Web scraping je postao ključna metoda za dobijanje pronicljivih podataka sa internet platformi u današnjem društvu vođenom podacima.
Kao izuzetno popularna stranica na društvenim mrežama, Instagram pruža mnogo materijala koji generiraju korisnici. I ovi generirani podaci mogu se koristiti za marketing, istraživanje i druge razloge.
Korisnici mogu izvući podatke sa Instagrama s lakoćom i efikasnošću zahvaljujući Bright Data-ovim Instagram skraperima bogatim funkcijama, vodećim mrežno struganje alat. U ovom postu ćemo vam dati detaljan, korak po korak, korak po korak kroz proces scrapinga na Instagramu.
Dakle, hajde da vidimo korake kako možemo da saberemo podatke sa Instagrama.
Razumijevanje Instagram Scrapera iz Bright Data
Uz pomoć dva višenamjenska web scrapera i unaprijed kompajliranog skupa podataka, Bright Data pruža niz usluga za scraping na Instagramu. Ove tehnologije nude svestranost u ekstrakciji podataka i prilagođavaju se različitim zahtjevima.
Hajde da detaljnije ispitamo svaki od ovih izbora:
a. Scraping Browser
Inovativna tehnologija poznata kao Scraping Browser stvorena je da ispuni zahtjeve projekata za scraping podataka. Nudi sve što je potrebno za scraping u skali unutar jednog pretraživača. Ističe se zahvaljujući integrisanoj automatizaciji za deblokiranje web stranica, što ga čini jedinim pretraživačem te vrste na cijelom svijetu.
Scraping Browser korisnicima daje pristup robusnim funkcijama koje nadilaze automatske i bezglave pretraživače, omogućavajući im da prevaziđu čak i najteže skripte i barijere web stranice za otkrivanje botova.
Scraping podataka je efikasniji i bez muke zbog svojih automatiziranih funkcija prilagođavanja, koje lako upravljaju novim blokovima, CAPTCHA rješenjima, otiscima prstiju i ponovnim pokušajima, i pojavljuju se kao pravi korisnik.
Korištenje AI za nadmudrivanje sistema za detekciju botova
Koristeći najsavremeniju AI tehnologiju, Scraping Browser može nadmudriti sisteme za detekciju botova i stalno se prilagođavati njihovim strategijama promjene. Za bolje otključavanje web stranica, Scraping Browser uči iz pokušaja ovih sistema da otkrije i blokira pokušaje scrapinga i na odgovarajući način modificira svoje ponašanje.
On nadmašuje efikasnost konvencionalnih proksija imitirajući ponašanje pretraživača koji koristi pravi korisnik. Kao rezultat toga, korisnici se mogu koncentrirati na svoje ciljeve za scraping podataka bez potrebe da se bave poteškoćama i troškovima tekućih procedura otkrivanja botova.
b. Web Scraper IDE
Robustan alat za struganje weba kreiran za programere, Web Scraper IDE može se nositi sa složenim zadacima scrapinga. Značajno skraćuje vrijeme razvoja dok pruža beskonačnu skalabilnost zahvaljujući svom potpuno hostiranom rješenju i unaprijed ugrađenim funkcijama scrapinga. Aplikacija omogućava brzu i skalabilnu izgradnju online strugača pružanjem predložaka koda i gotovih JavaScript funkcija sa popularnih web stranica.
Sve što je potrebno za uspješno web scraping pruža Web Scraper IDE. To je kompletno rješenje za ekstrakciju podataka na mreži jer opcije integracije omogućavaju korisnicima da planiraju indeksiranje ili ih pokreću preko API-ja i povezuju se s glavnim sustavima za pohranu.
Kako ga koristiti? – Tutorial
Prvo idite na korisničku kontrolnu tablu na web stranici.

Počnimo s našim koracima za grebanje Instagrama.
1- Idite na Komandna tabla i kliknite na odeljak Skupovi podataka i Web Scraper IDE.
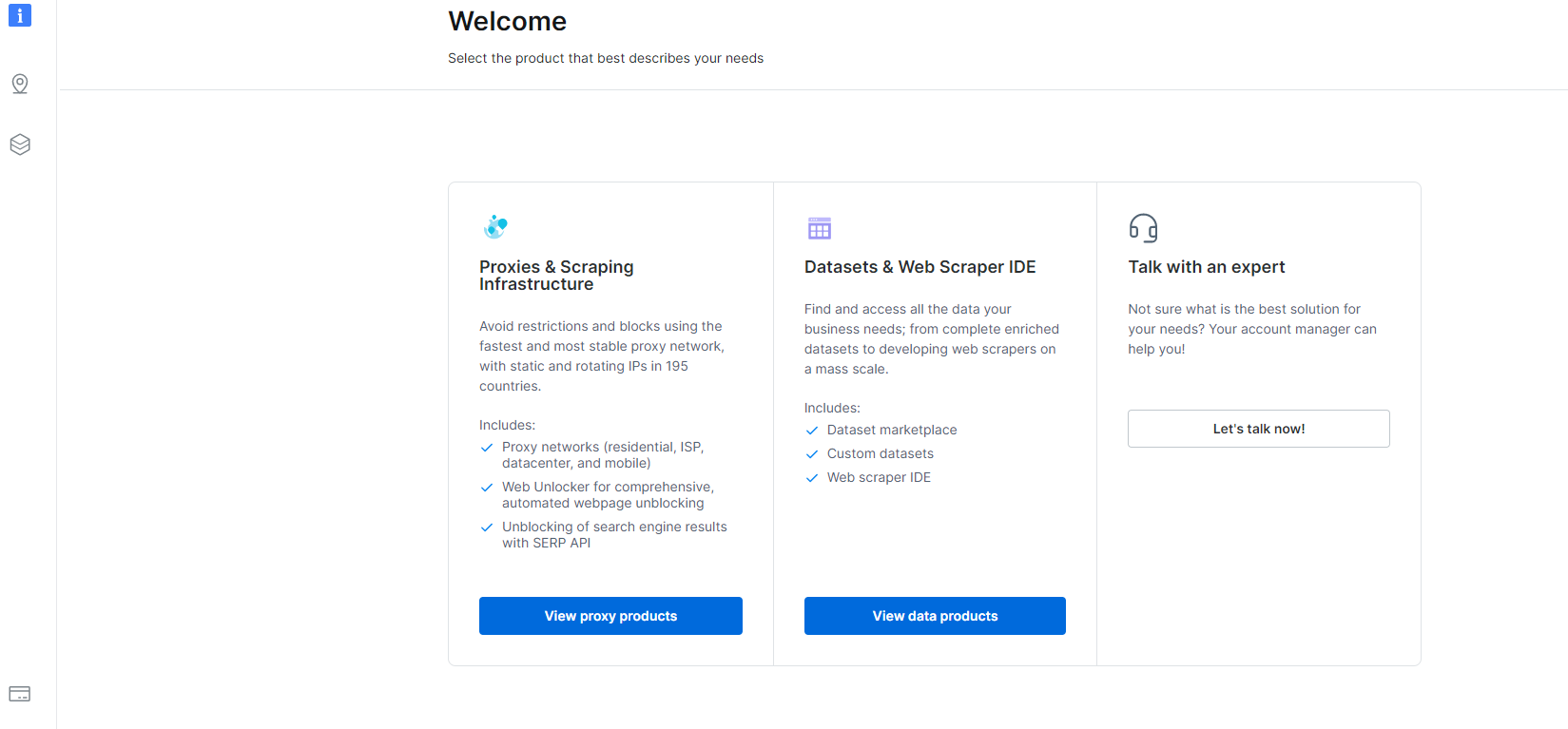
2- Kada ste tamo, kliknite na My Scrapers.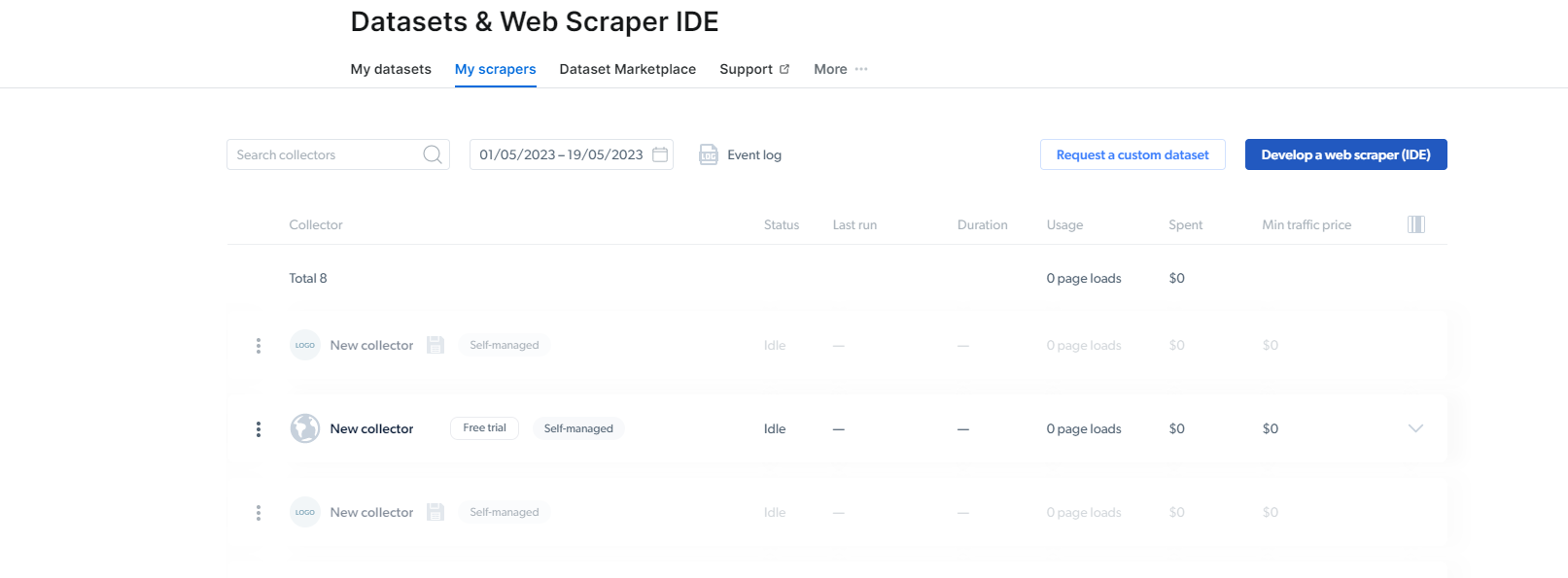
Ovdje trebate kliknuti na “Razvoj web scraper(IDE)”. Ovdje ćemo kreirati naš strugač za Instagram.
3-Sada, trebamo razviti novi web scraper. Samo za ovaj primjer, odlučio sam da skradam “NASA” račun. Ovo je samo radi ovog primjera.
Dakle, moj kod će izgledati ovako:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Morate da kliknete na dugme 'play' u gornjem desnom uglu da biste pokrenuli ovaj kod.
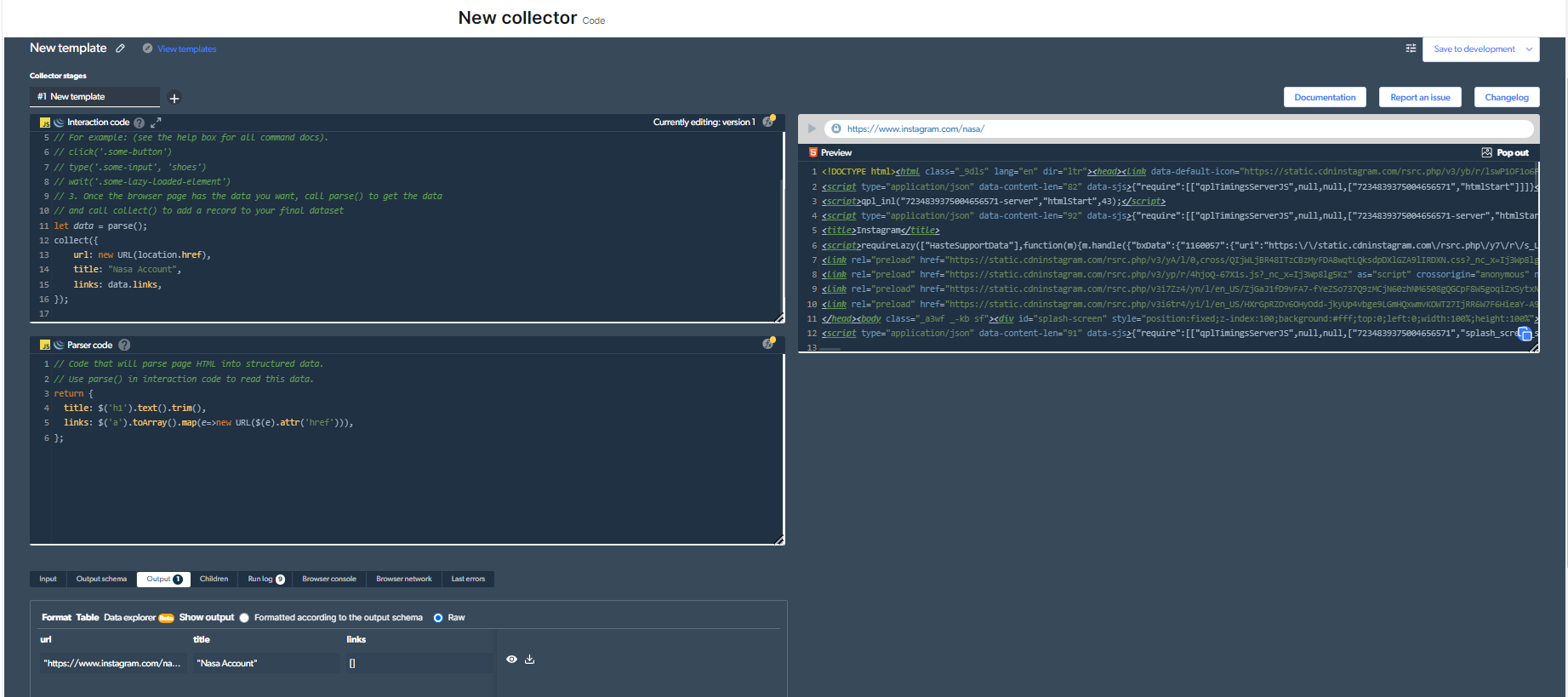
4- Sada ćemo imati izlaz.
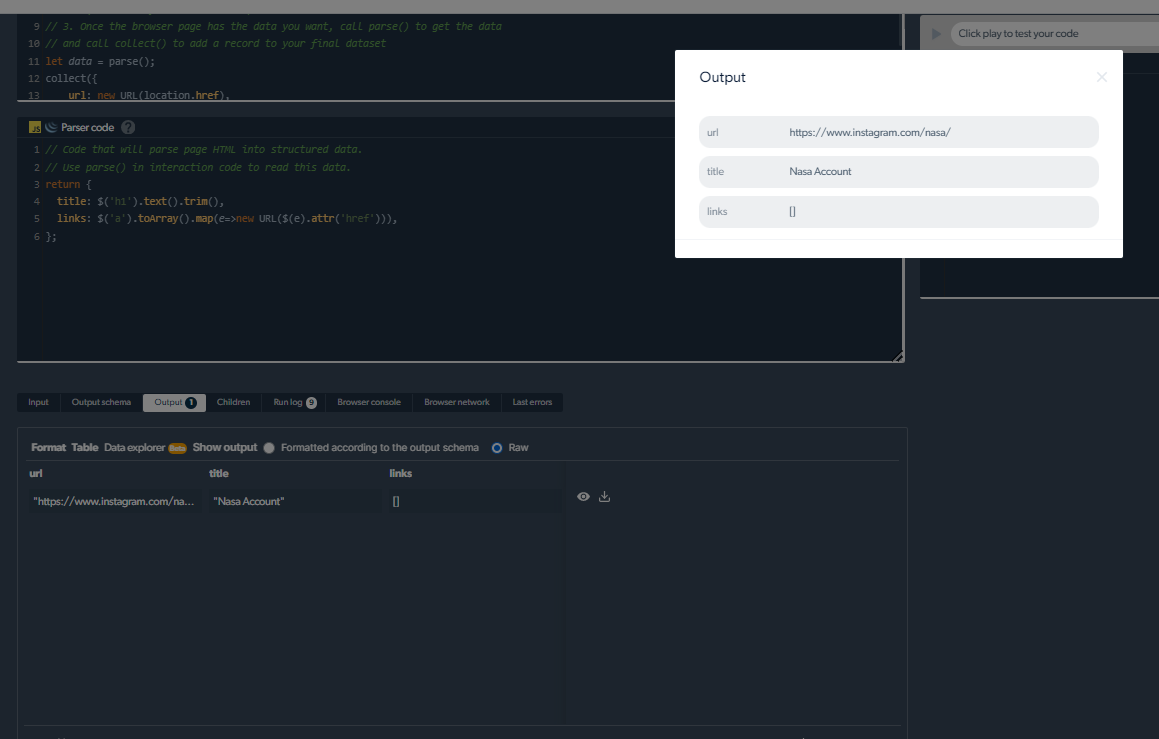
Upravljanje problemima sa struganjem
Objave na Instagramu s “dugme za prikaži više” možda će biti teško snimiti strugači. Međutim, Instagram strugači iz Bright Data napravljeni su da uspješno nose takvu složenost. Ovi strugači imaju vrhunske vještine za kretanje kroz paginaciju i učitavanje dodatnih dugmadi.
Instagram strugači kompanije Bright Data efikasno rješavaju ove poteškoće kako bi omogućili temeljno izdvajanje podataka, omogućavajući vam da prikupite cijelu kolekciju informacija potrebnih za vašu analizu ili proučavanje.
Možete zaobići izazove koje predstavlja dinamična priroda Instagram postova korištenjem ovih alata za scraping.
c. Unaprijed prikupljeni skup podataka
Bright Data shvaća da ne žele svi pokrenuti svoj scraper. Oni isporučuju unaprijed prikupljene podatke za Instagram kako bi se svidjeli takvim potrošačima.
Ovaj skup podataka nudi mnoštvo korisnih informacija, kao što su pratioci, profili, objave i još mnogo toga.
Bright Data nudi opcije prilagođavanja za personalizaciju skupa podataka vašim potrebama, bilo da želite cijeli skup podataka ili podskup specijaliziranih podataka. Ovaj pristup izbjegava izgradnju i upravljanje strugačem, dajući vam podatke spremne za korištenje za analizu i uvid.
Sada, hajde da proverimo infrastrukturu koja ove alate čini tako efikasnim: proxy infrastrukturu i Web Unlocker.
Oslobodite moć proksija
korišćenje proksi je ključno tokom web scrapinga kako bi se jamčilo da će vaše radnje ostati neprimijećene.
Bright Data nudi širok izbor proxy usluge koji su prilagođeni vašim zahtjevima. Možete birati između Stambeni punomoćnici, koji nudi više od 72 miliona IP adresa rotiranih sa pravih ravnopravnih uređaja u 195 zemalja.
Možete odabrati ISP proksije, koji nude 700,000+ pravih kućnih IP-ova širom svijeta za dugoročnu upotrebu; Datacenter Proxies, koji imaju 770,000+ zajedničkih IP-ova sa bilo koje geolokacije; i Mobile Proxies, koji čine najveću realnu 3G/4G mobilnu mrežu sa više od 7,000,000 IP adresa.
Uz korištenje ovih proksija, lako se prikupljaju podaci dok se predstavljate kao ovlašteni korisnik na brojnim mjestima.

Proxy Manager: Olakšajte upravljanje proxyjem
Upravljanje nekoliko proksija može biti teško, ali Proxy Manager to olakšava.
Ovo sučelje otvorenog koda vam omogućava da upravljate svim vašim proksijima s jedne platforme. Recite zbogom ručnom postavljanju i prebacivanju proksija. Proxy Manager pojednostavljuje proceduru i štedi vam vrijeme i trud.
Proksi proširenje pretraživača: Lako promijenite lokaciju
Trebate li prikupljati web podatke iz nekoliko regija? Pokriveni ste našim Proxy Browser Extension. Možete promijeniti svoju lokaciju pregledavanja jednim klikom da biste dobili informacije specifične za regiju.
Iskoristite fleksibilnost i jednostavnost prikupljanja podataka iz nekoliko regija bez ikakvih tehnoloških komplikacija.
Kako to radi? – Tutorial
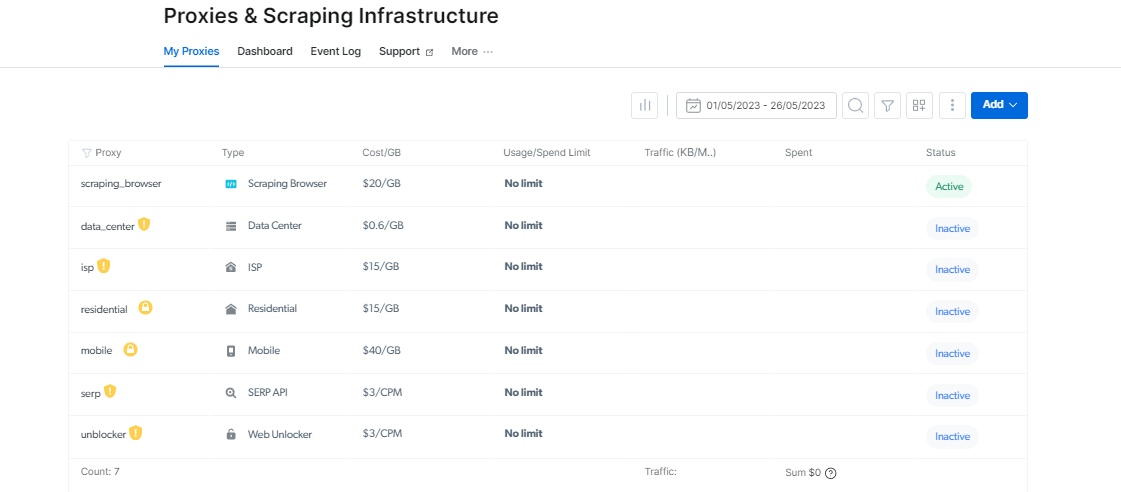
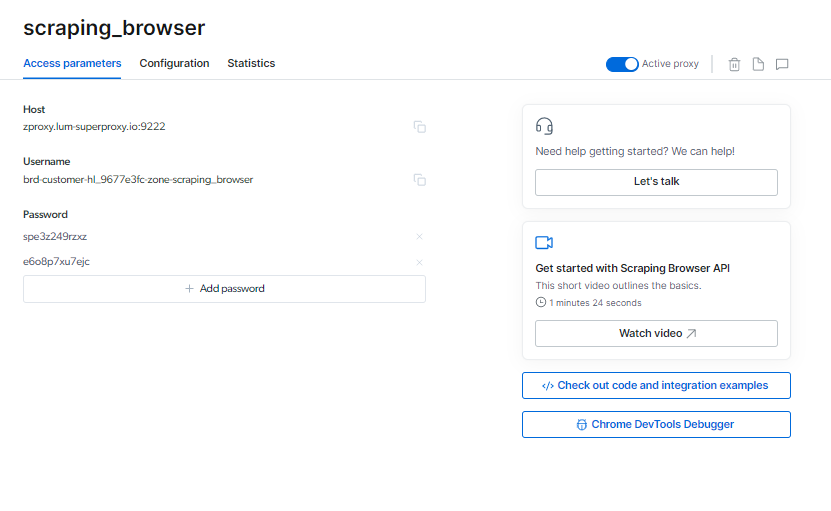
Možete locirati svoje Scraping Browser informacije za prijavu na stranici Pristupni parametri, koje će se koristiti kada pokrenete novu sesiju pretraživača.
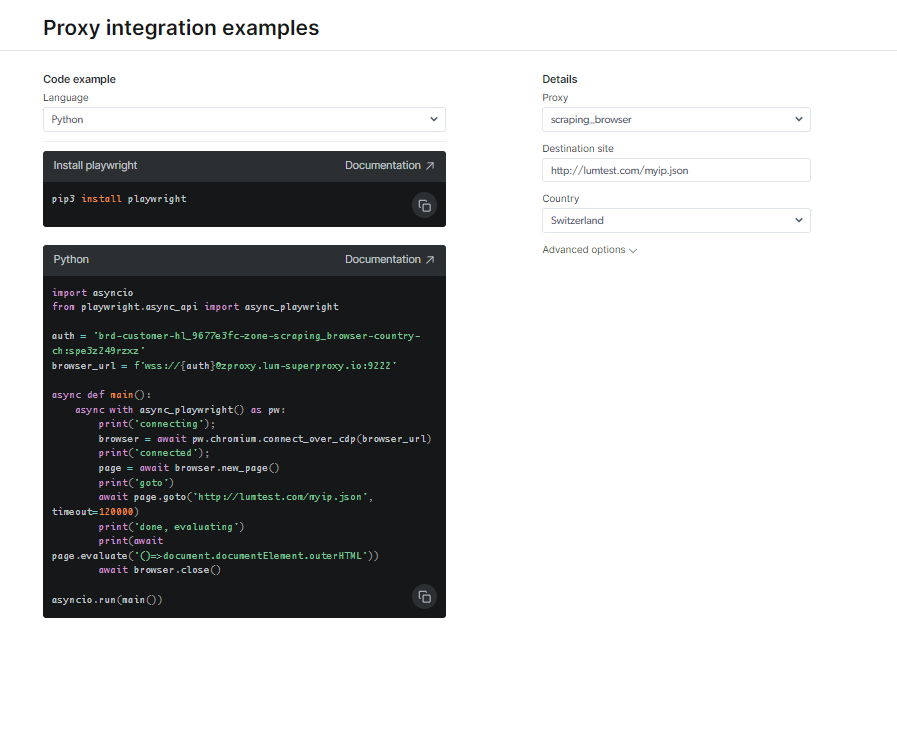
Pogledajte dokumentaciju i uzorke koda, uključujući potpuno funkcionalan primjer skripte koji je spreman za korištenje, ili pogledajte kratki video s uputama za početak. Na primjer; ovdje je a Python kod primjer za integraciju:
Želite pomoć? Za razgovor sa jednim od stručnjaka, možete kliknuti na ikonu za ćaskanje.
Imajte na umu da imate potpunu kontrolu nad sesijama preglednika dok koristite Scraping Browser i možete izvršiti bilo koju operaciju koju podržava Puppeteer, Playwright ili direktna upotreba Chrome DevTools protokola.
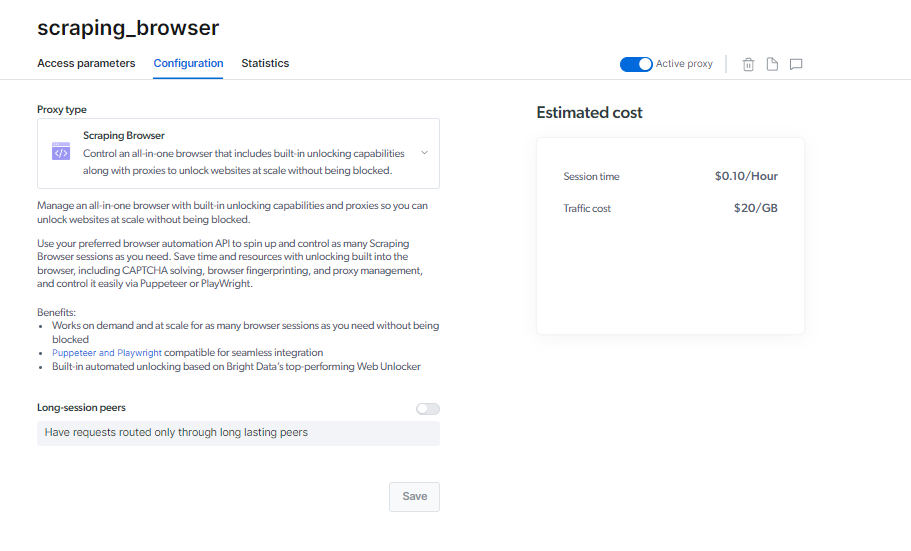
Otključavanje web stranice bez blokada
Scraping Browser je napravljen da radi u obimu i po potrebi. Ne morate da brinete o tome da ćete biti zabranjeni; možete pokrenuti onoliko sesija pretraživača koliko vam je potrebno.
Ovaj kapacitet, kada je uparen sa snagom proksija, garantuje kontinuirano prikupljanje podataka, omogućavajući vam da efikasno dobijete podatke koje želite.
Scraping Browser ugrađene vještine otključavanja i robusna proxy mreža pomažu vam da uštedite vrijeme, poboljšate produktivnost i otkrijete nove mogućnosti.
Statistiku možete provjeriti i sa iste stranice direktno.
Cijene Scraping Browser-a
Bright Data pruža prilagodljive izbore cijena kako bi se zadovoljile različite svrhe. Možete odabrati mjesečni ili godišnji obračunski period.
Opcija Pay as You Go omogućava vam da platite samo za ono što koristite, bez obaveznih obaveza, počevši od 20.00 USD/GB i 0.1 USD/sat.
Plan rasta od 500 USD je pogodan za rastuće kompanije, uz sniženu naknadu od 15.30 USD/GB i 0.1 USD/sat.
The poslovni paket, koji košta 1000 USD, najpopularnija je opcija, sa API pretraživača za Scraping koji košta 13.50 USD/GB i 0.1 USD/sat.
Direktnim kontaktiranjem Bright Data tima, poslovni korisnici mogu uživati u beskonačnom skaliranju i personaliziranim cijenama. Započnite besplatnu probnu verziju već danas da otkrijete potencijal Bright Data's Scraping Browser-a i promijenite svoje napore za scraping na mreži.
Website Unlocker
Web Unlocker je moćan alat kreiran da prevaziđe ograničenja web stranice i omogući jednostavno prikupljanje podataka. Prevladava nekoliko izazova, uključujući kolačiće, korisničke agente pretraživača specifične za web stranicu i captcha rješenja, korištenjem automatiziranih procedura.
Koristeći automatsku rotaciju IP adrese, korisnici Web Unlocker-a mogu kontinuirano grebati ciljane web stranice, osiguravajući stalan pristup važnim podacima.
Poboljšanje putovanja zahtjeva programera
Nekoliko funkcija čini Web Unlocker popularnim među programerima. Program pojednostavljuje proces prikupljanja podataka automatski identificirajući korisničke agente potrebne za svaku web stranicu, štedeći dragocjeno vrijeme i resurse.
Web Unlocker se prilagođava u realnom vremenu kako bi izbjegao otkrivanje kao odgovor na stalno mijenjajuće strategije koje koriste blokirajući botovi, osiguravajući kontinuirani pristup web stranicama od interesa. Algoritmi za mašinsko učenje platforme mogu brzo riješiti captchas, čestu prepreku inicijativama za prikupljanje podataka.

Cijene Web Unlockera
Počevši od oko 2.03 USD za hiljadu zahtjeva (CPM), Web Unlocker nudi više opcija cijena kako bi zadovoljio različite zahtjeve. Korisnicima je dostupna 7-dnevna besplatna probna verzija kako bi započeli i omogućili im da testiraju značajke Web Unlockera prije nego što se obavežu.
Web Unlocker ima prilagodljivost da podrži različite obrasce upotrebe, bez obzira da li potrošači žele pristup koji se plaća po vremenu ili im je potreban prilagođeni plan koji odgovara njihovim posebnim zahtjevima. Osim toga, oni koji biraju dugoročne planove cijena mogli bi uštedjeti 32%.
Poređenje između Web Unlocker-a sa samoupravljanim proksijima
Web Unlocker nudi brojne trenutne prednosti u odnosu na proxy servere koji sami upravljaju. Za glatku implementaciju, nudi opsežnu tehniku integracije koja kombinuje funkcije super proxy i Proxy Manager. Korisnici mogu efikasno povećati svoje operacije prikupljanja podataka sa beskonačnim brojem istovremenih veza.
Web Unlocker pruža automatsko deblokiranje, rješava CAPTCHA i uspješno upravlja modifikacijama oznaka na ciljanim web lokacijama.
Platforma garantuje kontinuirano i pouzdano izvlačenje podataka implementacijom sistema automatskog ponovnog pokušaja i asinhronim pozivima za određene domene. Uz to, rastuća kolekcija zahtjeva za HTTP zaglavlja HTTP-a Unlocker-a, kolačića pretraživača specifičnih za web stranicu i simuliranih gadžeta omogućava korisnicima da ostanu neotkriveni, a istovremeno im omogućava da pribavljaju online podatke u realnom vremenu.
Završne misli i važne stvari koje treba zapamtiti
Konačno, dok koristite Bright Data za Instagram scraping, ključno je imati na umu nekoliko vitalnih tačaka.
Imajte na umu da su njihove mogućnosti grebanja ograničene na javno dostupne podatke, etičkim praksama.
Uvijek biste trebali slijediti Instagramove uslove usluge i politiku privatnosti. Scraping treba raditi etički i odgovorno, bez zadiranja u prava korisnika ili kršenja bilo kakvih zakona.
Drugo, redovno ažurirajte i fino podešavajte svoje parametre scrapinga kako biste osigurali točnost i relevantnost preuzetih podataka. Instagramova platforma i algoritmi su podložni promjenama, stoga morate u skladu s tim promijeniti svoje strategije scrapinga.
Konačno, koristite pomoć i resurse platforme Bright Data kako biste optimizirali uspjeh svojih napora za scraping na Instagramu. Angažirajte se s njihovom dokumentacijom, tutorijalima i korisničkim servisom kako biste poboljšali svoje znanje o njihovim alatima za struganje.
Možete steći korisne uvide, utjecati na mudro donošenje odluka i uspjeti u svojim inicijativama vođenim podacima na Instagram platformi slijedeći ove najbolje prakse i koristeći snagu Bright Data mogućnosti za scraping na Instagramu.





Ostavite odgovor