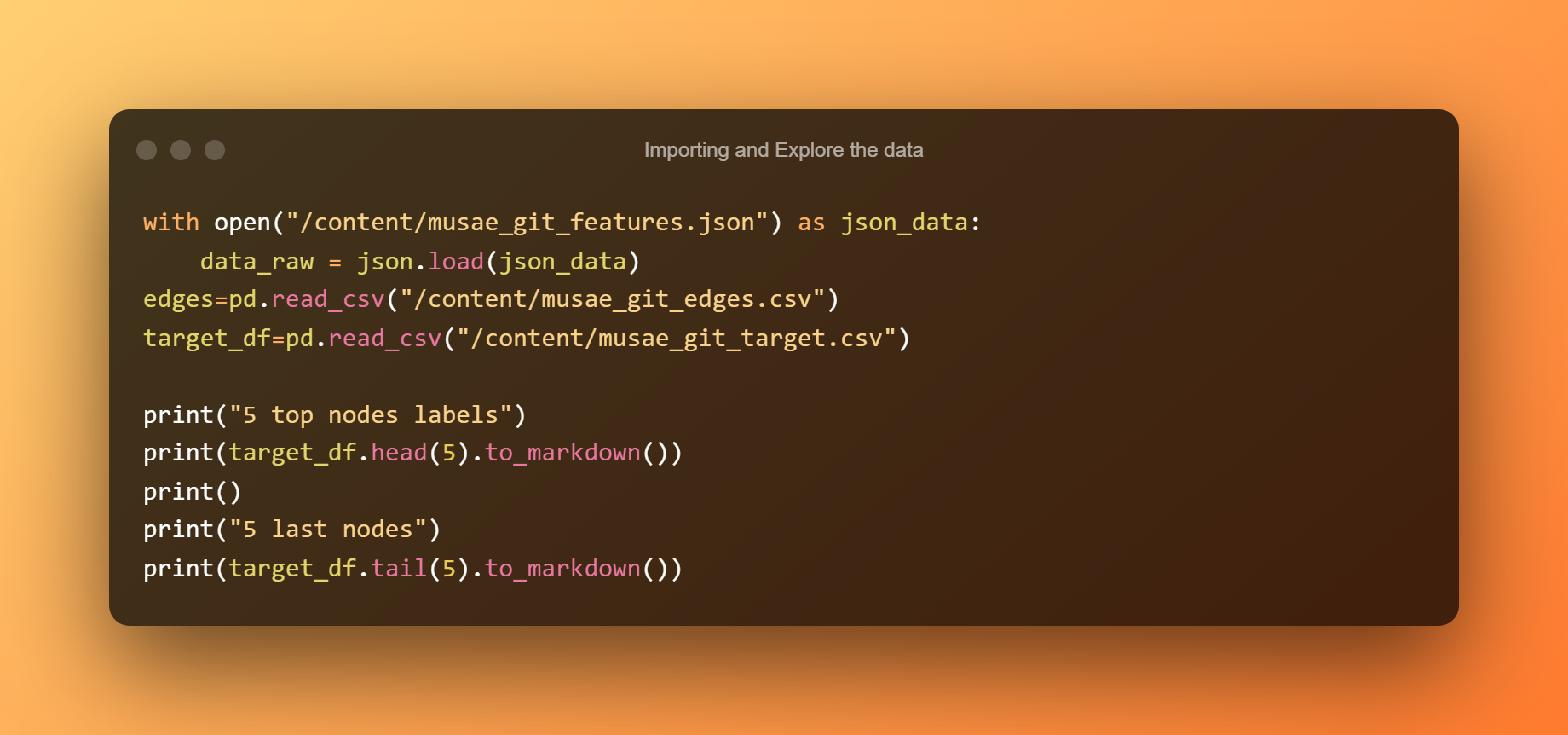
Import a prozkoumání dat
Dalším krokem je načtení dat a vykreslení prvních pěti řádků a posledních pět řádků ze souboru štítků.
V této situaci jsou pro nás relevantní pouze dva ze čtyř sloupců – id uzlu (tj. uživatel) a ml_target, což je 1, pokud je uživatel členem komunity strojového učení, a 0 jinak.
Vzhledem k tomu, že existují pouze dvě třídy, můžeme si být nyní jisti, že naším úkolem je otázka binární klasifikace.

V důsledku významné nerovnováhy ve třídách může klasifikátor pouze předpokládat, která třída je většinová, spíše než hodnotit nedostatečně zastoupenou třídu, takže vyváženost třídy je dalším zásadním faktorem, který je třeba zvážit.
Vynesení histogramu (rozdělení frekvence) odhaluje určitou nerovnováhu, protože existuje méně tříd ze strojového učení (label=1) než z ostatních tříd.


Kódování funkcí
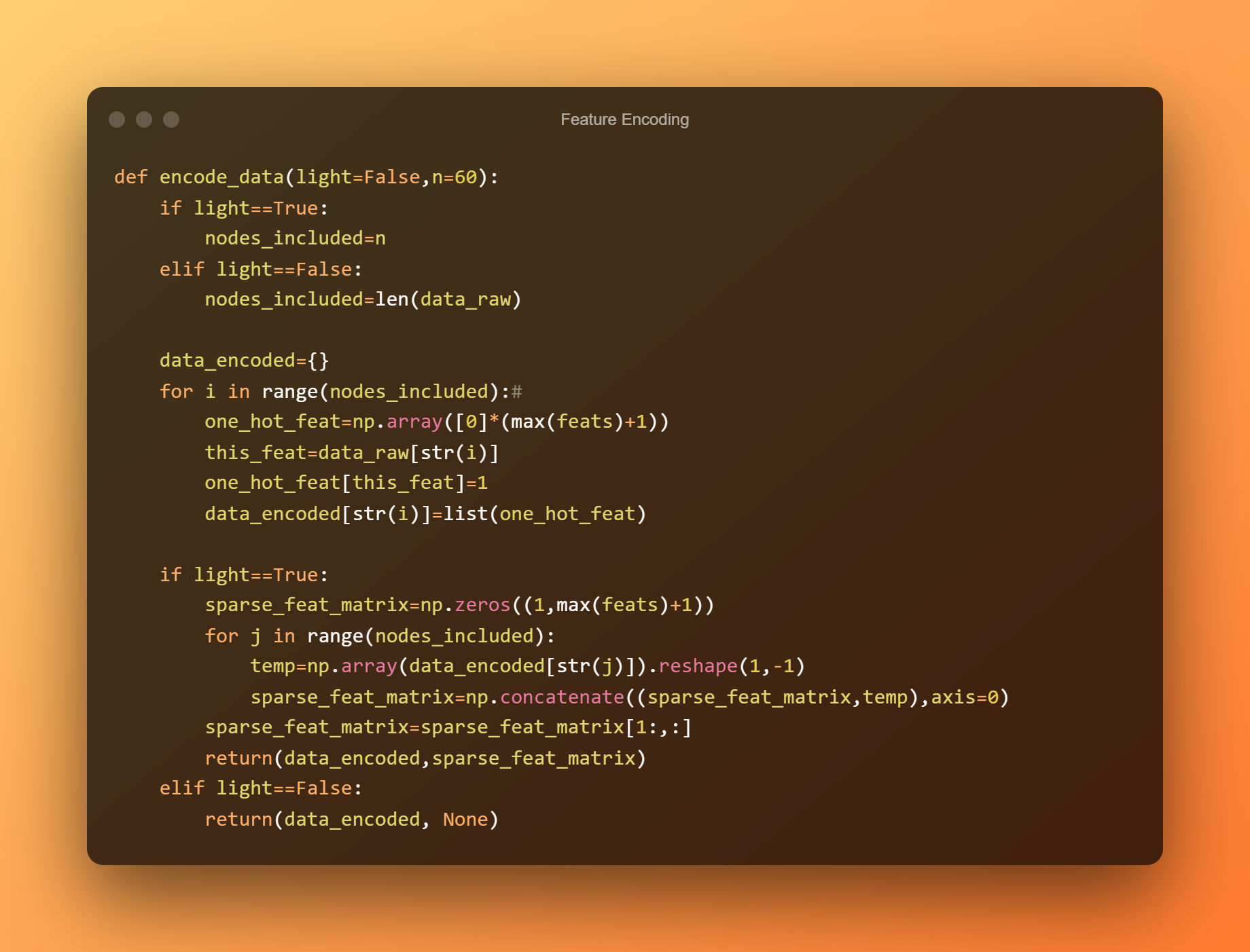
Charakteristiky uzlů nás informují o funkci, která je spojena s každým uzlem. Implementací naší metody kódování dat můžeme tyto charakteristiky okamžitě zakódovat.
Chceme použít tuto metodu k zapouzdření malé části sítě (řekněme 60 uzlů) pro zobrazení. Kód je uveden zde.
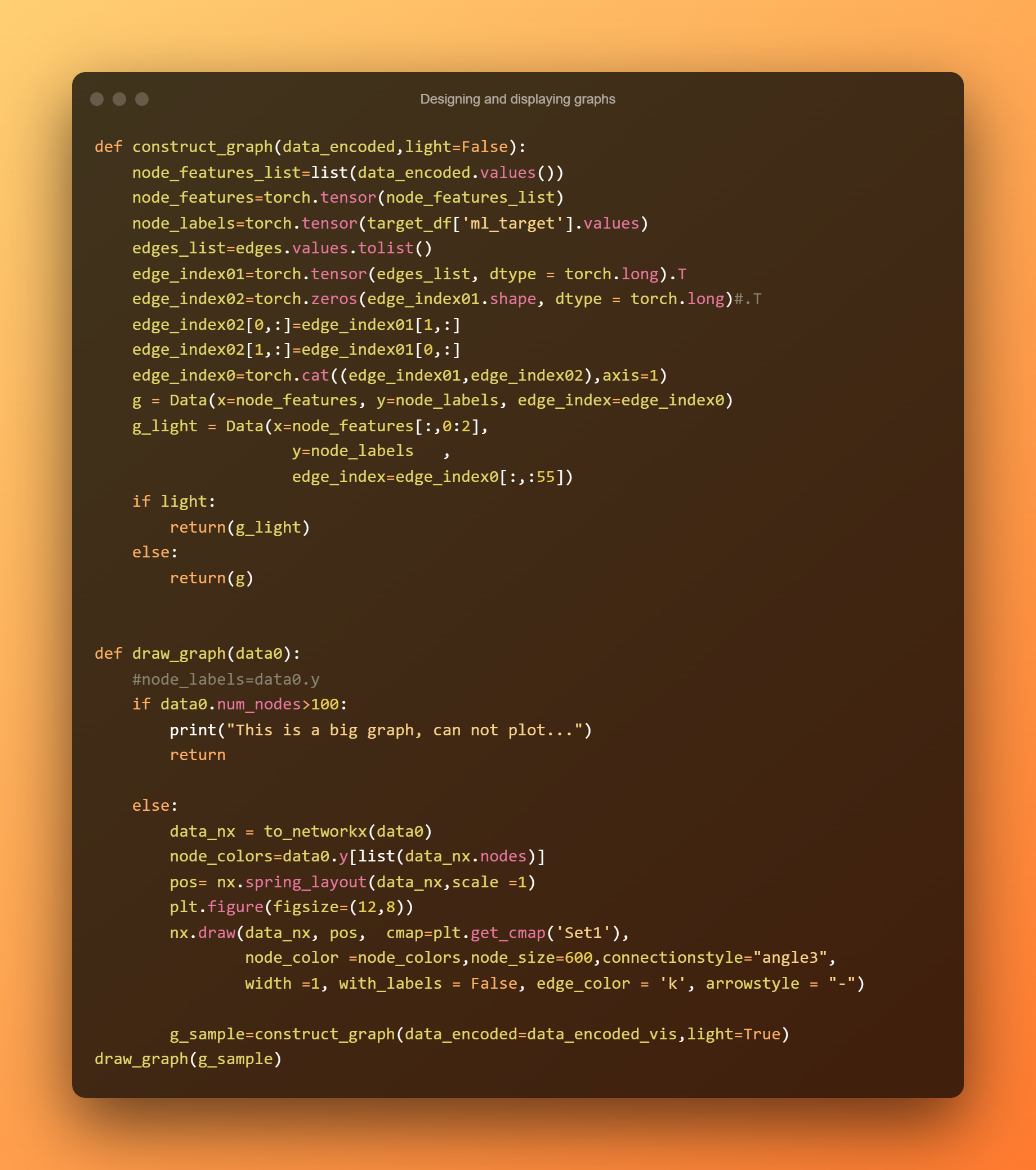
Navrhování a zobrazování grafů
Použijeme geometrii hořáku. data pro vytvoření našeho grafu.
K modelování jednoho grafu s různými (volitelnými) vlastnostmi se používají data, která jsou jednoduchým objektem Pythonu. Využitím této třídy a následujících atributů – z nichž všechny jsou tenzory pochodně – vytvoříme náš objekt grafu.
Tvar hodnoty x, která bude přidělena zakódovaným prvkům uzlu, je [počet uzlů, počet prvků].
Tvar y je [počet uzlů] a bude použit na popisky uzlů.
index hrany: Abychom popsali neorientovaný graf, potřebujeme rozšířit původní indexy hran, abychom umožnili existenci dvou odlišných orientovaných hran, které spojují stejné dva uzly, ale směřují opačnými směry.
Dvojice hran, jedna směřující z uzlu 100 do 200 a druhá z 200 na 100, je vyžadována například mezi uzly 100 a 200. Jsou-li poskytnuty indexy hran, pak takto lze znázornit neorientovaný graf. [2,2*počet původních hran] bude forma tenzoru.
Vytváříme naši metodu kreslení grafu pro zobrazení grafu. Prvním krokem je transformace naší homogenní sítě do NetworkX grafu, který lze následně vykreslit pomocí NetworkX.draw.
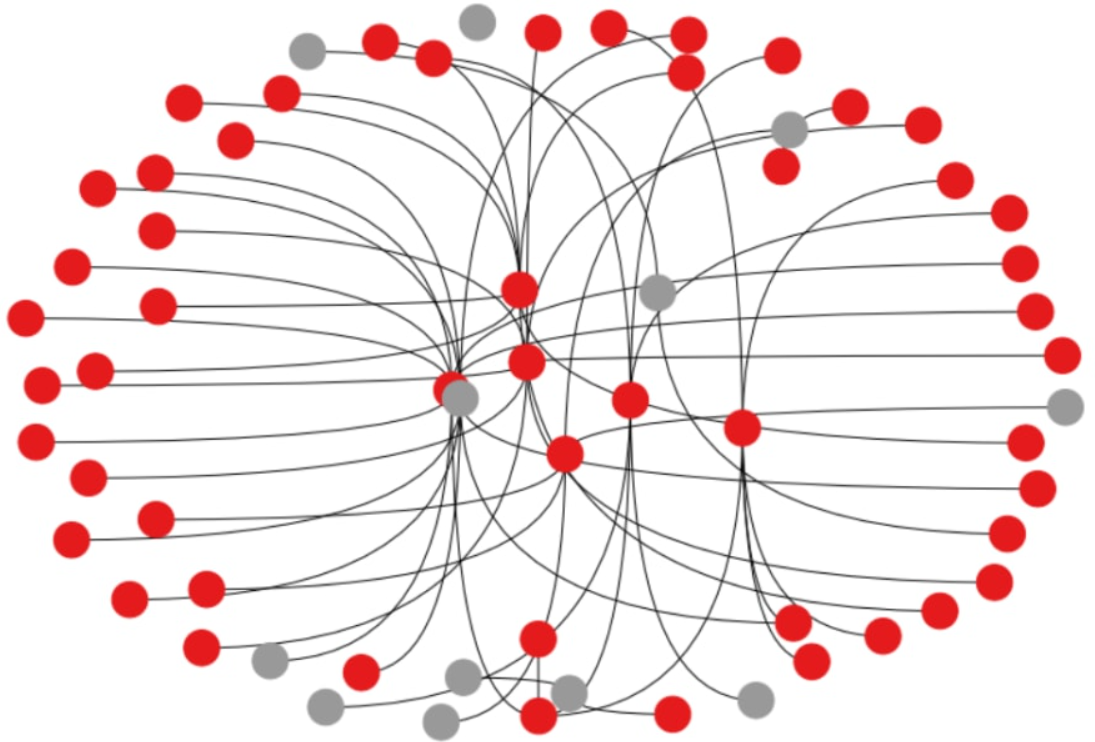
Vytvořte náš model GNN a trénujte jej
Začneme kódováním celé sady dat provedením kódování dat s light=False a následným voláním konstruktu grafu s light=False pro vytvoření celého grafu. Nebudeme se pokoušet nakreslit tento velký graf, protože předpokládám, že používáte místní počítač, který má omezené zdroje.

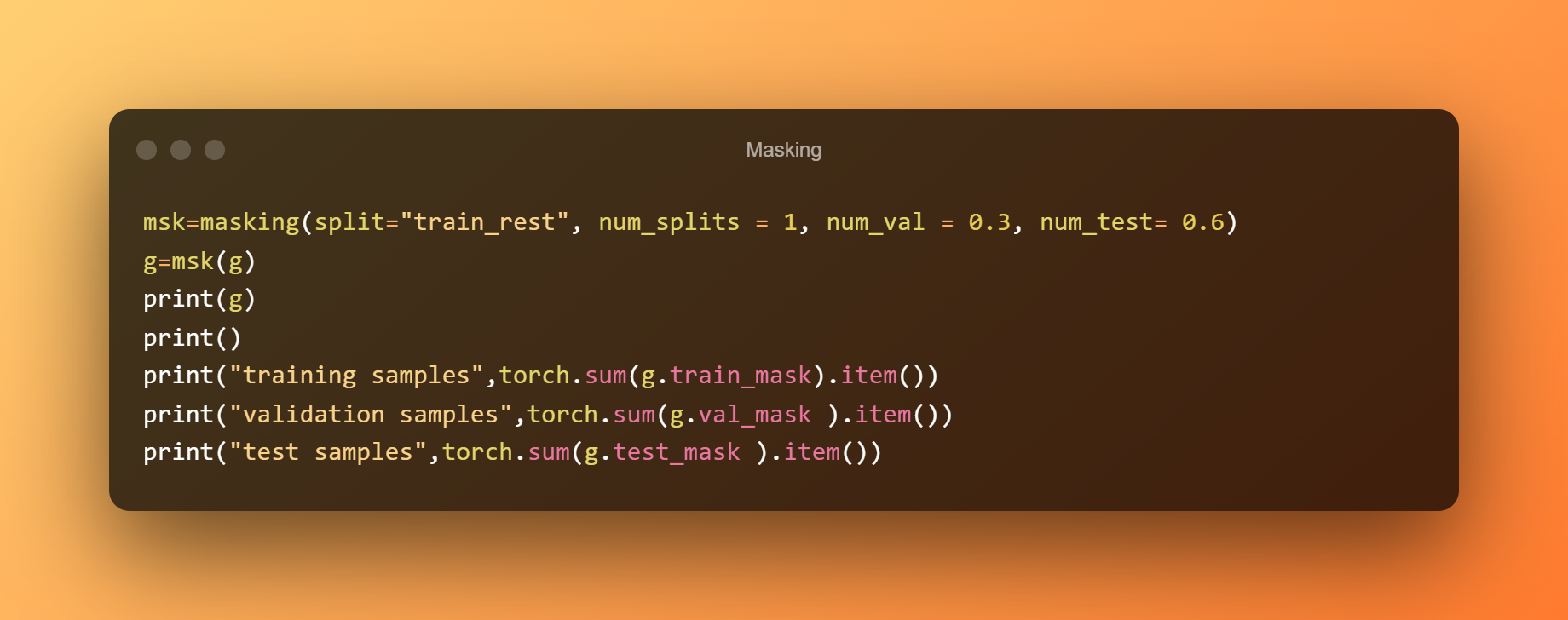
Masky, což jsou binární vektory, které identifikují, které uzly patří ke každé konkrétní masce pomocí číslic 0 a 1, lze použít k upozornění trénovací fáze, které uzly by měly být zahrnuty během trénování, a sdělit fázi inference, které uzly jsou testovací data. Pochodeň geometric.transformuje.
Rozdělení na úrovni uzlů lze přidat pomocí vlastností tréninkové masky, val masky a testovací masky třídy AddTrainValTestMask, které lze použít k vytvoření grafu a umožnit nám určit, jak chceme, aby byly naše masky konstruovány.
Pouze využíváme 10 % pro školení a 60 % dat používáme jako testovací sadu, zatímco 30 % používáme jako ověřovací sadu.
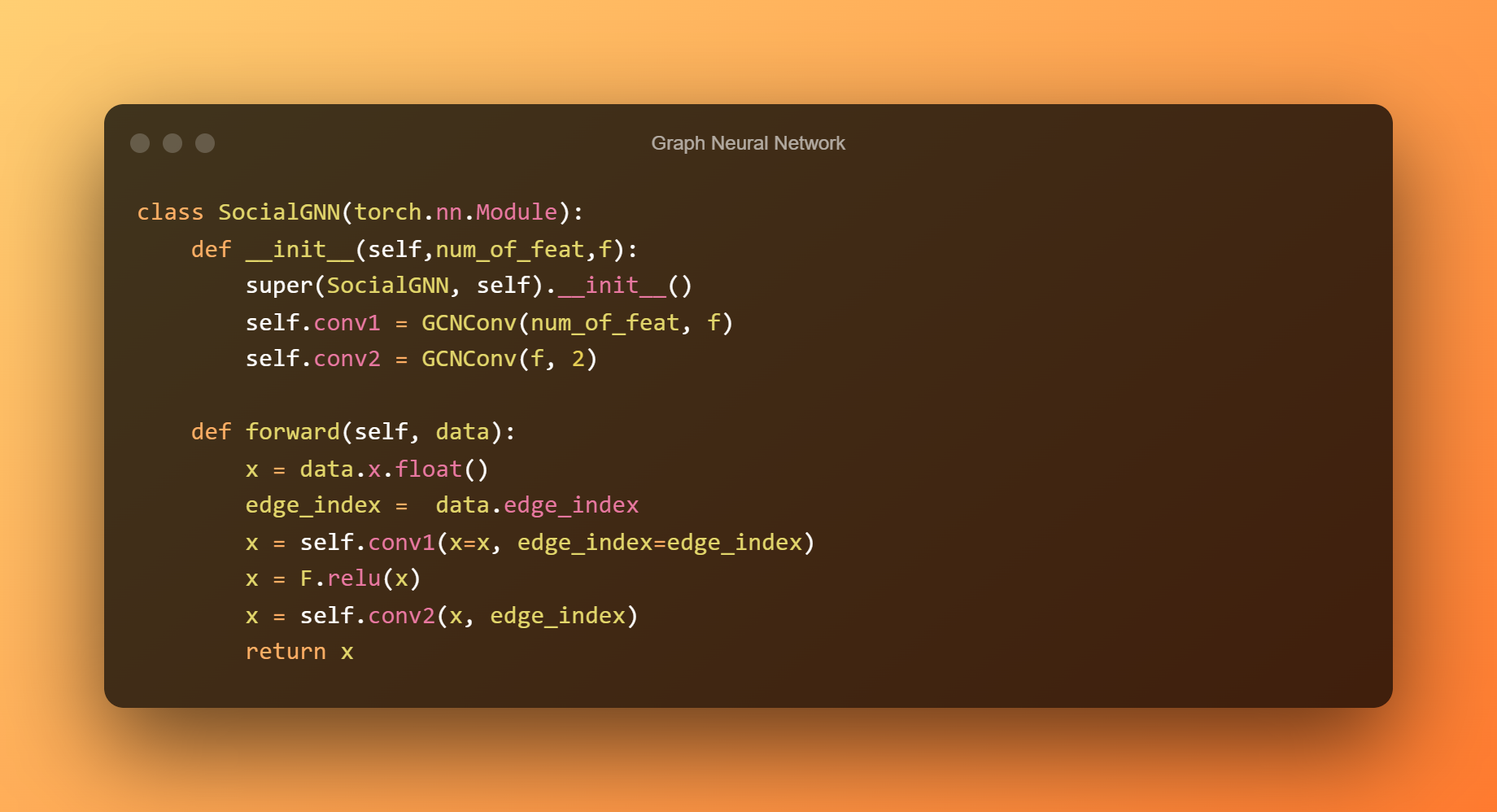
Nyní naskládáme dvě vrstvy GCNConv, z nichž první má počet výstupních prvků, který se rovná počtu prvků v našem grafu jako vstupních prvků.
Ve druhé vrstvě, která obsahuje výstupní uzly rovnající se počtu našich tříd, aplikujeme funkci aktivace relu a dodáváme latentní vlastnosti.
Index hrany a váha hrany jsou dvě z mnoha možností x, které může GCNConv přijmout ve funkci forward, ale v naší situaci potřebujeme pouze první dvě proměnné.
Navzdory skutečnosti, že náš model bude schopen předpovědět třídu každého uzlu v grafu, stále musíme určit přesnost a ztrátu pro každou sadu zvlášť v závislosti na fázi.
Například při tréninku chceme použít tréninkovou sadu pouze k určení přesnosti a tréninkové ztráty, a proto se nám naše masky hodí.
Pro výpočet vhodné ztráty a přesnosti definujeme funkce maskované ztráty a maskované přesnosti.
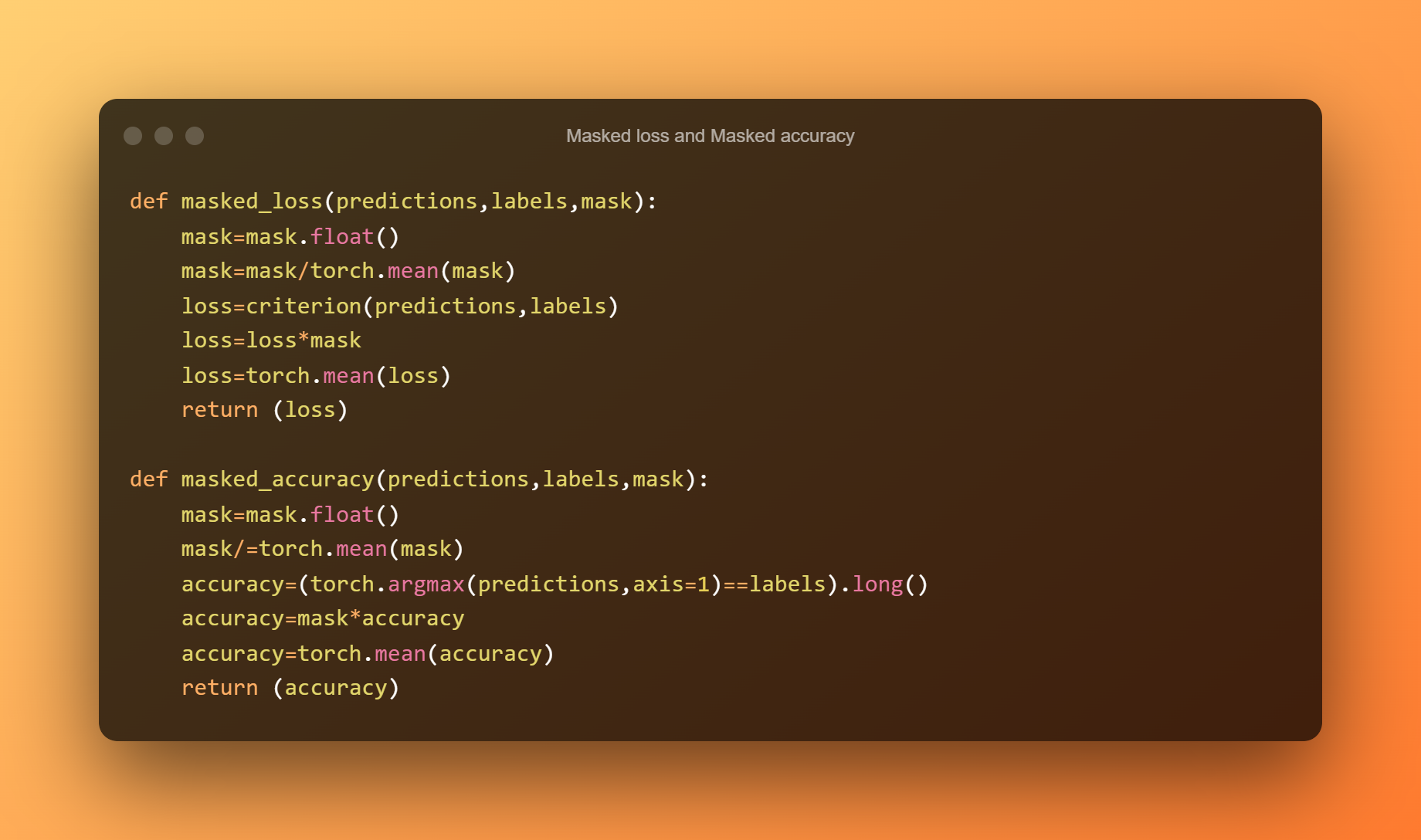
Trénink modelu
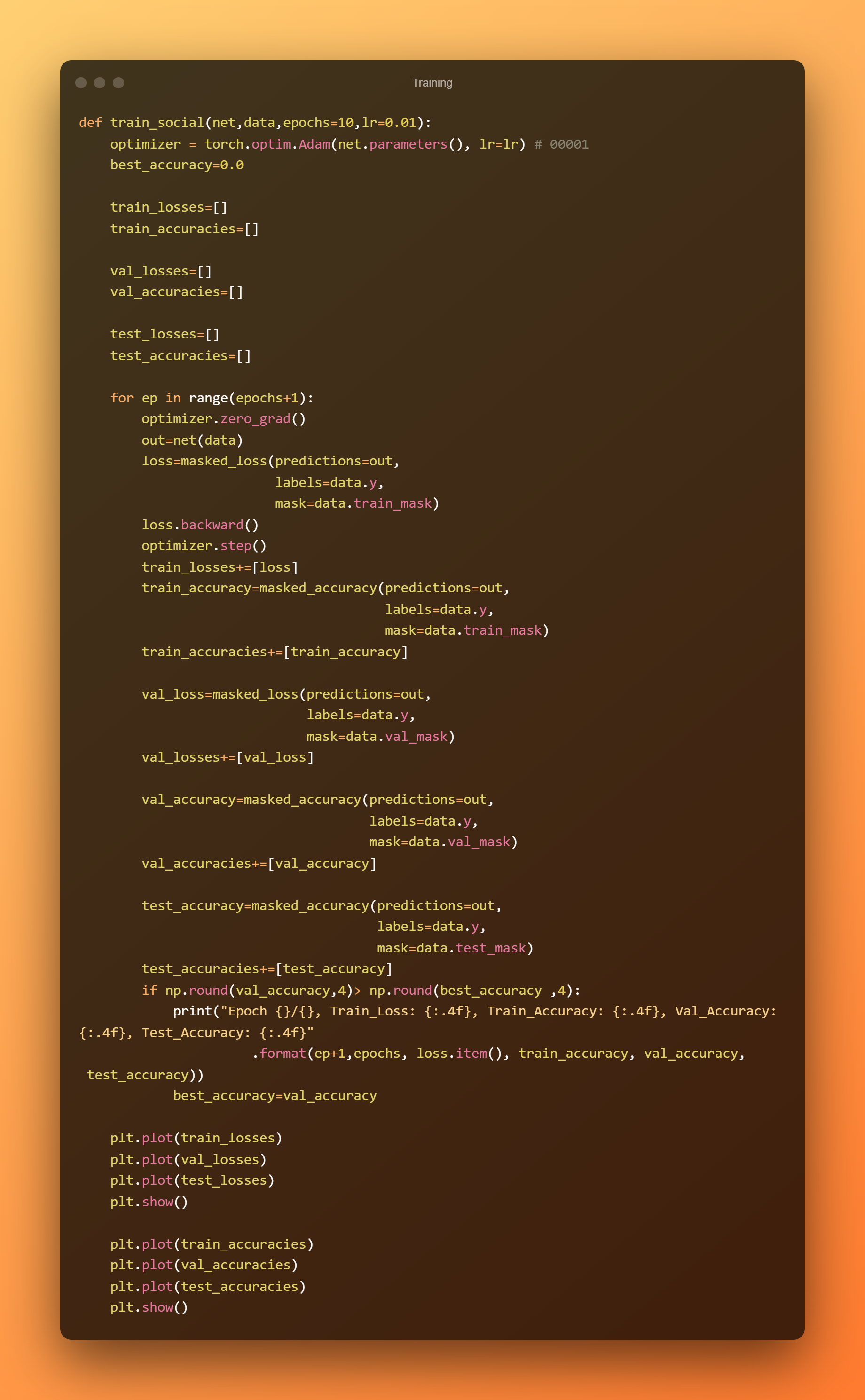
Nyní, když jsme definovali tréninkový účel, pro který bude svítilna používána. Adam je mistr optimalizace.
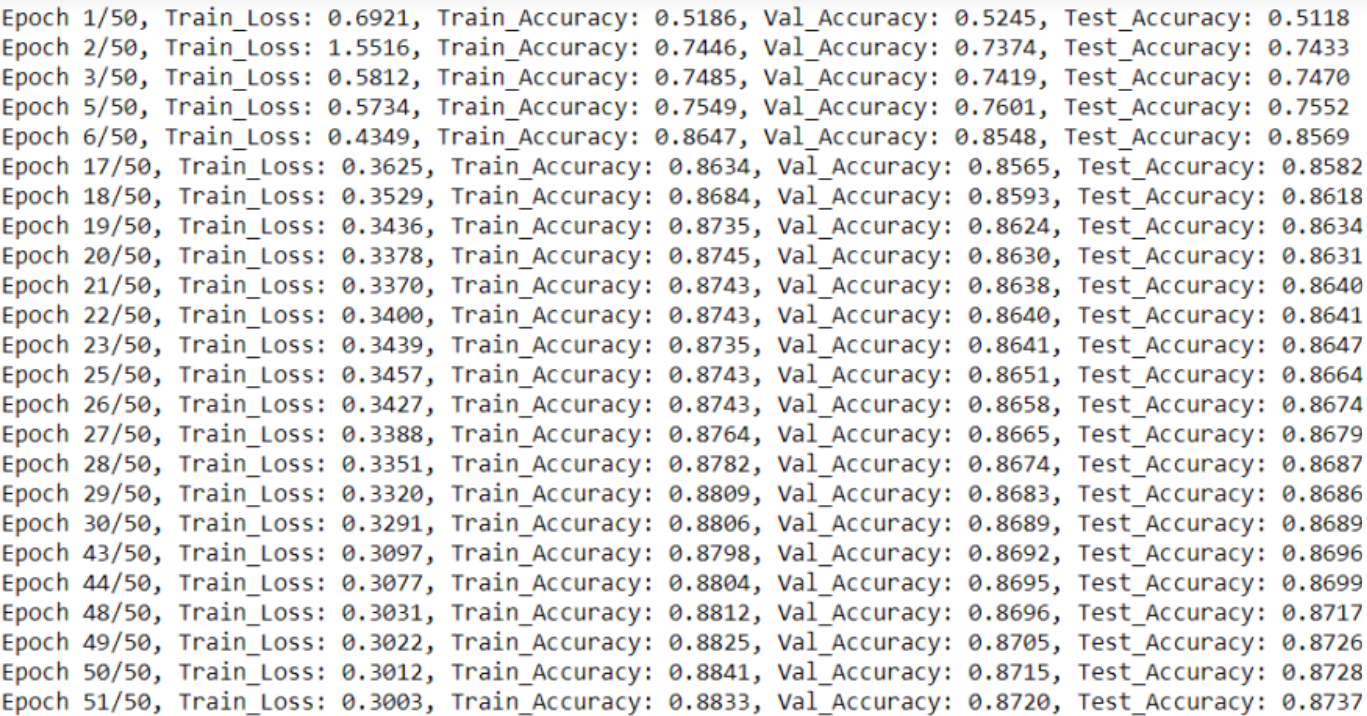
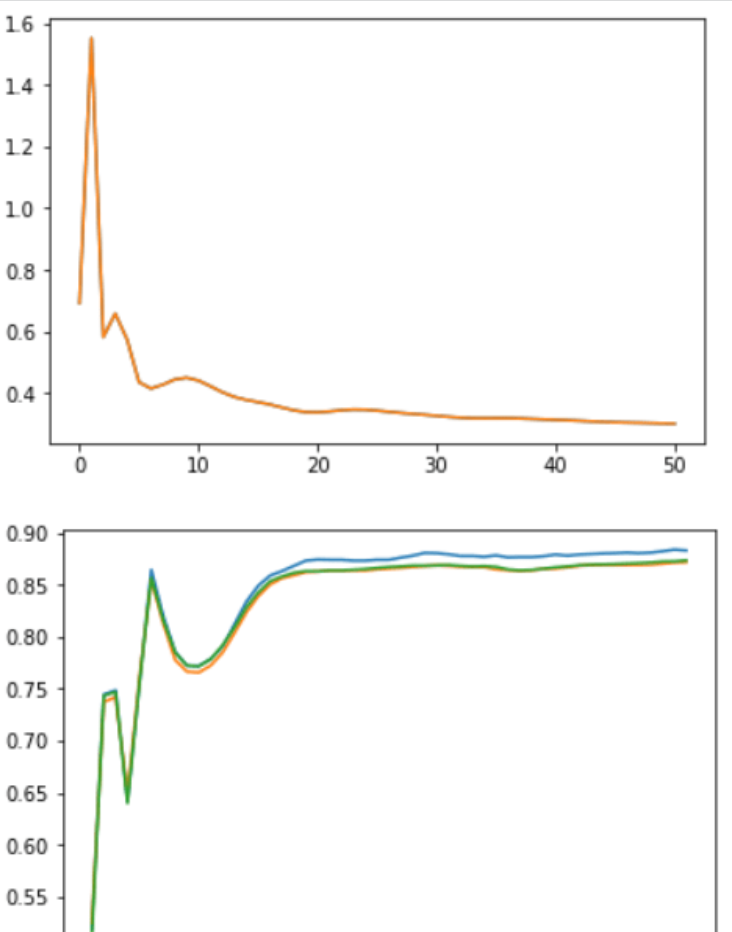
Školení provedeme pro určitý počet epoch, přičemž budeme dávat pozor na přesnost validace.
Zaznamenáváme také ztráty a přesnosti tréninku v různých epochách.
Nevýhody grafové neuronové sítě
Používání GNN má několik nevýhod. Kdy použít GNNa a jak zvýšit výkon našich modelů strojového učení, nám bude jasné, až jim lépe porozumíme.
- Zatímco GNN jsou mělké sítě, obvykle se třemi vrstvami, většina neuronových sítí může jít hluboko, aby zlepšila výkon. Kvůli tomuto omezení nejsme schopni pracovat na špičkové úrovni na velkých souborech dat.
- Je obtížnější trénovat model na grafech, protože jejich strukturální dynamika je dynamická.
- Vzhledem k vysokým výpočetním nákladům těchto sítí představuje škálování modelu pro výrobu problémy. Škálování GNN pro produkci bude náročné, pokud je vaše grafová struktura obrovská a komplikovaná.
Proč investovat do čističky vzduchu?
Během několika posledních let se GNN vyvinuly ve výkonné a efektivní nástroje pro problémy se strojovým učením v oblasti grafů. Základní přehled grafových neuronových sítí je uveden v tomto článku.
Poté můžete začít vytvářet datovou sadu, která bude použita k trénování a testování modelu. Chcete-li pochopit, jak funguje a čeho je schopen, můžete jít mnohem dále a trénovat jej pomocí jiného druhu datové sady.
Šťastné kódování!





Napsat komentář