Taula de continguts[Amaga][Espectacle]
La nova i millorada IA ha millorat les habilitats, la comprensió i la capacitat de produir imatges de major resolució. Potser darrerament us heu trobat amb imatges estranyes i divertides que surten per Internet.
Un gos Shiba Inu va vestit amb una boina i un coll negre. I una llúdriga marina a la manera de "La noia amb una arracada de perla" del pintor holandès Vermeer. I hi ha una tassa de sopa que sembla un monstre de llana.
Aquestes imatges no van ser creats per un artista humà.
En canvi, les va crear DALL-E 2, un nou sistema d'IA que pot convertir descripcions textuals en imatges.
Simplement escriviu el que voleu veure i l'IA el crearà per a vosaltres: amb detalls vívids, gran qualitat i, en alguns casos, genuïna inventiva. En aquesta publicació, farem una ullada a fons a l'últim estudi d'OpenAI, DALL.E 2, així com a com funciona i molt més. Comencem.
Llavors, què és exactament DALL.E 2?
DALL-E 2 és un "model generatiu", un tipus d'algorisme d'aprenentatge automàtic que genera sortides complicades en lloc de realitzar tasques de predicció o classificació de dades d'entrada.
Proporcioneu a DALL-E 2 una descripció escrita i crea una imatge que hi correspon. En combinar conceptes, qualitats i estils, DALLE 2 d'OpenAI pot produir gràfics i art innovadors i realistes a partir d'una descripció lingüística bàsica.
Es diu que la darrera versió, DALLE 2, és més versàtil, capaç de fer imatges a partir de subtítols a resolucions més altes i en un espectre més ampli d'estils creatius. Per exemple, les imatges següents (de la publicació del bloc DALL-E 2) estan creades per la descripció "Un astronauta muntant a cavall".
Una descripció conclou, "com un esbós a llapis", mentre que l'altra conclou, "d'una manera fotorealista".

També pot canviar les fotografies existents amb una precisió sorprenent. Per tant, podeu afegir o suprimir elements mantenint els colors, els reflexos i les ombres, tot mantenint l'aspecte de la imatge original.
Com funciona?
DALL-E 2 fa ús de models CLIP i de difusió, dos sofisticats aprenentatge profund enfocaments desenvolupats en els darrers anys. Tanmateix, es basa en la mateixa noció que totes les altres profundes xarxes neuronals: aprenentatge de la representació. CLIP n'entrena simultàniament dos xarxes neuronals en imatges i subtítols.
Una xarxa aprèn les representacions visuals de la imatge, mentre que l'altra aprèn les representacions del text. Durant l'entrenament, les dues xarxes intenten modificar els seus paràmetres perquè imatges i descripcions comparables resultin en incrustacions similars.
La "difusió", un tipus de model generatiu que aprèn a fer imatges sorollant i eliminant gradualment les seves mostres d'entrenament, és l'altre enfocament d'aprenentatge automàtic que s'utilitza a DALL-E 2. Els models de difusió són similars als codificadors automàtics, ja que transformen les dades d'entrada en un incrustant la representació i després utilitzar la informació d'inserció per recrear les dades originals.
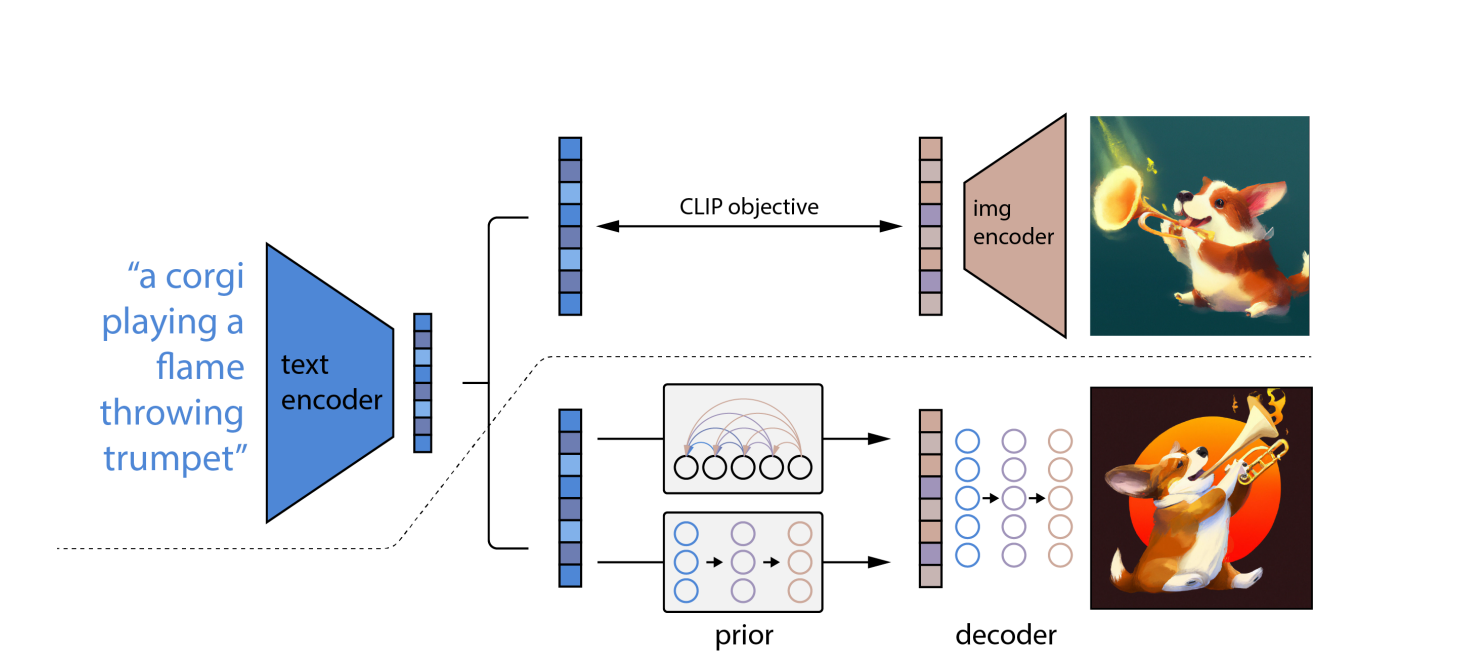
Utilitzant OpenAI model lingüístic CLIP, que pot connectar descripcions textuals amb fotografies, primer tradueix la indicació escrita a una forma intermèdia que incorpora les propietats crucials que hauria de tenir una imatge per coincidir amb aquesta indicació (segons CLIP).
En segon lloc, DALL-E 2 crea un CLIP compatible imatge utilitzant un model de difusió, que és una xarxa neuronal.
En fotografies distorsionades amb píxels aleatoris, s'aprenen models de difusió. Aprenen a restaurar la forma original de les fotos. Els models de difusió poden produir imatges sintètiques d'alta qualitat, especialment quan s'utilitzen juntament amb un enfocament guia que prioritza la precisió per sobre de la diversitat.
Com a conseqüència, el model de difusió agafa els píxels aleatoris i utilitza CLIP per convertir-los en una imatge nova que coincideixi amb la paraula indicació. A causa del concepte de difusió, DALL-E 2 pot produir imatges de major resolució més ràpidament que DALL-E.
Cas d'ús DALL.E 2
En els darrers vint anys, visió per computadora La tecnologia ha passat d'una noció simple a un gran avenç. Malgrat aquests avenços, els models de reconeixement d'imatges i objectes encara s'enfronten a obstacles importants a la vida quotidiana. L'absència de conjunts de dades és un dels inconvenients més significatius del reconeixement d'imatges i la visió per ordinador. Com que hi ha una escassetat de dades en ambdós extrems, és gairebé difícil entrenar models de reconeixement d'imatges per donar resultats 100% precisos.
Afortunadament, el nou model d'aprenentatge automàtic d'OpenAI pot salvar la bretxa en tecnologia. DALLE 2 és capaç de generar imatges sorprenents basades en descripcions de text. Aquesta producció d'imatges falses pot proporcionar dades als models de reconeixement d'imatges en funció dels seus requisits. L'absència de dades és un obstacle important per a la identificació d'objectes i imatges.
A l'era digital, els conjunts de dades són omnipresents, però encara estem buscant dreceres per alimentar el model d'IA, de manera que pugui oferir bons resultats. Tanmateix, no és senzill entrenar un model de reconeixement d'imatges. Necessita un gran nombre de conjunts de dades amb petites diferències, que potser no hauríem pogut recuperar simplement.
Aleshores, quina és la resposta: la resposta és DALLE 2. El generador d'imatges OpenAI, amb la seva capacitat per produir imatges a partir de textos i canviar-ne els existents, pot ajudar a salvar la bretxa. Això ajudarà a generar dades d'entrenament addicionals alhora que reduirà la quantitat d'etiquetatge humà requerit. Malgrat el benefici significatiu, hauríeu de tenir en compte les produccions d'imatges fraudulentes i les imatges que n'exclouen la inclusió. Això pot provocar que els mètodes de detecció d'imatges produeixin resultats esbiaixats.
Limitacions
DALL.E 2 pot tenir una influència nociva si cau en mans equivocades, segons OpenAI. En el món actual de falsificacions profundes, el model es podria utilitzar fàcilment per difondre informació falsa o imatges racistes, per això OpenAI només permet als desenvolupadors utilitzar DALL.2 per invitació. El model ha de complir amb una restricció de contingut rigorosa per a tots els suggeriments que rep.
Per excloure el potencial de DALL.E 2 de crear imatges hostils o violentes, el conjunt de dades es va crear sense cap arma mortal. Tot i que OpenAI ha afirmat que té previst transformar-lo en una API en el futur, en el cas de DALL.E 2, està disposat a procedir amb precaució.
Conclusió
DALL-E 2 és un altre descobriment interessant d'investigació d'OpenAI que obre la porta a noves aplicacions.
Un exemple és la creació de conjunts de dades massius per satisfer un dels principals colls d'ampolla de la visió per ordinador: les dades. Tot i que el cas econòmic de moltes aplicacions basades en DALL-E vindrà determinat pel preu i les polítiques que OpenAI estableixi per als seus usuaris d'API, sens dubte avançaran en la producció d'imatges.





Deixa un comentari