Je uklidňující vědět, že se nám podařilo naplnit roboty našimi vrozenými schopnostmi učit se příkladem a vnímat své okolí. Zásadní výzvou je, aby výuka počítačů „viděla“ jako lidé potřebovala mnohem více času a úsilí.
Když však vezmeme v úvahu praktickou hodnotu, kterou tato dovednost v současné době poskytuje organizacím a podnikům, úsilí stojí za to. V tomto článku se dozvíte o klasifikaci obrázků, o tom, jak funguje, ao její praktické implementaci. Pojďme začít.
Co je klasifikace obrázků?
Úkol vložit obrázek do a nervová síť a jeho výstup nějaké formy štítku pro tento obrázek je známý jako rozpoznávání obrazu. Označení výstupu sítě bude odpovídat předem definované třídě.
K obrázku může být přiřazeno mnoho tříd nebo jednoduše jedna. Pokud existuje pouze jedna třída, často se používá termín „uznání“, zatímco pokud existuje více tříd, často se používá termín „klasifikace“.
Detekce objektů je podmnožina klasifikace obrázků, ve které jsou konkrétní případy objektů detekovány jako patřící do dané třídy, jako jsou zvířata, vozidla nebo lidé.
Jak funguje klasifikace obrázků?
Obraz ve formě pixelů je analyzován počítačem. Dosahuje toho tím, že s obrázkem zachází jako se sbírkou matic, jejichž velikost je určena rozlišením obrázku. Jednoduše řečeno, klasifikace obrázků je studium statistických dat pomocí algoritmů z pohledu počítače.
Klasifikace obrazu se provádí při digitálním zpracování obrazu seskupováním pixelů do předem určených skupin neboli „tříd“. Algoritmy rozdělují obraz do posloupnosti pozoruhodných charakteristik, což snižuje zátěž pro konečný klasifikátor.
Tyto vlastnosti informují klasifikátora o významu obrazu a potenciální klasifikaci. Protože ostatní procesy při klasifikaci obrázku jsou na něm závislé, je nejkritičtější fází metoda charakteristická extrakce.
Projekt poskytnutá data pro algoritmus je také rozhodující při klasifikaci obrazu, zejména klasifikace pod dohledem. Ve srovnání s hrozným souborem dat s nevyvážeností dat na základě třídy a nízkou kvalitou obrázků a poznámek funguje dobře optimalizovaná datová sada klasifikace obdivuhodně.
Klasifikace obrázků pomocí Tensorflow & Keras v pythonu
Budeme používat CIFAR-10 datový soubor (který zahrnuje letadla, letadla, ptáky a dalších 7 věcí).
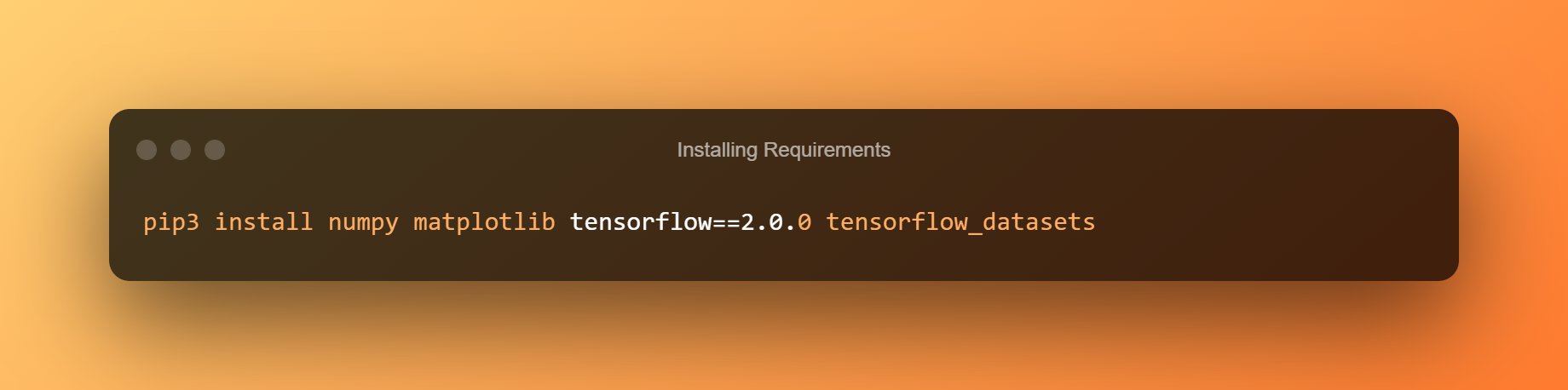
1. Požadavky na instalaci
Níže uvedený kód nainstaluje všechny předpoklady.
2. Import závislostí
Vytvořte soubor train.py v Pythonu. Níže uvedený kód importuje závislosti Tensorflow a Keras.

3. Inicializace parametrů
CIFAR-10 obsahuje pouze 10 kategorií obrázků, takže počet tříd jednoduše odkazuje na počet kategorií, které se mají klasifikovat.

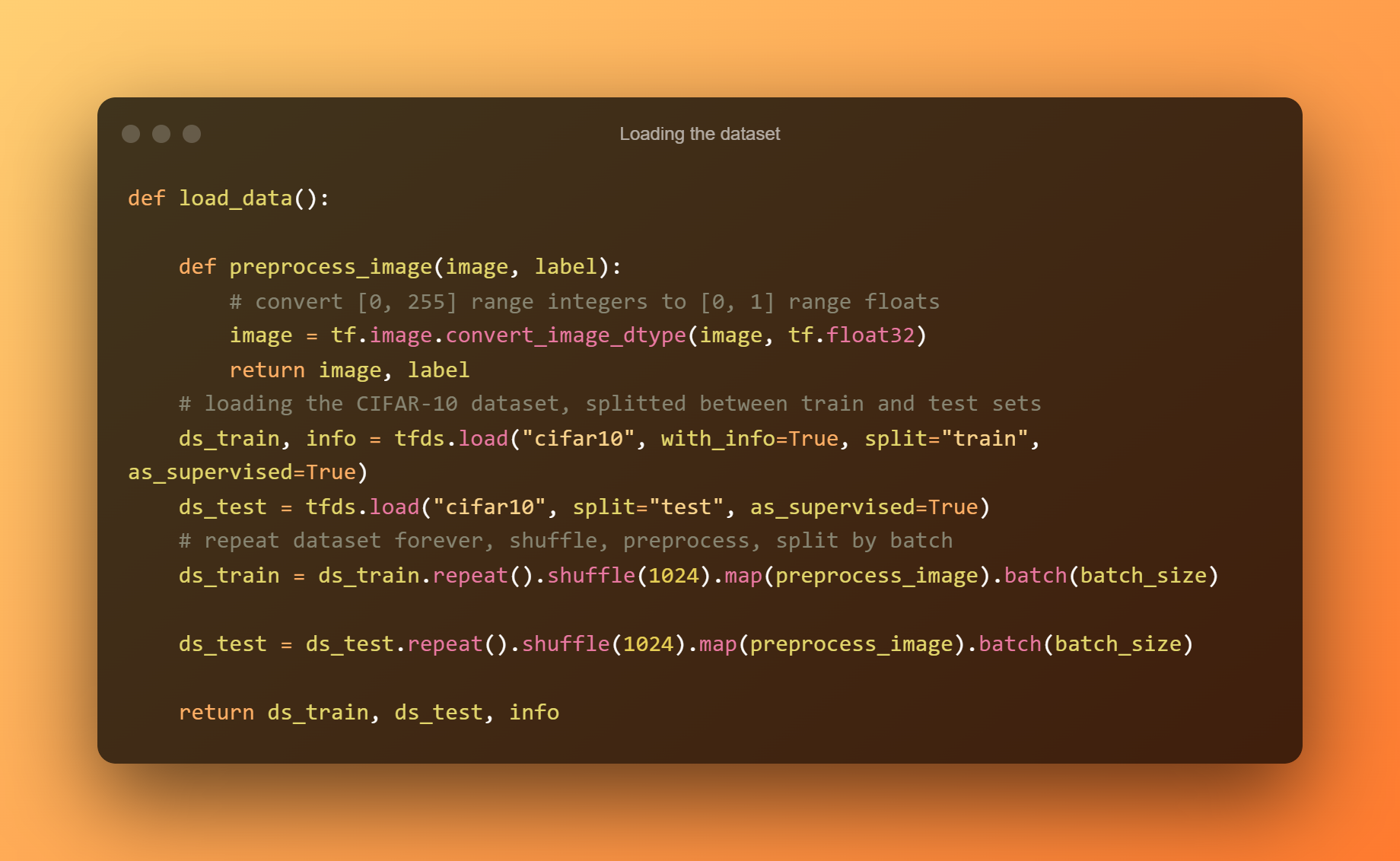
4. Načtení datové sady
Funkce využívá modul Tensorflow Datasets k načtení datové sady a my nastavíme s info na True, abychom o ní získali nějaké informace. Můžete si jej vytisknout, abyste viděli, jaká pole a jejich hodnoty jsou, a informace použijeme k načtení počtu vzorků v sadách školení a testování.
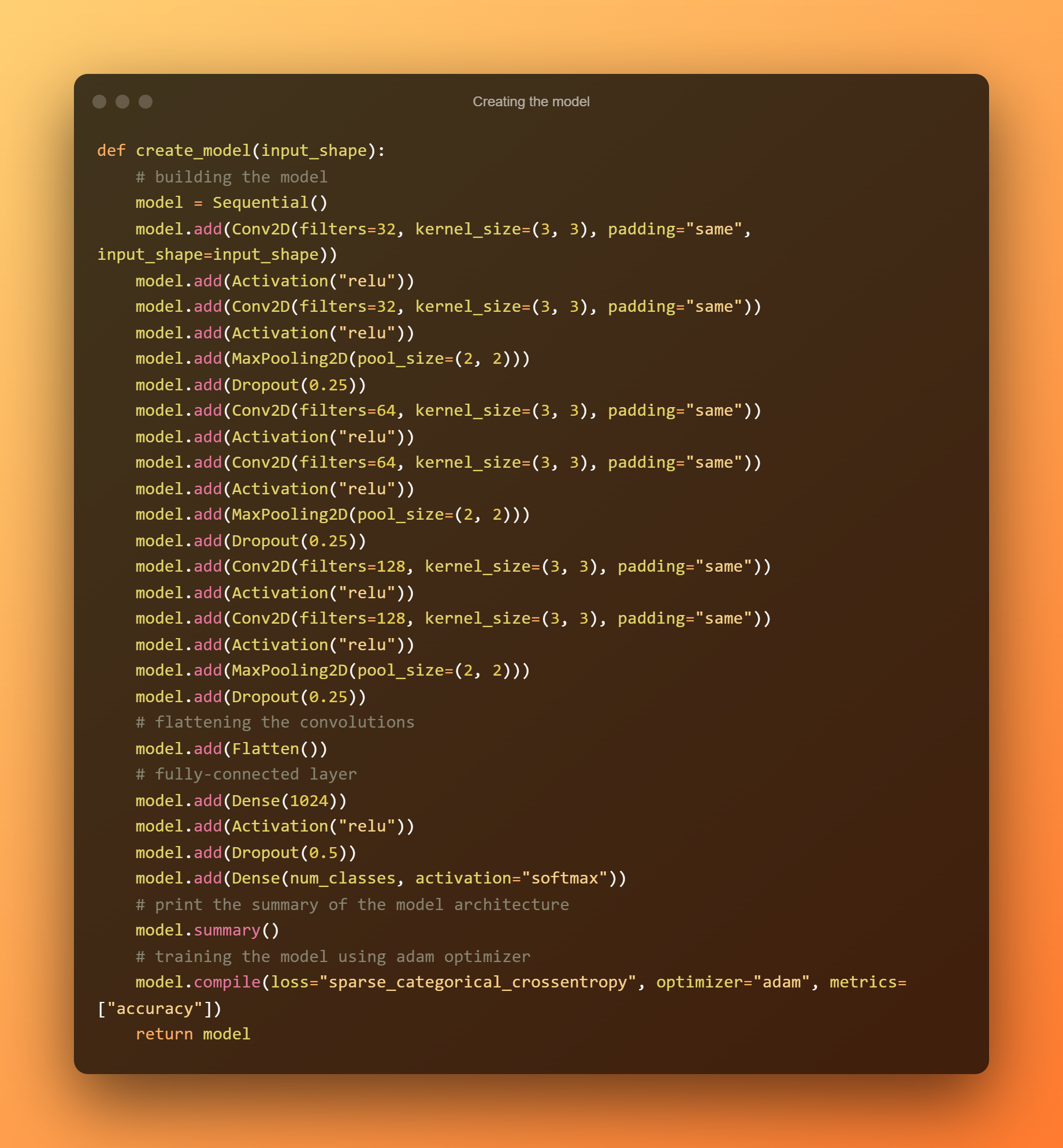
5. Vytvoření modelu
Nyní vytvoříme tři vrstvy, z nichž každá se skládá ze dvou sítí ConvNet s funkcí maximálního sdružování a aktivace ReLU, po nichž bude následovat plně propojený systém 1024 jednotek. Ve srovnání s ResNet50 nebo Xception, které jsou nejmodernějšími modely, to může být poměrně malý model.
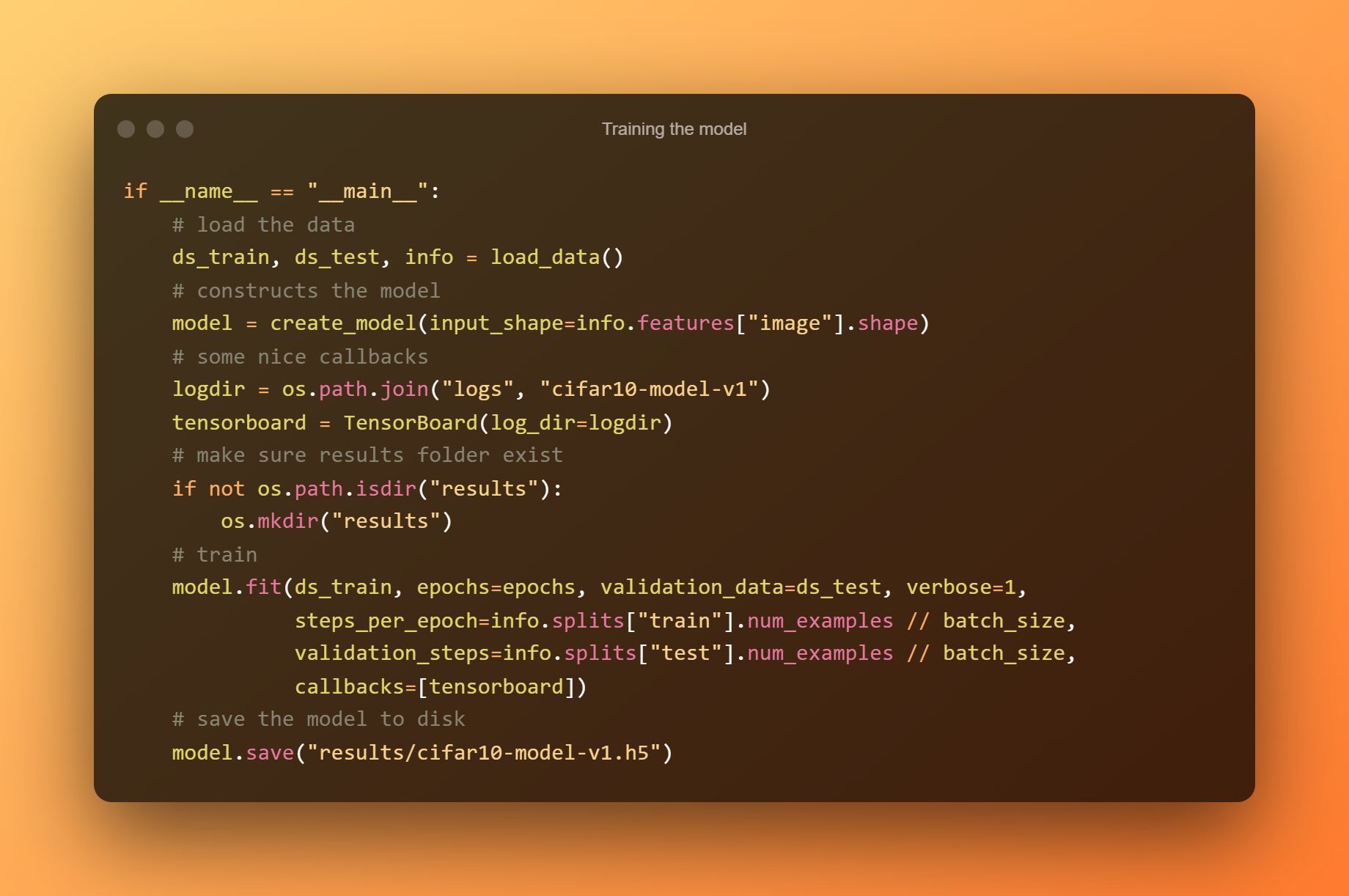
6. Trénink modelu
Použil jsem Tensorboard k měření přesnosti a ztrát v každé epoše a po importu dat a vygenerování modelu nám poskytl krásný displej. Spusťte následující kód; v závislosti na vašem CPU/GPU bude školení trvat několik minut.
Chcete-li použít tensorboard, stačí zadat následující příkaz do terminálu nebo příkazového řádku v aktuálním adresáři:
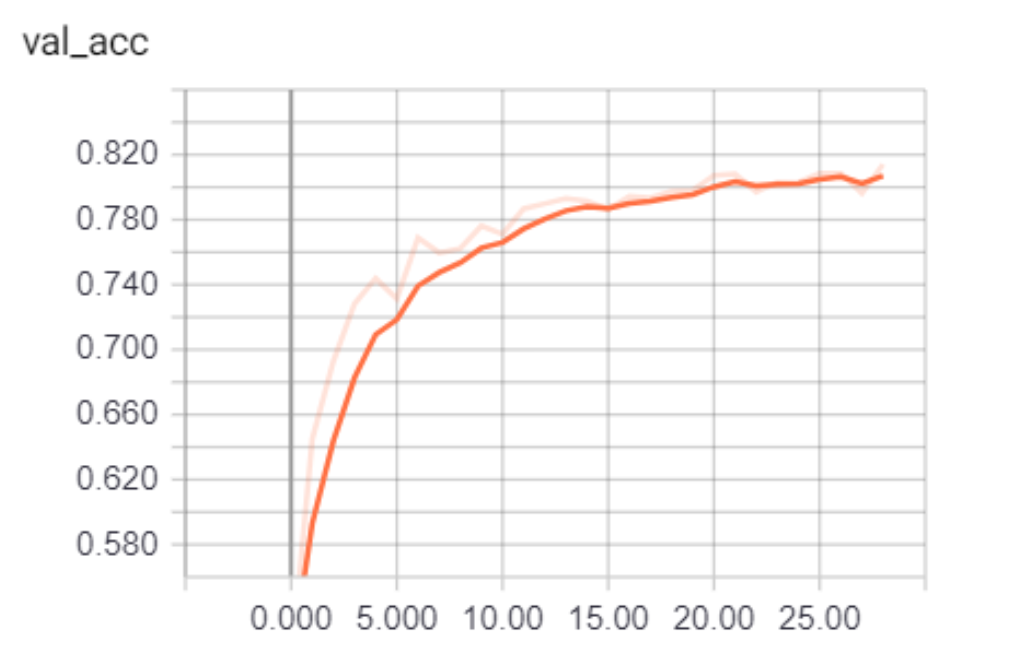
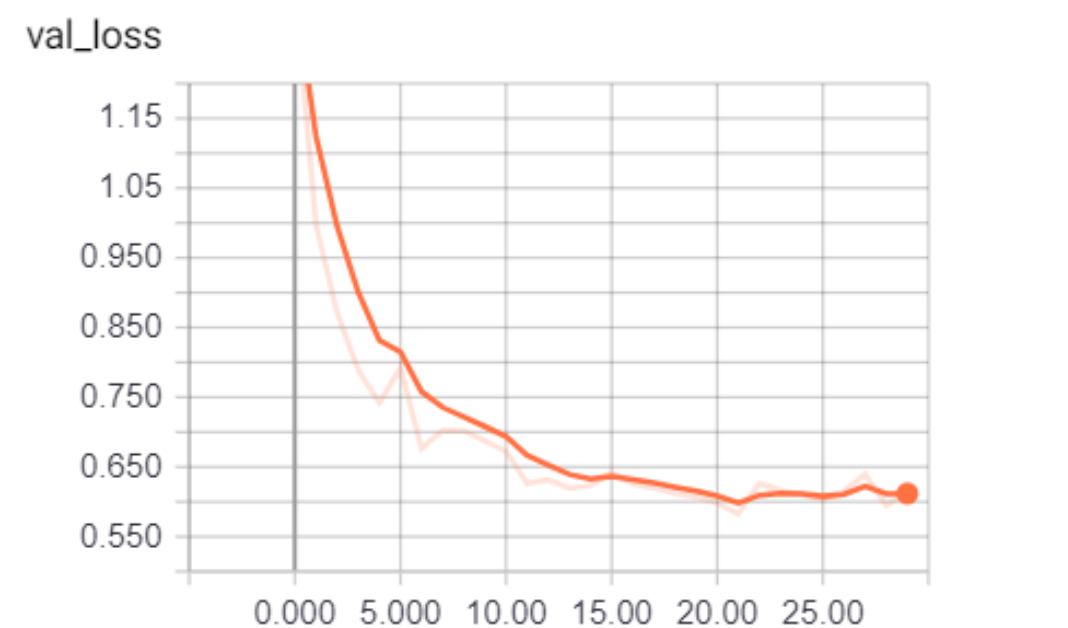
Uvidíte, že ztráta ověření se snižuje a přesnost stoupá na přibližně 81 %. To je fantastické!
Testování modelu
Po dokončení tréninku se konečný model a váhy uloží do složky výsledků, což nám umožňuje trénovat jednou a provádět předpovědi, kdykoli se nám to líbí. Postupujte podle kódu v novém souboru pythonu s názvem test.py.
7. Import utilit pro testování

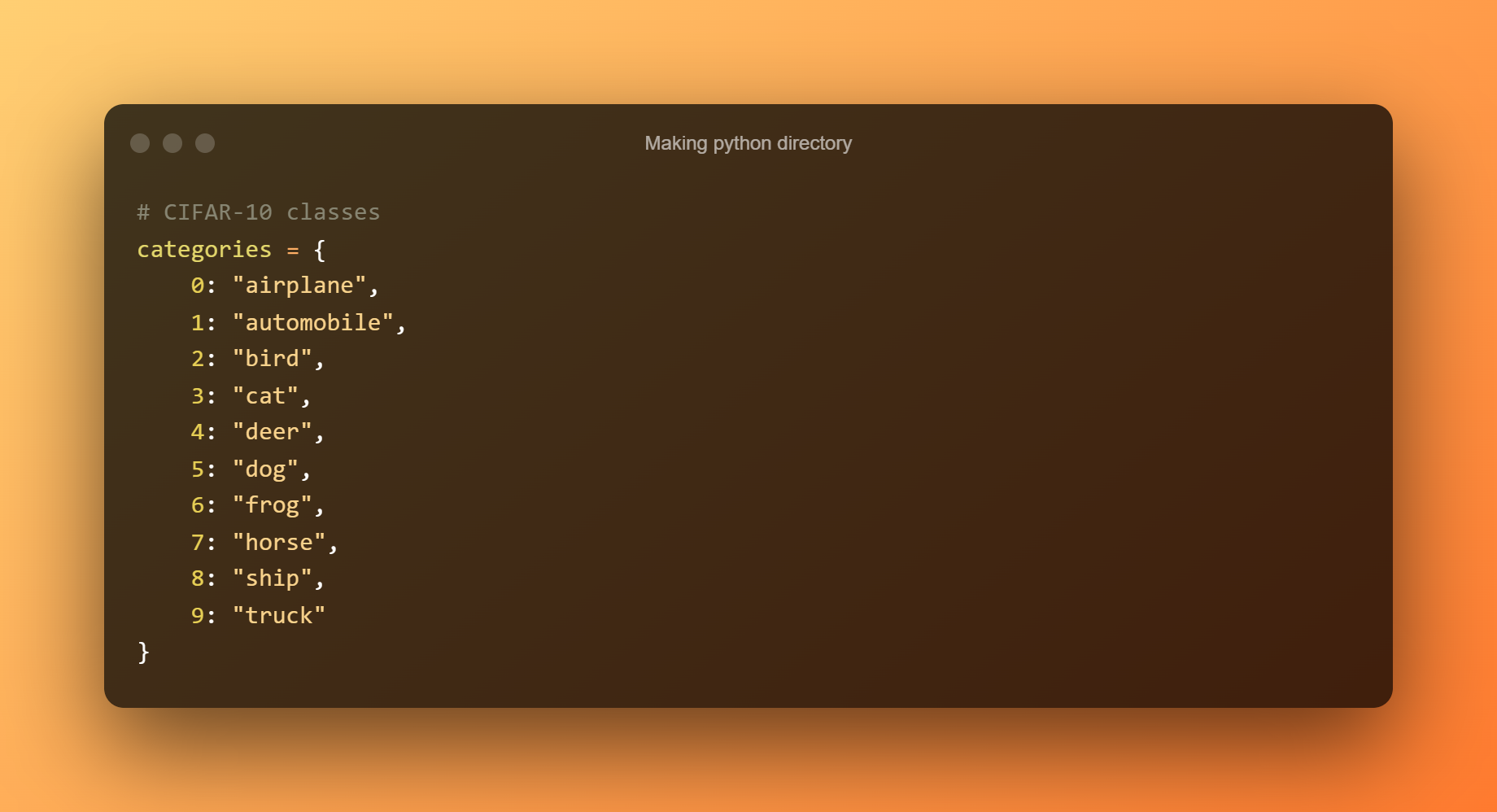
8. Vytvoření adresáře python
Vytvořte pythonovský slovník, který převede každou celočíselnou hodnotu do příslušného štítku datové sady:
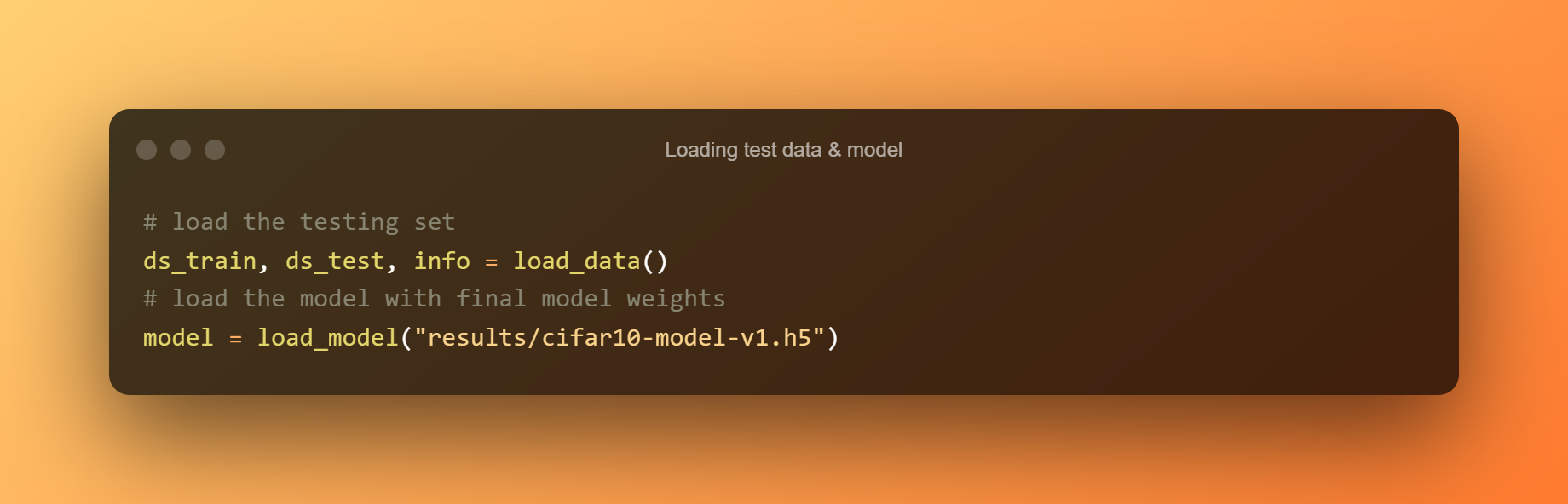
9. Načítání testovacích dat a modelu
Následující kód načte testovací data a model.
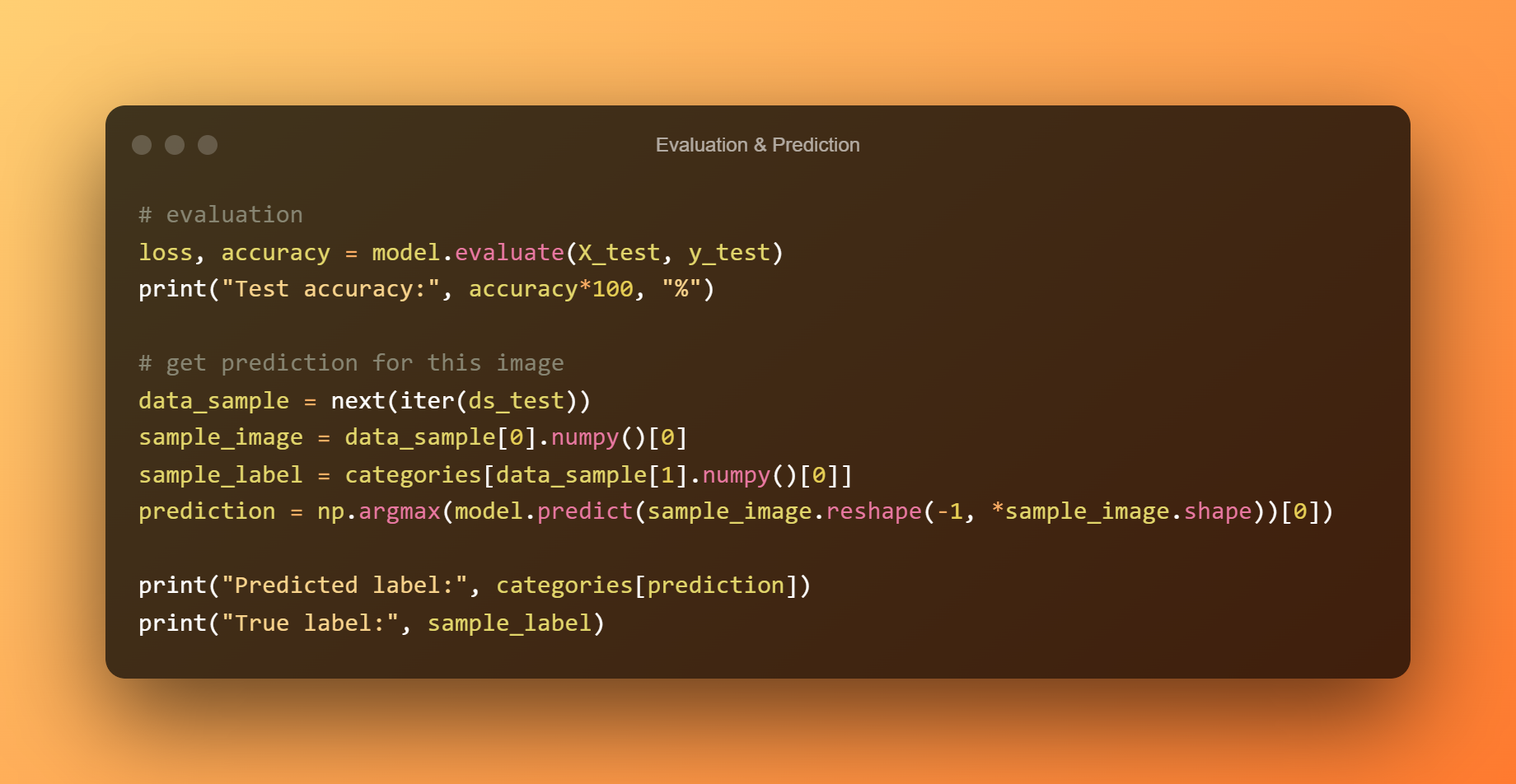
10. Hodnocení a predikce
Následující kód vyhodnotí a provede předpovědi na obrázcích žáby.
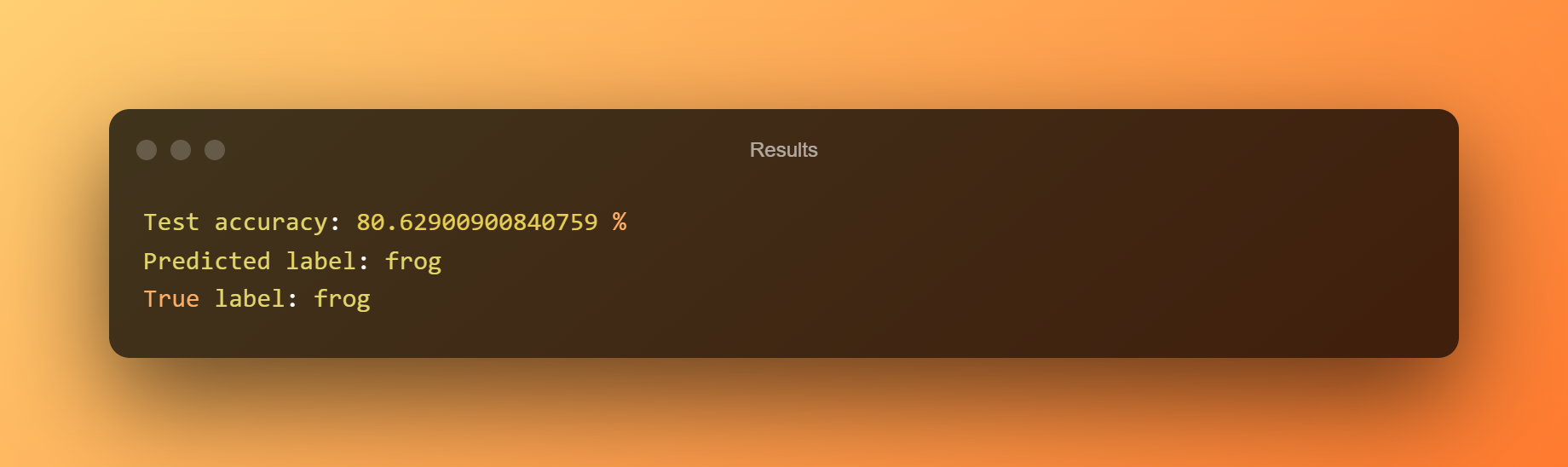
11. Výsledek
Model předpověděl žábu s přesností 80.62 %.
Proč investovat do čističky vzduchu?
Dobře, s touto lekcí jsme skončili. Zatímco 80.62 % není pro malou CNN dobré, důrazně vám doporučuji změnit model nebo se podívat na ResNet50, Xception nebo jiné špičkové modely pro lepší výsledky.
Nyní, když jste vytvořili svou první síť pro rozpoznávání obrázků v Kerasu, měli byste experimentovat s modelem, abyste zjistili, jak různé parametry ovlivňují jeho výkon.





Napsat komentář