U web scraping hè diventatu un metudu cruciale per ottene dati insightful da e plataformi Internet in a sucietà di data-driven d'oghje.
Cum'è un situ di media suciale estremamente populari, Instagram furnisce assai materiale generatu da l'utilizatori. È, sti dati generati ponu esse aduprati per u marketing, a ricerca è altre ragioni.
L'utilizatori ponu estrae dati da Instagram cun facilità è efficacità grazia à i scrapers Instagram ricchi di funzioni di Bright Data, un capu di punta. scraping web strumentu. In questu post, daremu una guida dettagliata, passu per passu, di u prucessu di scraping Instagram.
Allora, andemu à vede i passi per cumu pudemu scrape data da Instagram.
Capisce Instagram Scrapers da Bright Data
Cù l'aiutu di dui web scrapers all-purpose è un dataset pre-cumpilatu, Bright Data furnisce una varietà di servizii di scraping Instagram. Queste tecnulugia offre versatilità in l'estrazione di dati è adattanu à diverse esigenze.
Esaminemu ognuna di queste scelte in più detail:
a. Scraping Browser
A tecnulugia innovativa cunnisciuta cum'è Scraping Browser hè stata creata per risponde à e dumande di i prughjetti di scraping di dati. Offre tuttu ciò chì hè necessariu per scraping in scala in un solu navigatore. Si distingue grazia à a so automatizazione integrata di sbloccamentu di u situ web, chì face u solu navigatore di u so tipu in u mondu sanu.
Scraping Browser dà à l'utilizatori l'accessu à e funzioni robuste chì vanu oltre i navigatori automatizzati è senza testa, chì li permettenu di passà ancu i scripts più difficili è i barrieri di u situ web per a rilevazione di bot.
U scraping di dati hè più efficau è senza fastidiu per via di e so funzioni di regulazione automatizata, chì gestisce facilmente blocchi freschi, soluzioni CAPTCHA, impronte digitali è riprova, è appare cum'è un veru utilizatore.
Utilizà l'AI per superà i sistemi di rilevazione di bot
Utilizendu a tecnulugia AI d'avanguardia, Scraping Browser pò superà i sistemi di rilevazione di bot è aghjustà continuamente à e so strategie di cambiamentu. Per sbloccare megliu e pagine web, Scraping Browser ampara da i tentativi di questi sistemi di detectà è bluccà i tentativi di scraping è mudifica u so cumpurtamentu in modu adattatu.
Supera l'efficienza di i proxy convenzionali imitando u cumpurtamentu di un navigatore utilizatu da un veru utilizatore. In u risultatu, i clienti ponu cuncentrazione nantu à i so scopi per u scraping di dati senza avè affruntà a difficultà è a spesa di i prucessi di deteczione di bot.
b. Web Scraper IDE
Un strumentu di scraping web robustu creatu per i sviluppatori, Web Scraper IDE pò gestisce compiti cumplessi di scraping. Reduce considerablemente u tempu di sviluppu mentre furnisce una scalabilità infinita grazia à a so suluzione cumplettamente ospitata è e funzioni di scraping pre-custruite. L'applicazione permette a custruzzione rapida è scalabile di scrapers in linea furnisce mudelli di codice è funzioni JavaScript pronti da siti web populari.
Tuttu ciò chì hè necessariu per u web scraping successu hè furnitu da u Web Scraper IDE. Hè una soluzione cumpleta per l'estrazione di dati in linea, postu chì l'opzioni di integrazione permettenu à i clienti di pianificà i crawls o di lanciarli attraversu l'API è ligà cù i principali sistemi di almacenamento.
Cumu aduprà? - Tutorial
Prima, navigate à u dashboard di l'utilizatori nantu à u situ web.

Cuminciamu cù i nostri passi per scrape Instagram.
1- Navigate à u Escrivania è cliccate nantu à a sezione Datasets & Web Scraper IDE.
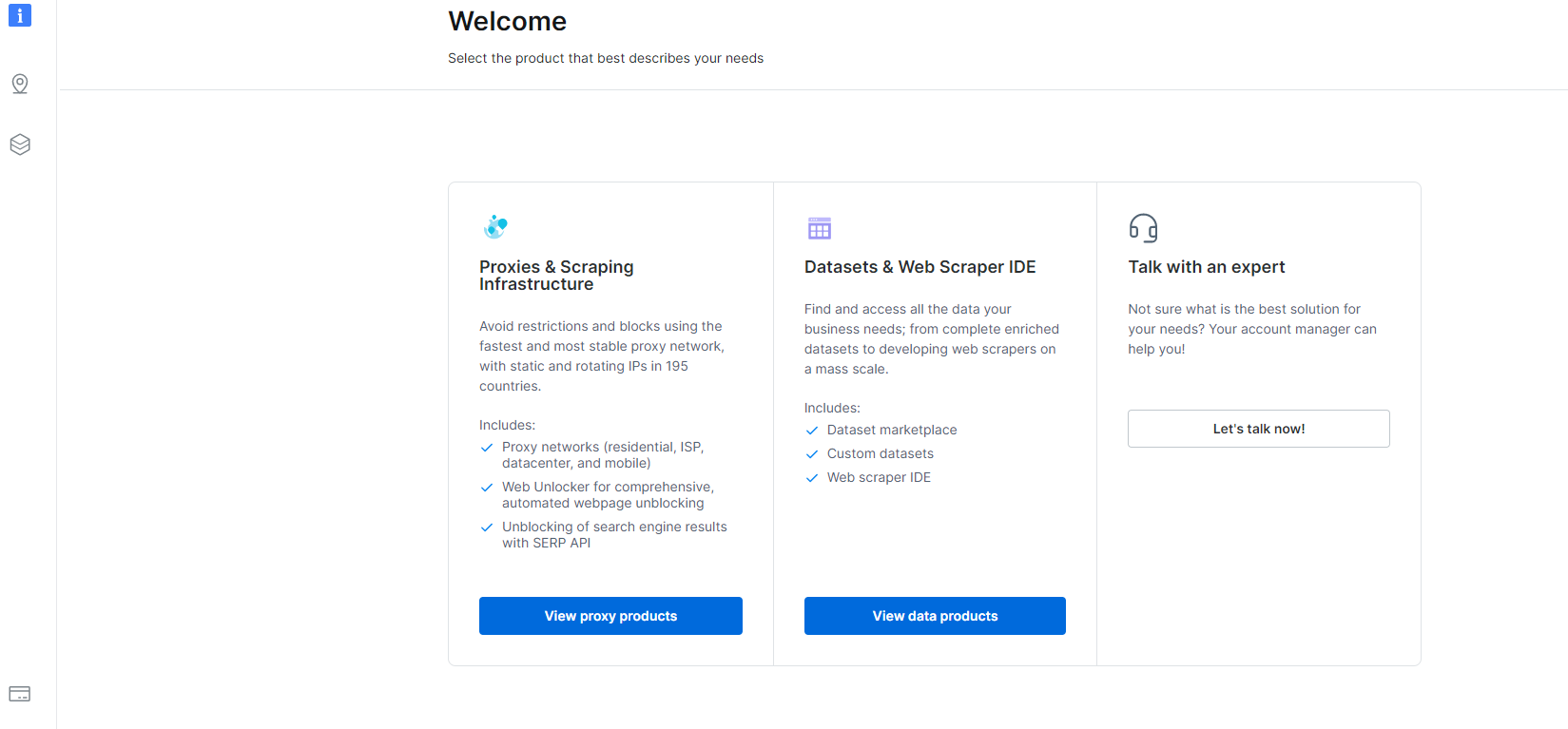
2- Una volta, vi sò quì, cliccate nant'à My Scrapers.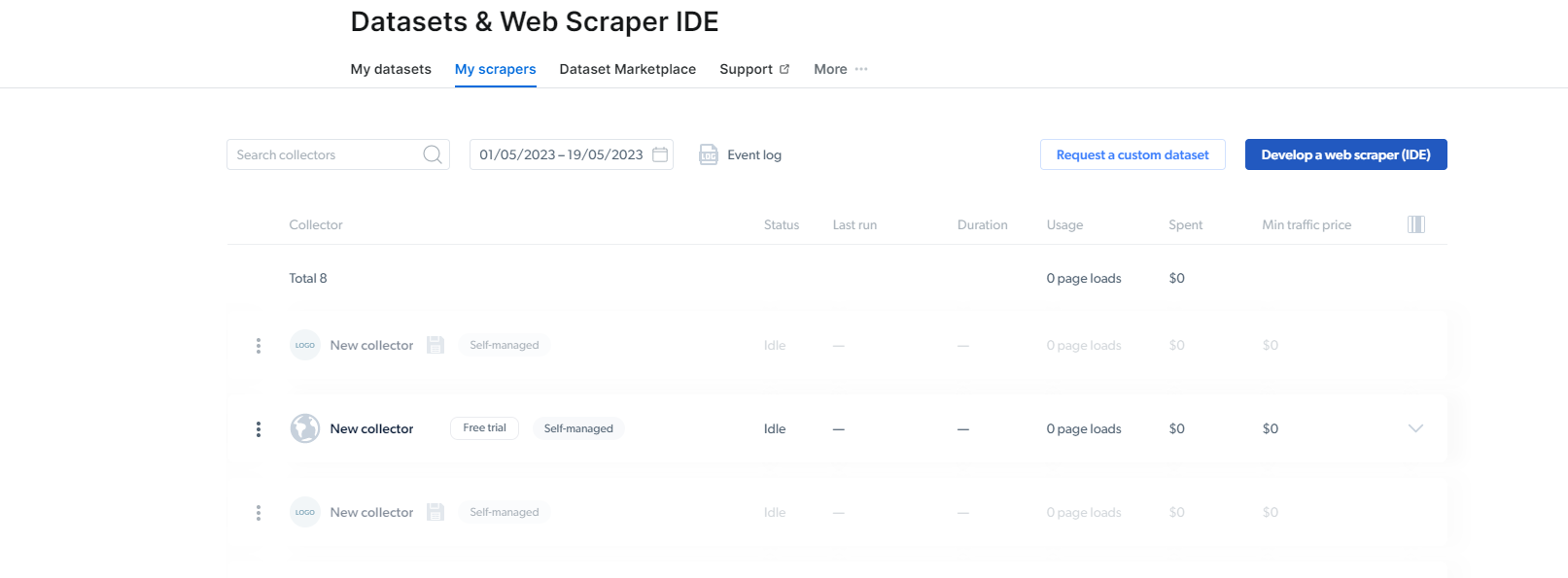
Quì, avete bisognu di cliccà nantu à "Sviluppà un web scraper (IDE)". Quì creeremu u nostru scraper per Instagram.
3-Ora, avemu bisognu di sviluppà un novu web scraper. Solu per questu esempiu, aghju sceltu di scrape u contu "NASA". Questu hè solu per questu esempiu.
Allora, u mo codice sarà cusì:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Avete bisognu di cliccà nantu à u buttone "play" in cima à diritta per eseguisce stu codice.
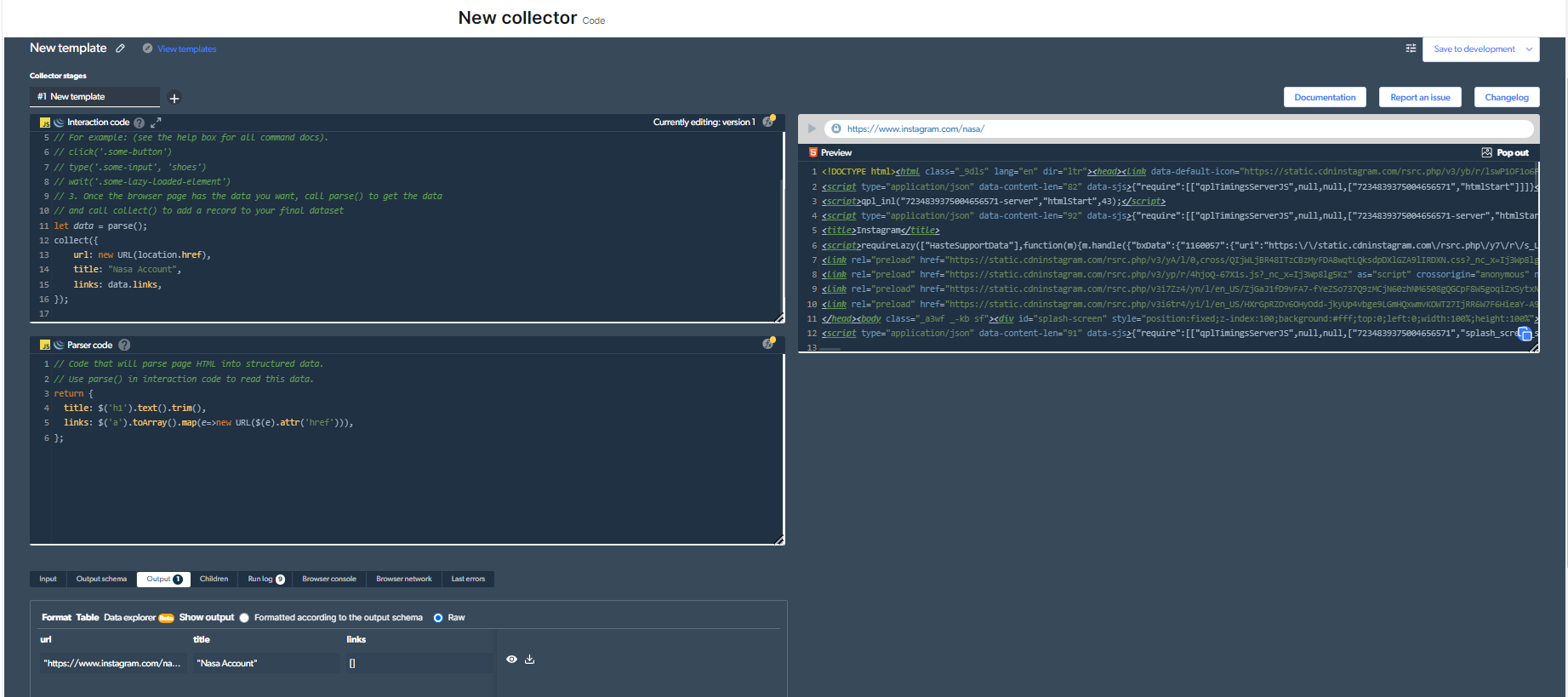
4- Avà, averemu un output.
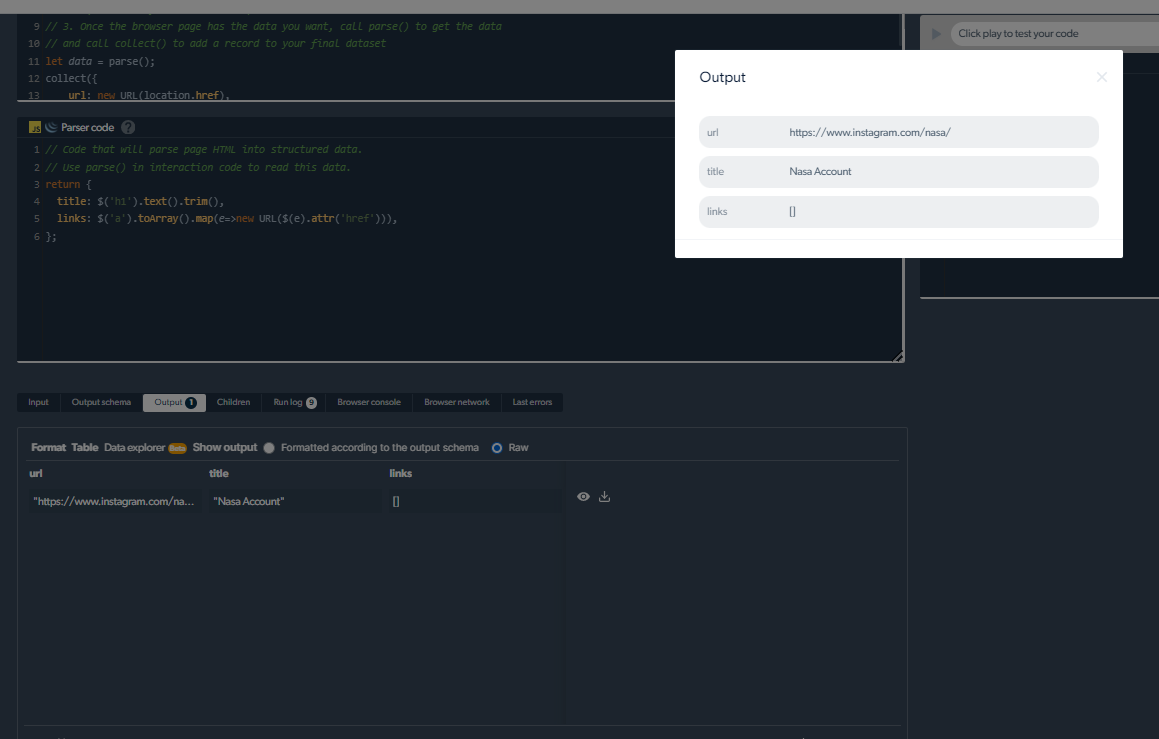
Gestisce i prublemi di scraping
I posti di Instagram cù u "mostra più buttone" puderanu esse difficili per i scrapers per catturà. Tuttavia, i scrapers d'Instagram da Bright Data sò fatti per trattà cun successu tali cumplessità. Questi scrapers anu cumpetenze d'avanguardia per traversà a paginazione è a carica di i buttoni supplementari.
I scrapers d'Instagram di Bright Data trattanu in modu efficace queste difficultà per attivà l'estrazione di dati approfondita, chì vi permette di cullà tutta a cullizzioni di informazioni necessarie per a vostra analisi o studiu.
Pudete aggirà e sfide presentate da a natura dinamica di i posti Instagram utilizendu sti strumenti di scraping.
c. Dataset pre-cullatu
Bright Data capisce chì micca tutti volenu curriri u so scraper. Forniscenu un inseme di dati pre-cullatu per Instagram per appellu à tali cunsumatori.
Stu dataset offre una ricchezza di informazioni utili, cum'è seguitori, profili, posti, è più.
Bright Data offre opzioni di persunalizazione per persunalizà u dataset à i vostri bisogni, se vulete un inseme di dati sanu o un subset di dati specializati. Stu approcciu evita a custruzzione è a gestione di un scraper, dendu dati pronti à aduprà per l'analisi è insights.
Avà, cuntrollemu l'infrastruttura chì rende questi strumenti cusì efficace: l'infrastruttura proxy è Web Unlocker.
Scala u putere di i proxy
Praticà pruyti hè cruciale durante u web scraping per assicurà chì e vostre azzioni passanu inosservate.
Bright Data furnisce una larga scelta di servizii proxy chì sò persunalizati à i vostri bisogni. Pudete sceglie da Proxies Residenziale, chì offrenu più di 72 milioni di IP rotati da i dispositi reale in 195 nazioni.
Pudete sceglie Proxies ISP, chì offrenu 700,000 770,000+ IP di casa reale in u mondu per un usu à longu andà; Datacenter Proxies, chì anu più di 3 4 IP spartuti da ogni geolocalizzazione; è Mobile Proxies, chì formanu a più grande rete mobile 7,000,000G/XNUMXG reale cù XNUMX+ IP.
Cù l'usu di sti proxies, unu pò facilmente raccoglie dati mentre posanu cum'è un utilizatore autorizatu in numerosi lochi.

Proxy Manager: rende a gestione di proxy più faciule
A gestione di parechji proxy pò esse difficiule, ma Proxy Manager facilita a facilità.
Questa interfaccia open-source vi permette di gestisce tutti i vostri proxy da una sola piattaforma. Dì addiu à l'impostazioni manuali è u cambiamentu di proxy. Proxy Manager simplifica a prucedura è vi risparmia tempu è sforzu.
Proxy Browser Extension: Cambia facilmente a vostra posizione
Avete bisognu di cullà dati web da parechje regioni? Sò cuparti da a nostra Estensione di Browser Proxy. Pudete cambià u vostru locu di navigazione cun un solu clic per ottene infurmazioni specifiche di a regione.
Approfitta di a flessibilità è a simplicità di a cullizzioni di dati da parechje regioni senza alcuna cumplicazione tecnologica.
Cumu Funziona? - Tutorial
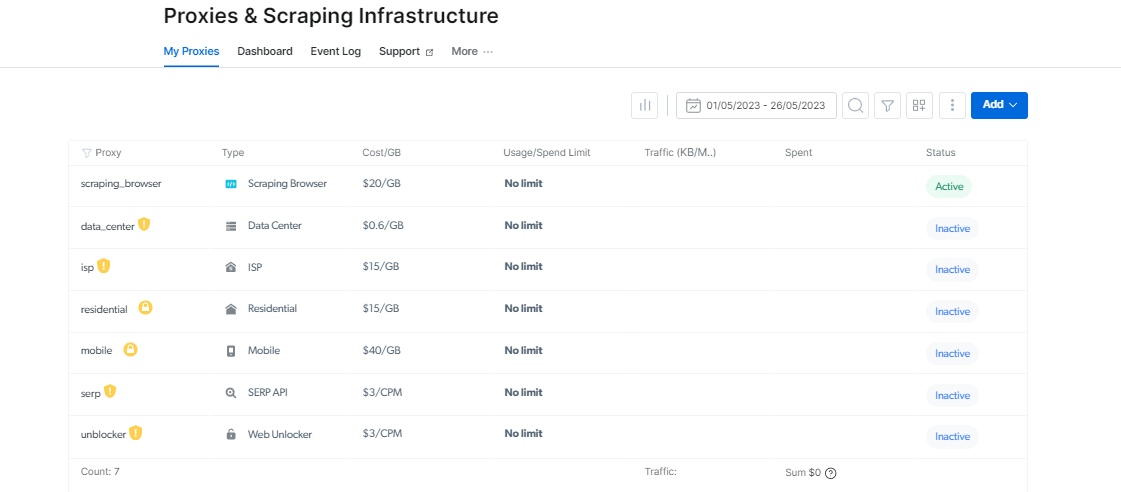
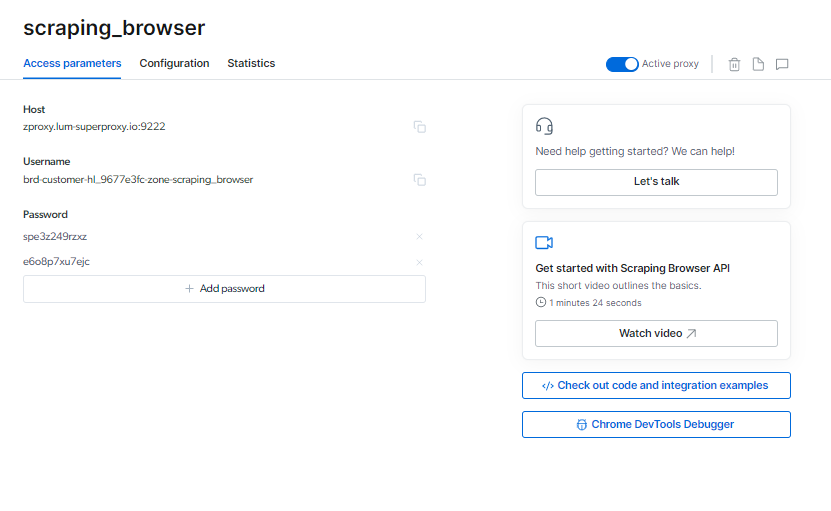
Pudete truvà u vostru Scraping Browser infurmazione di login nantu à a pagina di paràmetri di Accessu, chì serà utilizatu quandu avete principiatu una nova sessione di navigatore.
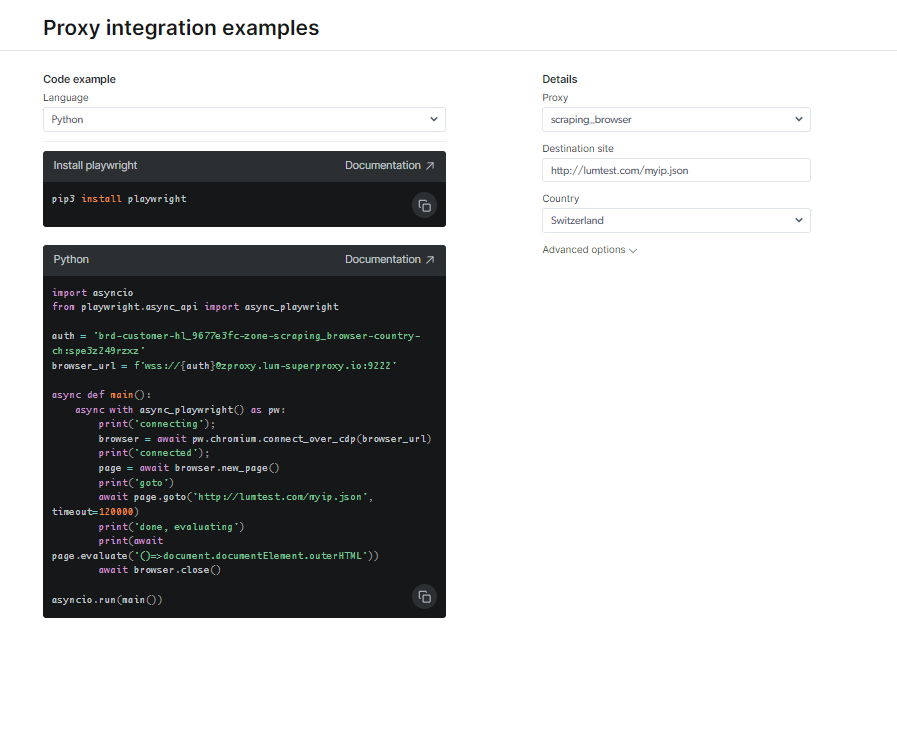
Scuprite a documentazione è i campioni di codice, cumprese un script d'esempiu cumplettamente funziunale chì hè prontu à aduprà, o fighjate un brevi video di struzzioni di partenza. Per esempiu; quì hè a Codice Python esempiu per l'integrazione:
Vulete assistenza? Per una conversazione cù unu di i specialisti, pudete clicà l'icona di chat.
Tenite in mente chì avete un cuntrollu tutale di e sessioni di u navigatore mentre utilizate Scraping Browser è pudete fà qualsiasi operazione chì hè supportata da Puppeteer, Playwright, o l'usu direttu di u Protocol Chrome DevTools.
Unlocking di u situ web senza blocchi
Scraping Browser hè fattu per operare à scala è quantu necessariu. Ùn avete bisognu di preoccupassi di esse pruibitu; pudete inizià quante sessioni di navigatore chì avete bisognu.
Sta capacità, quandu hè assuciata cù a forza di i proxy, guarantisci a cuntinuu di a raccolta di dati, chì vi permette di ottene in modu efficace e dati chì vulete.
E cumpetenze di sbloccamentu integrate di Scraping Browser è una robusta rete proxy vi aiutanu à risparmià tempu, à rinfurzà a produtividade è à scopre novi opportunità.
Pudete ancu verificà e statistiche direttamente da a stessa pagina.
Prezzi di Scraping Browser
Bright Data furnisce scelte di prezzi persunalizabili per scuntrà una varietà di scopi. Pudete sceglie un periodu di fattura mensuale o annuale.
L'opzione Pay as You Go permette di pagà solu per ciò chì aduprate, senza impegnu necessariu, cuminciendu da $ 20.00 / GB è $ 0.1 / ora.
U pianu di crescita di $ 500 hè adattatu per l'imprese in crescita, cù una tarifa scontata di $ 15.30 / GB è $ 0.1 / ora.
lu pacchettu cummerciale, chì costa $ 1000, hè l'opzione più populari, cù l'API Scraping Browser chì costa $ 13.50 / GB è $ 0.1 / ora.
Cuntattendu direttamente a squadra di Bright Data, l'utilizatori di l'impresa ponu gode di una scala infinita è di prezzi persunalizati. Cumincià una prova gratuita oghje per scopre u putenziale di u Browser Scraping di Bright Data è cambià i vostri sforzi di scraping in linea.
Unlocker di u situ web
Web Unlocker hè un strumentu putente creatu per passà oltre e restrizioni di u situ web è furnisce una raccolta di dati faciule. Supera parechje sfide, cumprese i cookies, l'agenti d'utilizatori di u navigatore specificu di u situ, è e soluzioni captcha, utilizendu prucedure automatizate.
Utilizendu a rotazione automatica di l'indirizzu IP, l'utilizatori di Web Unlocker ponu scaccià continuamente i siti web di destinazione, assicurendu un accessu constante à e dati impurtanti.
Aumentà i viaghji di dumanda di sviluppatore
Diversi funziunalità facenu Web Unlocker populari trà i sviluppatori. U prugramma simplifica u prucessu di raccolta di dati identificendu automaticamente l'agenti d'utilizatori necessarii per ogni situ web, risparmiendu tempu è risorse preziosi.
Web Unlocker si adatta in tempu reale per evità a rilevazione in risposta à e strategie in constantemente cambiante utilizzate da i bots bluccati, assicurendu un accessu cuntinuu à i siti web d'interessu. L'algoritmi di apprendimentu automaticu di a piattaforma ponu risolve rapidamente i captchas, un ostaculu frequente à l'iniziativi di raccolta di dati.

Prezzi di Web Unlocker
Partendu da circa $ 2.03 per mille richieste (CPM), Web Unlocker offre parechje opzioni di prezzu per risponde à diverse richieste. Una prova gratuita di 7 ghjorni hè dispunibule per l'utilizatori per avè principiatu è lascià elli à pruvà e funzioni di Web Unlocker prima di impegnà.
Web Unlocker hà l'adattabilità per supportà diversi mudelli d'utilizazione, indipendentemente da chì i cunsumatori volenu un approcciu di pagamentu per via o avè bisognu di un pianu persunalizatu adattatu à i so bisogni particulari. Inoltre, quelli chì sceglienu piani di prezzu à longu andà puderanu salvà 32%.
Paragone trà Web Unlocker cù Proxies Self-Managed
Web Unlocker offre numerosi benefici istantanei sopra i proxy autogestionati. Per una implementazione liscia, offre una tecnica d'integrazione estensiva chì combina funzioni super proxy è Proxy Manager. L'utilizatori ponu scala in modu efficace e so operazioni di raccolta di dati cù un numeru infinitu di cunnessione simultanea.
Web Unlocker offre un sbloccamentu automaticu, risolve CAPTCHAs, è gestisce cù successu mudificazioni di marcatura in siti web di destinazione.
A piattaforma guarantisci l'estrazione di dati cuntinuu è affidabile implementendu un sistema di riprovazione automatica è facendu chiamate asincrone per certi domini. Inoltre, a cullezzione crescente di Unlocker in linea di richieste di intestazioni HTTP, cookies di navigatore specifichi di u situ, è gadgets simulati permette à l'utilizatori di stà indetectatu mentre li permette di acquistà dati in linea in tempu reale.
Pensieri finali è cose impurtanti da ricurdà
Infine, mentre aduprate Bright Data per u scraping Instagram, hè criticu di mantene uni pochi di punti vitali in mente.
Per piacè nutate chì e so capacità di scraping sò limitati à e dati dispunibuli publicamente, da pratiche etiche.
Duvete sempre seguità i termini di serviziu di Instagram è e pulitiche di privacy. Scraping deve esse fattu in modu eticu è rispunsevuli, senza intruduce in i diritti di l'utilizatori o rompe alcuna lege.
Siconda, aghjurnà è aghjurnà i vostri paràmetri di scraping regularmente per assicurà a precisione è a pertinenza di e dati recuperati. A piattaforma è l'algoritmi d'Instagram sò sottumessi à cambià, dunque duvete cambià e vostre strategie di scraping in cunseguenza.
Infine, utilizate l'aiutu è e risorse di a piattaforma Bright Data per ottimisà u successu di i vostri sforzi di scraping Instagram. Impegnate cù a so documentazione, i tutoriali è u serviziu di u cliente per migliurà a vostra cunniscenza di i so strumenti di scraping.
Pudete acquistà insights utili, influenzà a decisione sàvia, è riesce in e vostre iniziative basate nantu à i dati nantu à a piattaforma Instagram seguendu queste migliori pratiche è utilizendu a forza di e capacità di scraping Instagram di Bright Data.





Lascia un Audiolibro