Table di cuntinutu[Piattà][Mostra]
I video games cuntinueghjanu à furnisce una sfida à miliardi di ghjucatori in u mondu. Puderete ùn sapete micca ancu, ma l'algoritmi di apprendimentu automaticu anu cuminciatu à risaltà ancu à a sfida.
Ci hè attualmente una quantità significativa di ricerca in u campu di l'IA per vede se i metudi d'apprendimentu automaticu ponu esse applicati à i video games. U prugressu sustinibili in stu campu mostra chì machine learning agenti pò esse usatu per emulà o ancu rimpiazzà u ghjucatore umanu.
Chì significarà questu per u futuru games?
Sò questi prughjetti solu per divertimentu, o ci sò ragioni più profonde per quessa chì tanti circadori si focalizanu nantu à i ghjoculi?
Questu articulu hà da scopre brevemente a storia di l'AI in i video games. Dopu, vi daremu una rapida panoramica di alcune tecniche di apprendimentu automaticu chì pudemu aduprà per amparà à batte i ghjochi. Fighjemu dopu à qualchi appiicazioni successu di reti neurali per amparà è ammaistrà i video games specifichi.
Breve storia di l'IA in Lusinghi
Prima di entrà in u perchè e reti neurali sò diventate l'algoritmu ideale per risolve i video games, guardemu brevemente cumu l'informatica anu utilizatu i video games per avanzà a so ricerca in AI.
Pudete argumentà chì, da u so principiu, i video games sò stati una zona calda di ricerca per i circadori interessati à l'AI.
Mentre ùn hè micca strettamente un video game in origine, i scacchi hè statu un grande focus in i primi tempi di AI. In u 1951, u duttore Dietrich Prinz hà scrittu un prugramma di ghjocu di scacchi cù l'urdinatore digitale Ferranti Mark 1. Questu era in l'era quandu questi computer voluminosi avianu a leghje i prugrammi fora di a cinta di carta.

U prugramma stessu ùn era micca una IA di scacchi cumpleta. A causa di e limitazioni di l'urdinatore, Prinz puderia solu creà un prugramma chì risolve i prublemi di mate-in-two scacchi. In media, u prugramma hà pigliatu 15-20 minuti per calculà ogni muvimentu pussibule per i ghjucatori bianchi è neri.
U travagliu nantu à a migliurà l'intelligenza artificiale di scacchi è checkers hà migliuratu constantemente in i decennii. U prugressu hà righjuntu u so culmine in u 1997 quandu Deep Blue d'IBM hà scunfittu u gran maestru di scacchi russu Garry Kasparov in un paru di partite di sei partite. Oghje, i mutori di scacchi chì pudete truvà nantu à u vostru telefuninu pò scunfighja Deep Blue.
L'avversari di l'AI cuminciaru à guadagnà pupularità durante l'età d'oru di i video games arcade. Space Invaders di 1978 è Pac-Man di l'anni 1980 sò alcuni di i pionieri di l'industria in a creazione di IA chì ponu sfida abbastanza ancu i più veterani di i gamers arcade.
Pac-Man, in particulare, era un ghjocu populari per i circadori AI per sperimentà. Diversi cuncorsi per a Sra Pac-Man sò stati urganizati per determinà quale squadra puderia vene cun u megliu AI per batte u ghjocu.
L'AI di u ghjocu è l'algoritmi heuristici anu continuatu à evoluzione cum'è a necessità di avversari più intelligenti hè ghjunta. Per esempiu, u cummattimentu AI hà aumentatu in pupularità cum'è i generi cum'è i shooters in prima persona sò diventati più mainstream.
Machine Learning in Video Games
Siccomu e tecniche d'apprendimentu di a macchina anu aumentatu rapidamente in pupularità, diversi prughjetti di ricerca anu pruvatu à utilizà sti novi tecniche per ghjucà à i video games.
Ghjochi cum'è Dota 2, StarCraft è Doom ponu agisce cum'è prublemi per questi algoritmi di apprendimentu di macchina scioglie. Algoritmi di apprendimentu profondu, in particulare, anu sappiutu ghjunghje è ancu superà e prestazioni à livellu umanu.
lu Ambiente di apprendimentu arcade o ALE hà datu i circadori una interfaccia per più di centu ghjochi Atari 2600. A piattaforma open-source hà permessu à i circadori di benchmarkà e prestazioni di e tecniche di apprendimentu automaticu nantu à i video games Atari classici. Google hà ancu publicatu u so propiu a carta usendu sette partite da l'ALE

Intantu, prughjetti cum'è VizDoom hà datu i circadori AI l'uppurtunità di furmà algoritmi di apprendimentu di machine à ghjucà à i shooters 3D in prima persona.

Cumu Funziona: Certi Cuncepzioni Chjave
Reti Neurali
A maiò parte di l'avvicinamenti per risolve i video games cù l'apprendimentu automaticu implicanu un tipu d'algoritmu cunnisciutu com'è rete neurale.
Pudete pensà à una rete neurale cum'è un prugramma chì prova di imite cumu un cervellu puderia funziunà. Simile à cumu u nostru cervellu hè cumpostu di neuroni chì trasmettenu un signalu, una rete neurale cuntene ancu neuroni artificiali.
Sti neuroni artificiali trasfiriscenu ancu signali à l'altri, cù ogni signalu essendu un numeru propiu. Una rete neurale cuntene parechje strati trà i strati di input è output, chjamati una rete neurale profonda.
Imparazione di rinfurzamentu
Un'altra tecnica di apprendimentu automaticu cumuni per l'apprendimentu di i video games hè l'idea di l'apprendimentu di rinforzu.
Sta tecnica hè u prucessu di furmà un agentu cù ricumpensa o punizioni. Cù stu approcciu, l'agente deve esse capace di truvà una suluzione à un prublema per mezu di prucessu è errore.
Diciamu chì vulemu un AI per sapè cumu ghjucà u ghjocu Snake. L'obiettivu di u ghjocu hè simplice: uttene u più punti pussibule cunsumendu l'articuli è evitendu a vostra coda chì cresce.
Cù l'apprendimentu di rinfurzà, pudemu definisce una funzione di ricumpensa R. A funzione aghjunghje punti quandu un Serpente cunsuma un articulu è deduce punti quandu u Serpente tocca un ostaculu. Data l'ambiente attuale è un inseme d'azzioni pussibuli, u nostru mudellu di apprendimentu di rinforzu pruverà à calculà a "pulitica" ottimale chì maximizeghja a nostra funzione di ricumpensa.
Neuroevoluzione
Mantene in u tema di esse inspirati da a natura, i circadori anu ancu truvatu successu in l'applicazione di ML à i video games per mezu di una tecnica cunnisciuta cum'è neuroevolution.
Invece di aduprà discesa di gradiente per aghjurnà i neuroni in una reta, pudemu usà algoritmi evoluzione per ottene risultati megliu.
L'algoritmi di l'evoluzione tipicamente cumincianu generendu una populazione iniziale di individui aleatorii. Dopu valutemu questi individui utilizendu certi criterii. I migliori individui sò scelti cum'è "genitori" è sò criati inseme per furmà una nova generazione di individui. Questi individui anu da rimpiazzà l'individui i più menu adattati in a pupulazione.
Questi algoritmi sò ancu tipicamenti introducenu una certa forma di operazione di mutazione durante u passaghju di crossover o di "rilevamentu" per mantene a diversità genetica.
Sample Research in Machine Learning in Video Games
OpenAI Five

OpenAI Five hè un prugramma di computer di OpenAI chì hà da scopu di ghjucà DOTA 2, un popular ghjocu di battaglia mobile multiplayer (MOBA).
U prugramma hà sfruttatu e tecniche di apprendimentu di rinforzu esistenti, scalate per amparà da milioni di fotogrammi per seconda. Grazie à un sistema di furmazione distribuitu, OpenAI hà sappiutu ghjucà 180 anni di ghjoculi ogni ghjornu.
Dopu à u periodu di furmazione, OpenAI Five hà sappiutu ottene un rendimentu di livellu espertu è dimustrà a cooperazione cù i ghjucatori umani. In 2019, OpenAI cinque hà sappiutu scunfitta 99.4% di i ghjucatori in partiti publichi.
Perchè OpenAI hà decisu di stu ghjocu? Sicondu i circadori, DOTA 2 avia una meccanica cumplessa chì era fora di a portata di a prufundità esistente appruvamentu rinforzu algoritmi.
Super Mario Pasqualinu
Un'altra applicazione interessante di e reti neurali in i video games hè l'usu di a neuroevoluzione per ghjucà platformers cum'è Super Mario Bros.
Per esempiu, questu entrata Hackathon principia cù ùn avè micca cunniscenze di u ghjocu è lentamente custruisce una basa di ciò chì hè necessariu per avanzà à traversu un livellu.
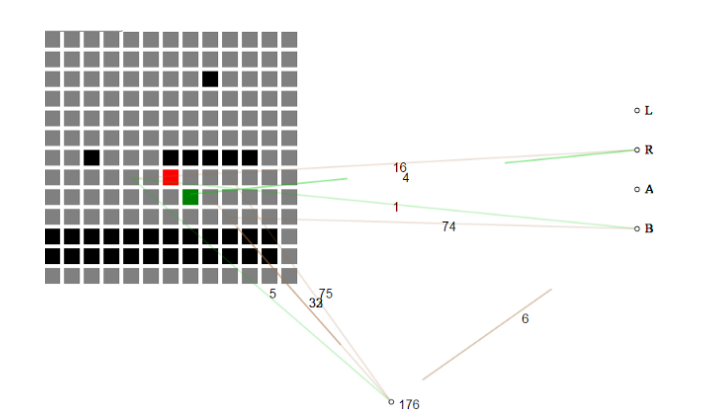
A rete neurale autoevolutiva piglia in u statu attuale di u ghjocu cum'è una griglia di piastrelle. À u principiu, a rete neurale ùn hà micca capitu di ciò chì ogni tile significa, solu chì i tile "aria" sò diffirenti di "tettu di terra" è di "tettu nemicu".
L'implementazione di u prughjettu di l'hackathon di una neuroevoluzione hà utilizatu l'algoritmu geneticu NEAT per allevà diverse reti neurali selettivamente.
Impurtanza
Avà chì avete vistu alcuni esempi di reti neurali chì ghjucanu à i video games, pudete esse dumandatu quale hè u puntu di tuttu questu.
Siccomu i video games implicanu interazzioni cumplessi trà l'agenti è i so ambienti, hè u terrenu di prova perfettu per fà AI. L'ambienti virtuali sò sicuri è cuntrullabili è furnisce un supply infinitu di dati.
A ricerca fatta in questu campu hà datu à i circadori una visione di cumu e rete neurali ponu esse ottimisate per amparà cumu risolve i prublemi in u mondu reale.
Rete neurale sò ispirati da u funziunamentu di u cervellu in u mondu naturali. Studiendu cumu si cumportanu i neuroni artificiali quandu amparanu à ghjucà à un video game, pudemu ancu capisce cumu si u sensu umanu lavora.
cunchiusioni
Similitudini trà e rete neurali è u cervellu anu purtatu à insights in i dui campi. A ricerca cuntinua nantu à cumu e reti neurali ponu risolve i prublemi pò purtà un ghjornu à forme più avanzate ntilliggenza artificiali.
Immaginate d'utilizà una AI adattata à e vostre specificazioni chì pò ghjucà un ghjocu video sanu prima di cumprà per fà sapè s'ellu vale a pena u vostru tempu. L'imprese di videogiochi utilizanu reti neurali per migliurà u disignu di u ghjocu, u nivellu di tweak è a difficultà avversaria?
Chì pensate chì succederà quandu e reti neurali diventanu l'ultimi gamers?





Lascia un Audiolibro