Obsah[Skrýt][Ukázat]
Společnosti zachycují více dat než kdy jindy, protože se na ně stále více spoléhají při důležitých obchodních rozhodnutích, zlepšují nabídku produktů a poskytují lepší služby zákazníkům.
S množstvím dat vytvářených exponenciální rychlostí nabízí cloud několik výhod pro zpracování a analýzu dat, včetně škálovatelnosti, spolehlivosti a dostupnosti.
V cloudovém ekosystému existuje také několik nástrojů a technologií pro zpracování a analýzu dat. Dva typy struktur úložiště velkých dat, které se nejčastěji využívají, jsou datové sklady a datová jezera.
Ačkoli je využití datového jezera méně atraktivní, protože nemůžete dotazovat model a data, dokud jsou stále relevantní, použití datového skladu pro streamování datového úložiště je plýtvání.

Wjaký typ cloudové architektury zvolíme?
Měli bychom uvažovat o novějších konceptech pro datový jezerní dům, nebo bychom se měli spokojit s omezeními skladu nebo omezeními jezera?
Nová architektura datového úložiště zvaná „data lakehouse“ kombinuje přizpůsobivost datových jezer se správou dat datových skladů.
Pochopení různých metod ukládání velkých dat je zásadní pro vybudování spolehlivého kanálu pro ukládání dat pro business intelligence (BI), analýzu dat a strojové učení (ML) pracovní zátěže v závislosti na požadavcích vaší společnosti.
V tomto příspěvku se podrobně podíváme na Data Warehouse, Data Lake a Data Lakehouse s jejich výhodami, omezeními a také jejich klady a zápory. Pojďme začít.
Co je to Data Warehouse?
Datový sklad je centralizované datové úložiště, které organizace používá k uchování obrovských objemů dat z mnoha zdrojů. Datový sklad funguje jako jediný zdroj „datové pravdy“ organizace a je nezbytný pro vytváření sestav a obchodní analýzy.
Datové sklady obvykle kombinují relační datové sady z několika zdrojů, jako jsou aplikační, obchodní a transakční data, k ukládání historických dat. Před načtením do skladového systému jsou data v datových skladech transformována a vyčištěna tak, aby mohla být použita jako jediný zdroj pravdivosti dat.
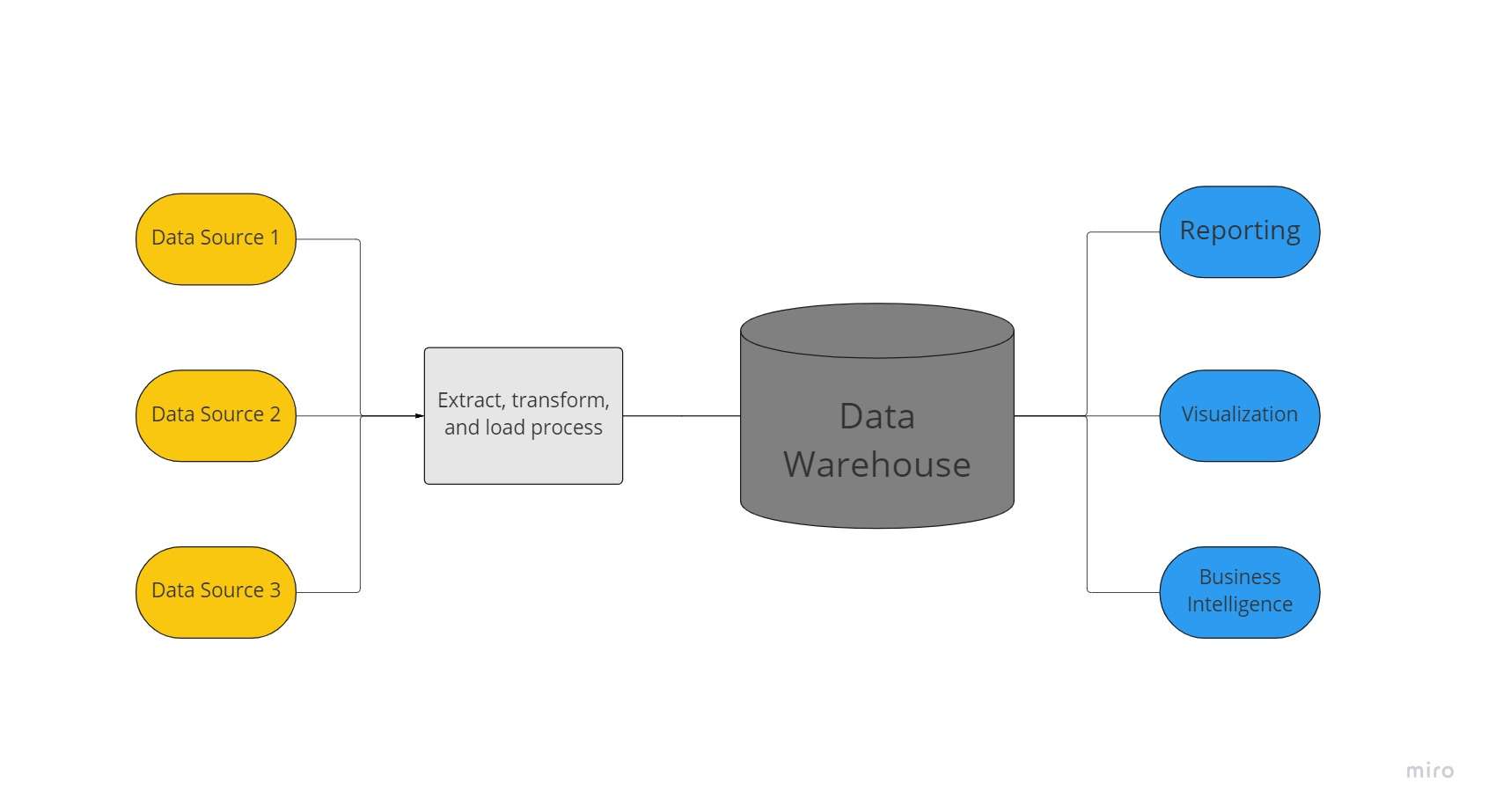
Podniky investují do datových skladů díky své schopnosti rychle nabízet obchodní pohledy ze všech oblastí společnosti. S využitím nástrojů BI, klientů SQL a dalších méně sofistikovaných analytických řešení (tj. jiných než datových věd), obchodní analytici, datoví inženýři a osoby s rozhodovací pravomocí mají přístup k datům z datových skladů.
Udržovat sklad se stále narůstajícím objemem dat je nákladné a datový sklad nemůže zpracovávat nezpracovaná nebo nestrukturovaná data. Navíc to není ideální volba pro sofistikované techniky analýzy dat, jako je strojové učení nebo prediktivní modelování.
Datový sklad proto poskytuje rychlejší odpovědi na dotazy a data vyšší kvality. Google Big Query, Amazon Redshift, Azure SQL Data Storage a Snowflake jsou cloudové služby, které jsou k dispozici pro datové sklady.
Výhody datového skladu
- Zvýšení efektivity a rychlosti pracovního zatížení business intelligence a analýzy dat: Datové sklady zkracují dobu potřebnou pro přípravu a analýzu dat. Mohou se snadno propojit s nástroji pro analýzu dat a business intelligence, protože data z datového skladu jsou spolehlivá a konzistentní. Datové sklady navíc šetří čas potřebný ke sběru dat a poskytují týmům možnost používat data pro sestavy, řídicí panely a další analytické požadavky.
- Zvýšení konzistence, kvality a standardizace dat: Organizace shromažďují data z různých zdrojů, včetně uživatelských, prodejních a transakčních dat. Firma může důvěřovat datům pro obchodní požadavky, protože datové sklady kompilují firemní data do jednotného standardizovaného formátu, který může fungovat jako jediný zdroj pravdivosti dat.
- Posílení rozhodování obecně: Datové sklady umožňují lepší rozhodování tím, že nabízí centralizované úložiště pro aktuální i stará data. Zpracováním dat v datových skladech za účelem přesného přehledu mohou osoby s rozhodovací pravomocí posoudit rizika, porozumět přáním klientů a zlepšit zboží a služby.
- Poskytování lepších obchodních informací: Datové sklady překlenují propast mezi masivními nezpracovanými daty, která jsou často shromažďována rutinně jako samozřejmost, a upravenými daty, která poskytují přehled. Fungují jako základ pro ukládání dat organizace, umožňují jí odpovídat na složité otázky o jejích datech a využívat odpovědi k přijímání obhajitelných obchodních rozhodnutí.
Omezení Data Warehouse
- Nedostatek datové flexibility: Zatímco datové sklady vynikají ve zpracování strukturovaných dat, polostrukturované a nestrukturované datové formáty, jako je analýza protokolů, streamování a data ze sociálních médií, pro ně mohou být náročné. To umožňuje doporučovat datové sklady pro případy použití zahrnující strojové učení a umělá inteligence obtížný.
- Nákladná instalace a údržba: Instalace a údržba datových skladů může být nákladná. Datový sklad navíc často není statický; stárne a vyžaduje častou údržbu, která je drahá.
Klady
- Data lze snadno najít, získat a dotazovat se.
- Dokud jsou data již čistá, příprava dat SQL je jednoduchá.
Nevýhody
- Jste nuceni používat pouze jednoho dodavatele analytických služeb.
- Analýza a ukládání nestrukturovaných nebo plynulých dat je poměrně nákladné.
Co je Data Lake?
Každý typ dat je slíben a umožněn datovými jezery. Je výhodné mít data přístupným způsobem centrálně umístěná a dostupná pro čtení.
Datové jezero je centralizovaný, extrémně adaptabilní úložný prostor, kde jsou uchovávány obrovské objemy organizovaných a nestrukturovaných dat v jejich nezpracované, nezměněné a neformátované podobě.
Datové jezero využívá k ukládání dat plochou architekturu a objekty uložené v nezpracovaném stavu, na rozdíl od datových skladů, které ukládají relační data, která byla dříve „vyčištěna“.
Datová jezera, na rozdíl od datových skladů, které mají potíže se zpracováním dat v tomto formátu, jsou adaptabilní, spolehlivá a cenově dostupná a umožňují podnikům získat lepší přehled z nestrukturovaných dat.
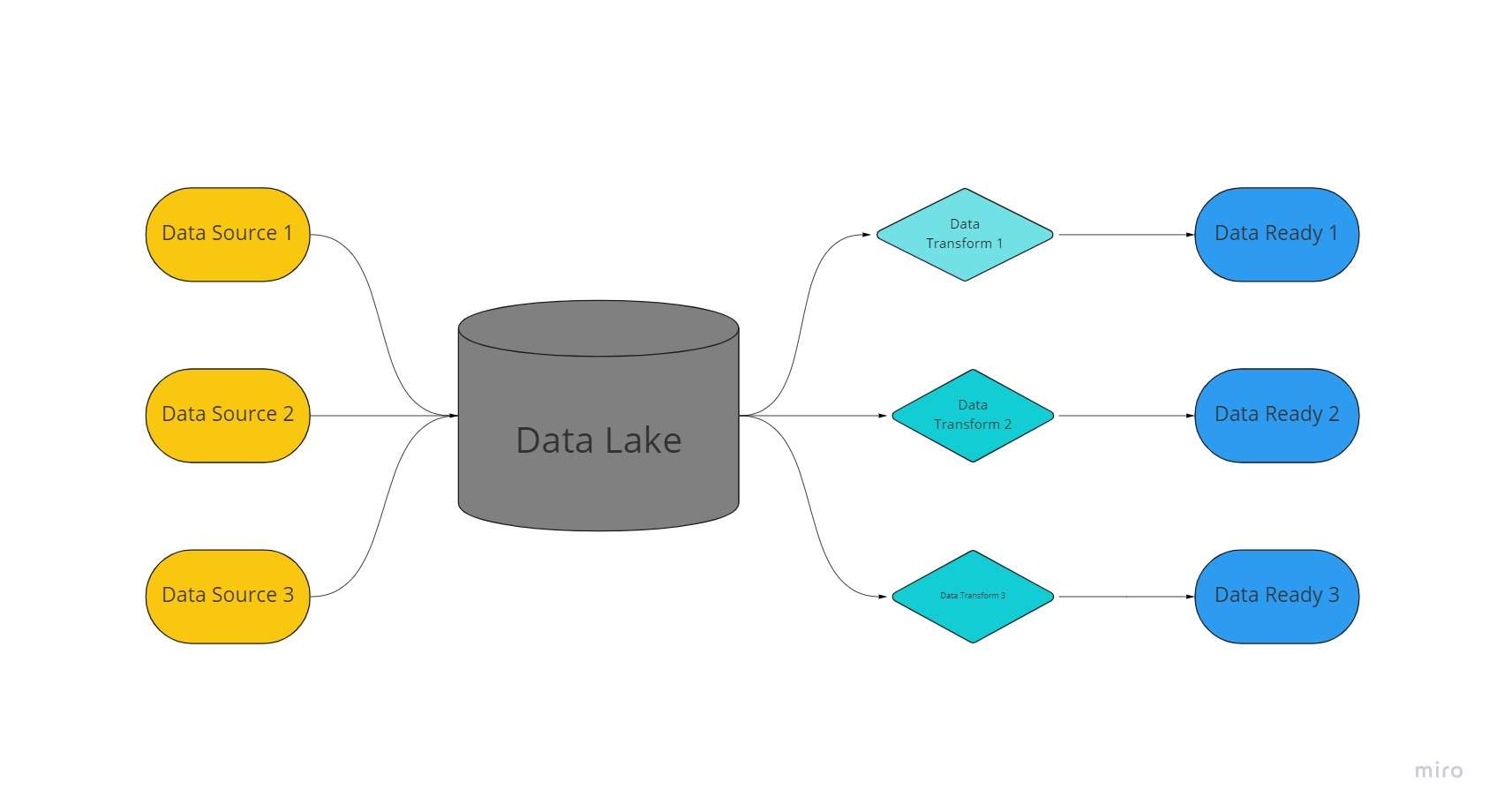
V datových jezerech jsou data extrahována, načítána a transformována (ELT) spíše pro analytické účely, než aby bylo schéma nebo data vytvořena v době shromažďování dat.
Využití technologií pro mnoho druhů dat ze zařízení IoT, sociální médiaa streamování dat, datová jezera umožňují strojové učení a prediktivní analytiku.
Kromě toho může datový vědec, který dokáže zpracovat nezpracovaná data, využít datové jezero. Na druhou stranu datový sklad je pro podniky jednodušší. Je ideální pro profilování uživatelů, prediktivní analýzy, strojové učení a další úkoly.
Přestože datová jezera řeší několik problémů s datovými sklady, jejich kvalita dat je špatná a rychlost jejich dotazů nedostatečná. Podnikovým uživatelům navíc vyžaduje další nástroje k provádění dotazů SQL. Datové jezero, které je špatně strukturované, může mít problém se stagnací dat.
Výhody Data Lake
- Podpora široké škály případů strojového učení a datové vědy Je jednodušší použít jiný strojový algoritmus a algoritmy hlubokého učení ke zpracování dat v datových jezerech, protože data jsou uchovávána otevřeným a nezpracovaným způsobem.
- Velkou výhodou je všestrannost datových jezer, která umožňuje ukládat data v libovolném formátu či médiu bez požadavku na přednastavené schéma. Budoucí případy použití dat mohou být podporovány a může být analyzováno více dat, pokud jsou data ponechána v původním stavu.
- Abychom se vyhnuli nutnosti ukládat oba typy dat v různých kontextech, datová jezera mohou obsahovat strukturovaná i nestrukturovaná data. Pro ukládání různých druhů organizačních dat nabízejí jediné místo.
- Ve srovnání s tradičními datovými sklady jsou datová jezera levnější, protože jsou postavena tak, aby byla udržována na levném komoditním hardwaru, jako je úložiště objektů, které je často zaměřeno na nižší náklady na uložený gigabajt.
Omezení Data Lake
- Případy použití datové analýzy a business intelligence dosahují špatného skóre: Data lakes se mohou stát neorganizovaná, pokud nejsou adekvátně udržována, což ztěžuje jejich propojení s business intelligence a analytickými nástroji. Navíc, pokud je to nutné pro případy použití sestav a analýz, nedostatek konzistentnosti datové struktury a ACID (atomicita, konzistence, izolace a trvanlivost) transakční podpora může vést k suboptimálnímu výkonu dotazů.
- Nekonzistence datových jezer znemožňuje vynutit spolehlivost a bezpečnost dat, což má za následek nedostatek obojího. Může být obtížné vyvinout vhodné standardy zabezpečení dat a řízení, které by vyhovovaly citlivým datovým typům, protože datová jezera mohou zpracovat jakoukoli datovou formu.
Klady
- Řešení, která jsou dostupná pro všechny typy dat.
- Dokáže zpracovat data, která jsou jak organizovaná, tak polostrukturovaná.
- Ideální pro složité zpracování dat a streamování.
Nevýhody
- Potřebuje vybudovat sofistikované potrubí.
- Dejte datům nějaký čas, aby se staly dotazovatelnými.
- Zaručení spolehlivosti a kvality dat vyžaduje čas.
Co je Data Lakehouse?
Nová architektura úložiště velkých dat nazývaná „data lakehouse“ kombinuje největší aspekty datových jezer a datových skladů. Všechna vaše data, ať už strukturovaná, polostrukturovaná nebo nestrukturovaná, mohou být uložena na jednom místě s nejlepšími možnostmi strojového učení, business intelligence a streamingu, které jsou možné díky datovému jezeru.
Data jezera všeho druhu jsou často výchozím bodem pro data lakehouse; poté jsou data převedena do formátu Delta Lake (open-source úložná vrstva, která přináší spolehlivost datovým jezerům).
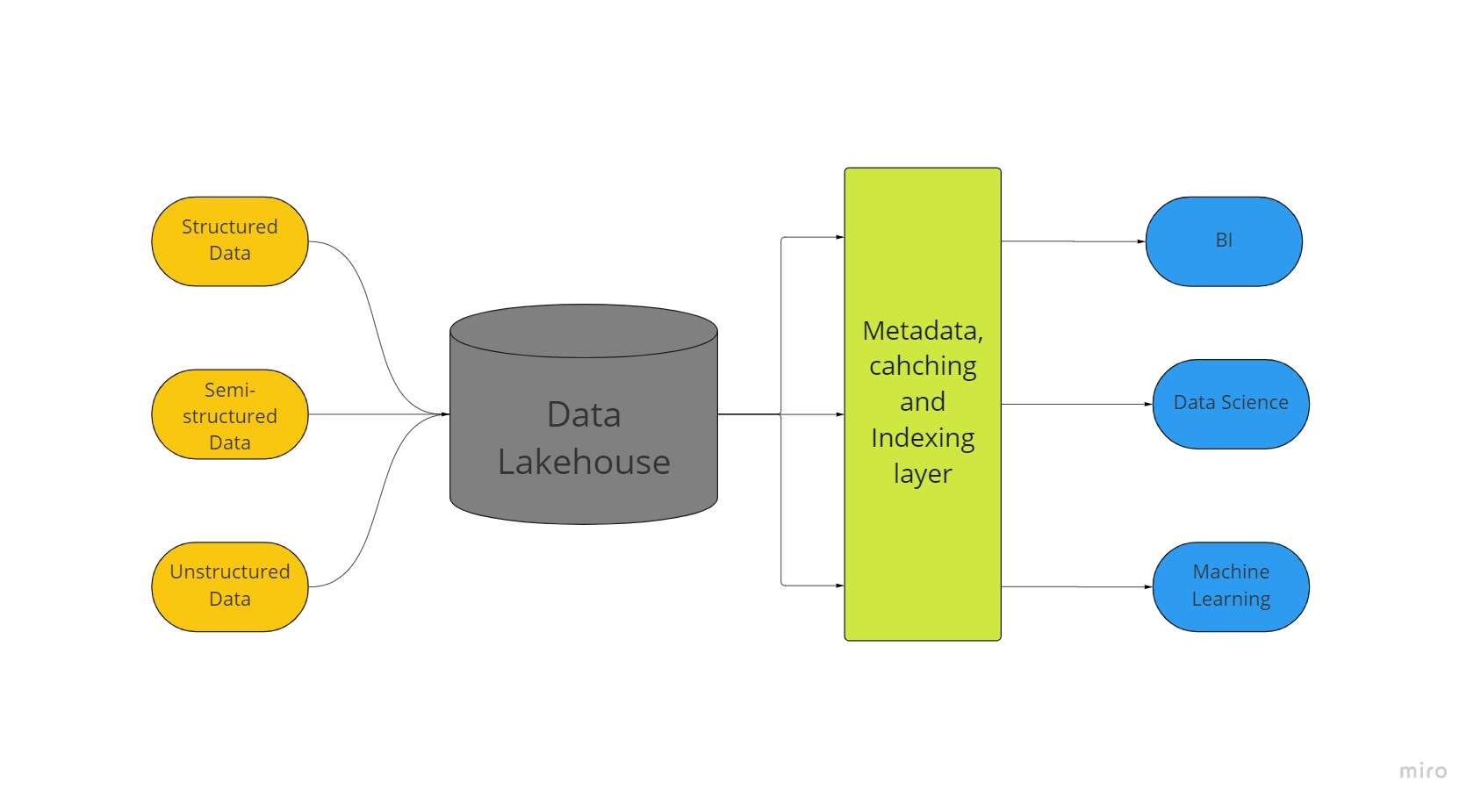
Datová jezera s delta jezera umožňují transakční postupy ACID z konvenčních datových skladů. Systém Lakehouse v podstatě využívá levné úložiště k uchování obrovského množství dat v jejich původních formách, podobně jako datová jezera.
Přidání vrstvy metadat nad úložiště také poskytuje datovou strukturu a posiluje nástroje pro správu dat, jako jsou ty, které se nacházejí v datových skladech.
To umožňuje mnoha týmům přistupovat ke všem firemním datům prostřednictvím jediného systému pro různé iniciativy, jako je datová věda, strojové učení a business intelligence.
Výhody Data Lakehouse
- Podpora většího rozsahu úloh: Pro usnadnění sofistikovaných analýz poskytují data lakehouse uživatelům přímý přístup k některým z nejpopulárnějších nástrojů business intelligence (Tableau, PowerBI). Data mohou navíc snadno používat datoví vědci a inženýři strojového učení, protože datová jezera využívají formáty otevřených dat (jako je Parquet) spolu s rozhraními API a frameworky strojového učení, jako je Python/R.
- Efektivita nákladů: Data lakehouses využívají levná řešení pro ukládání objektů k implementaci nákladově efektivních charakteristik úložiště datových jezer. Nabídkou jediného řešení se data lakehouses také zbaví nákladů a času spojeného se správou různých systémů pro ukládání dat.
- Návrh Data lakehouse zajišťuje integritu schématu a dat, což usnadňuje vytváření efektivních systémů zabezpečení a správy dat. Snadnost verzování dat, správa a bezpečnost.
- Data lakehouses nabízejí jedinou, víceúčelovou platformu pro ukládání dat, která dokáže vyhovět všem požadavkům na data společnosti, což snižuje duplicitu dat. Většina podniků volí hybridní řešení kvůli výhodám jak datového skladu, tak datového jezera. Tato strategie by mezitím mohla vést k nákladné duplikaci dat.
- Podpora otevřených formátů. Otevřené formáty jsou typy souborů, které může používat mnoho softwarových aplikací a jejichž specifikace jsou veřejně dostupné. Podle zpráv jsou Lakehouses schopny ukládat data v běžných souborových formátech, jako je Apache Parquet a ORC (Optimized Row Columnar).
Omezení Data Lakehouse
Největší nevýhodou datového jezera je to, že je to stále mladá a rozvíjející se technologie. Není jisté, zda v důsledku toho splní své závazky. Než budou datová jezera konkurovat zavedeným systémům pro ukládání velkých dat, může to trvat roky.
Vzhledem k rychlosti, s jakou dochází k moderním inovacím, je však těžké říci, zda je nakonec nenahradí jiný systém ukládání dat.
Klady
- Jedna platforma má všechna data, což znamená, že je potřeba udržovat méně názvů hostitelů.
- Atomicita, konzistence, izolace a houževnatost nejsou ovlivněny.
- Je výrazně dostupnější.
- Jedna platforma má všechna data, což znamená, že je potřeba udržovat méně názvů hostitelů.
- Jednoduchá správa a rychlé řešení jakýchkoli problémů
- Usnadněte si stavbu potrubí
Nevýhody
- Nastavení může chvíli trvat.
- Je příliš mladý a příliš vzdálený na to, aby se kvalifikoval jako zavedený skladovací systém.
Datový sklad versus Data Lake versus Data Lakehouse
Datový sklad má dlouhou historii v oblasti podnikové inteligence, reportingu a analytických aplikací a je první technologií pro ukládání velkých dat.
Datové sklady jsou na druhou stranu drahé a mají problémy se zpracováním různorodých a nestrukturovaných dat, jako jsou data streamovaná. Pro úlohy strojového učení a datové vědy byla vyvinuta datová jezera pro správu nezpracovaných dat v různých formách na dostupném úložišti.
Přestože jsou datová jezera efektivní s nestrukturovanými daty, postrádají transakční schopnosti ACID datových skladů, takže je obtížné zaručit konzistenci a spolehlivost dat.
Nejnovější architektura datového úložiště, známá jako „data lakehouse“, kombinuje spolehlivost a konzistenci datových skladů s cenovou dostupností a přizpůsobivostí datových jezer.
Proč investovat do čističky vzduchu?
Závěrem lze říci, že vybudování datového jezera od nuly může být obtížné. Kromě toho budete téměř jistě používat platformu navrženou tak, aby umožňovala otevřenou datovou architekturu lakehouse.
Proto před nákupem buďte opatrní a prozkoumejte mnoho funkcí a implementací každé platformy. Společnosti, které hledají vyspělé, strukturované datové řešení se zaměřením na případy použití business intelligence a datové analýzy, mohou zvážit datový sklad.
Podniky, které hledají škálovatelné a cenově dostupné řešení velkých objemů dat, které posílí pracovní zátěž pro datovou vědu a strojové učení na nestrukturovaných datech, by však měly zvážit datová jezera.
Zvažte, že vaše firma potřebuje více dat, než může poskytnout datový sklad a technologie Data Lake, nebo že hledáte řešení pro integraci sofistikované analýzy a operací strojového učení do vašich dat. A datový jezerní dům je v dané situaci rozumná možnost.





Napsat komentář