AI je svuda, ali ponekad može biti izazovno razumjeti terminologiju i žargon. U ovom postu na blogu objašnjavamo preko 50 pojmova i definicija AI kako biste bolje razumjeli ovu tehnologiju koja se brzo razvija.
Bilo da ste početnik ili stručnjak, kladimo se da ovdje postoji nekoliko pojmova koje ne znate!
1. Artificial Intelligence
Umjetna inteligencija (AI) se odnosi na razvoj kompjuterskih sistema koji imaju sposobnost da uče i funkcionišu nezavisno, često oponašajući ljudsku inteligenciju.
Ovi sistemi analiziraju podatke, prepoznaju obrasce, donose odluke i prilagođavaju svoje ponašanje na osnovu iskustva. Koristeći algoritme i modele, AI ima za cilj da stvori inteligentne mašine sposobne da percipiraju i razumeju svoju okolinu.
Krajnji cilj je omogućiti mašinama da efikasno obavljaju zadatke, uče iz podataka i pokažu kognitivne sposobnosti slične ljudima.
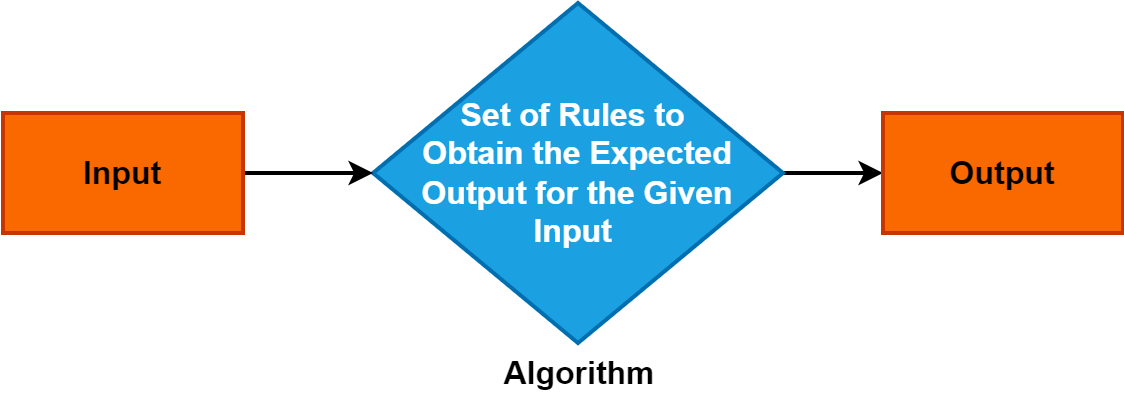
2. algoritam
Algoritam je precizan i sistematičan skup instrukcija ili pravila koja usmjeravaju proces rješavanja problema ili izvršavanja određenog zadatka.
Služi kao temeljni koncept u različitim domenima i igra ključnu ulogu u informatici, matematici i disciplinama za rješavanje problema. Razumijevanje algoritama je ključno jer omogućavaju efikasne i strukturirane pristupe rješavanju problema, pokrećući napredak u tehnologiji i procesima donošenja odluka.
3. Veliki podaci
Veliki podaci se odnose na izuzetno velike i složene skupove podataka koji prevazilaze mogućnosti tradicionalnih metoda analize. Ove skupove podataka obično karakterizira njihov volumen, brzina i raznolikost.
Volumen se odnosi na ogromnu količinu podataka generiranih iz različitih izvora kao npr društvenih medija, senzori i transakcije.
Brzina se odnosi na veliku brzinu kojom se podaci generišu i treba ih obraditi u realnom vremenu ili skoro u realnom vremenu. Raznolikost označava različite tipove i formate podataka, uključujući strukturirane, nestrukturirane i polustrukturirane podatke.
4. Data mining
Data mining je sveobuhvatan proces koji ima za cilj izvlačenje vrijednih uvida iz ogromnih skupova podataka.
Obuhvata četiri ključne faze: prikupljanje podataka, uključujući prikupljanje relevantnih podataka; priprema podataka, osiguranje kvaliteta i kompatibilnosti podataka; rudarenje podataka, korištenje algoritama za otkrivanje obrazaca i odnosa; i analizu i interpretaciju podataka, gdje se izvučeno znanje ispituje i razumije.
5. Neuralna mreža
Kompjuterski sistem je dizajniran da radi kao ljudski mozak, sastavljen od međusobno povezanih čvorova ili neurona. Hajde da shvatimo ovo malo više jer je većina AI zasnovana na neuronske mreže.
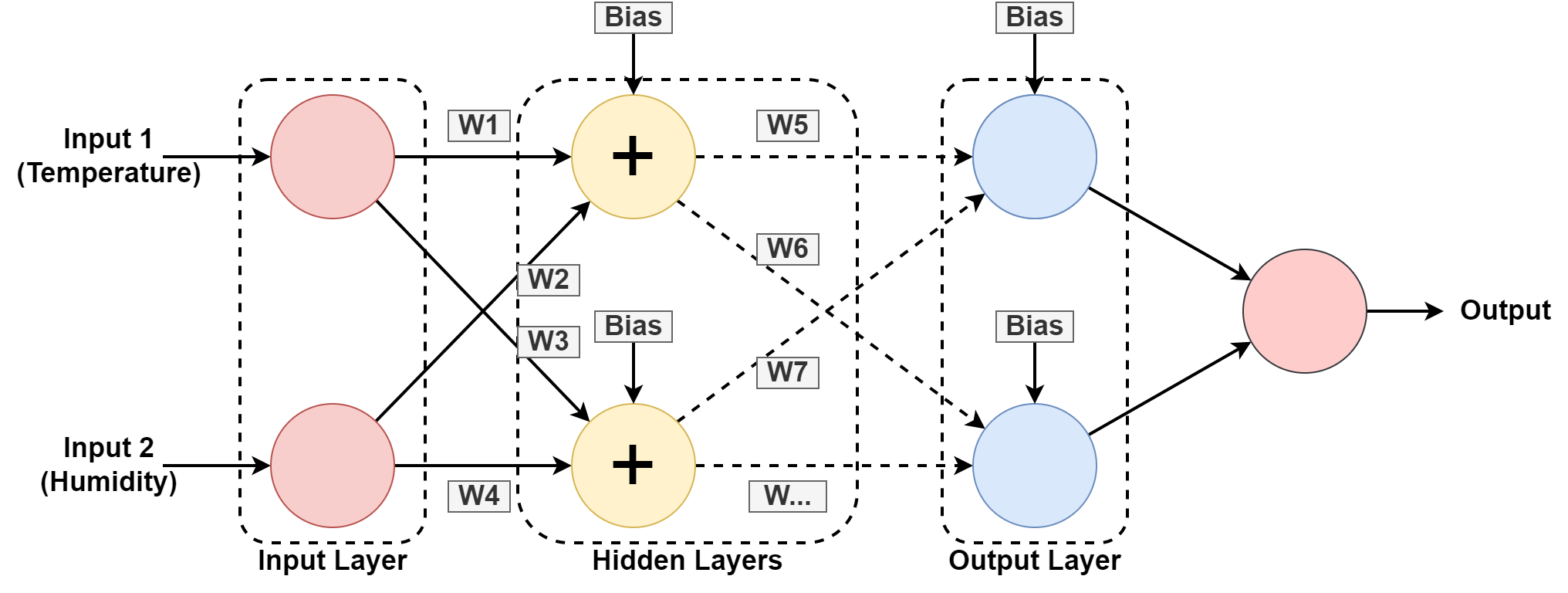
U gornjoj grafiki predviđamo vlažnost i temperaturu geografske lokacije učeći iz prošlog uzorka. Ulazi su skup podataka za prošli zapis.
The neuronska mreža uči uzorak igrajući se sa težinama i primjenom vrijednosti pristranosti u skrivenim slojevima. W1, W2….W7 su odgovarajuće težine. Trenira se na priloženom skupu podataka i daje izlaz kao predviđanje.
Možda ćete biti preplavljeni ovim složenim informacijama. Ako je to slučaj, možete početi s našim jednostavnim vodičem OVDJE.
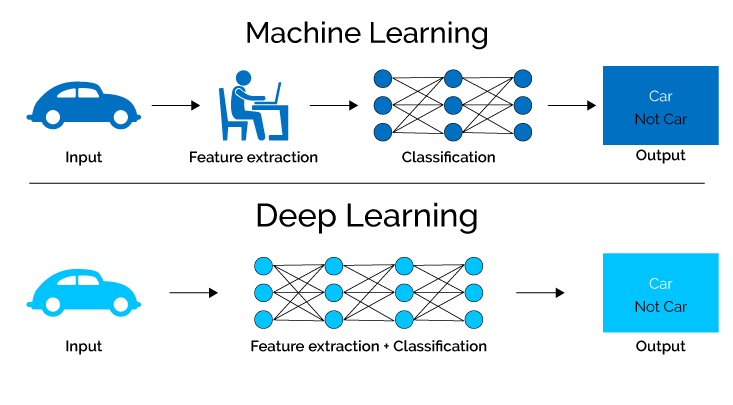
6. Mašinsko učenje
Mašinsko učenje se fokusira na razvoj algoritama i modela sposobnih za automatsko učenje iz podataka i poboljšanje njihovih performansi tokom vremena.
To uključuje upotrebu statističkih tehnika koje omogućavaju kompjuterima da identifikuju obrasce, da predviđaju i donose odluke zasnovane na podacima bez eksplicitnog programiranja.
Algoritmi mašinskog učenja analiziraju i uče iz velikih skupova podataka, omogućavajući sistemima da se prilagode i poboljšaju svoje ponašanje na osnovu informacija koje obrađuju.
7. Duboko učenje
Duboko učenje, podpolje mašinskog učenja i neuronskih mreža, koristi sofisticirane algoritme za sticanje znanja iz podataka simulacijom zamršenih procesa u ljudskom mozgu.
Koristeći neuronske mreže sa brojnim skrivenim slojevima, modeli dubokog učenja mogu autonomno izdvojiti zamršene karakteristike i obrasce, omogućavajući im da se bave složenim zadacima sa izuzetnom preciznošću i efikasnošću.
8. Prepoznavanje uzoraka
Prepoznavanje uzoraka, tehnika analize podataka, koristi moć algoritama mašinskog učenja za autonomno otkrivanje i uočavanje obrazaca i pravilnosti unutar skupova podataka.
Koristeći računarske modele i statističke metode, algoritmi za prepoznavanje obrazaca mogu identificirati značajne strukture, korelacije i trendove u složenim i raznolikim podacima.
Ovaj proces omogućava izvlačenje vrijednih uvida, klasifikaciju podataka u različite kategorije i predviđanje budućih ishoda na osnovu prepoznatih obrazaca. Prepoznavanje uzoraka je vitalno sredstvo u različitim domenima, osnažujući donošenje odluka, otkrivanje anomalija i prediktivno modeliranje.
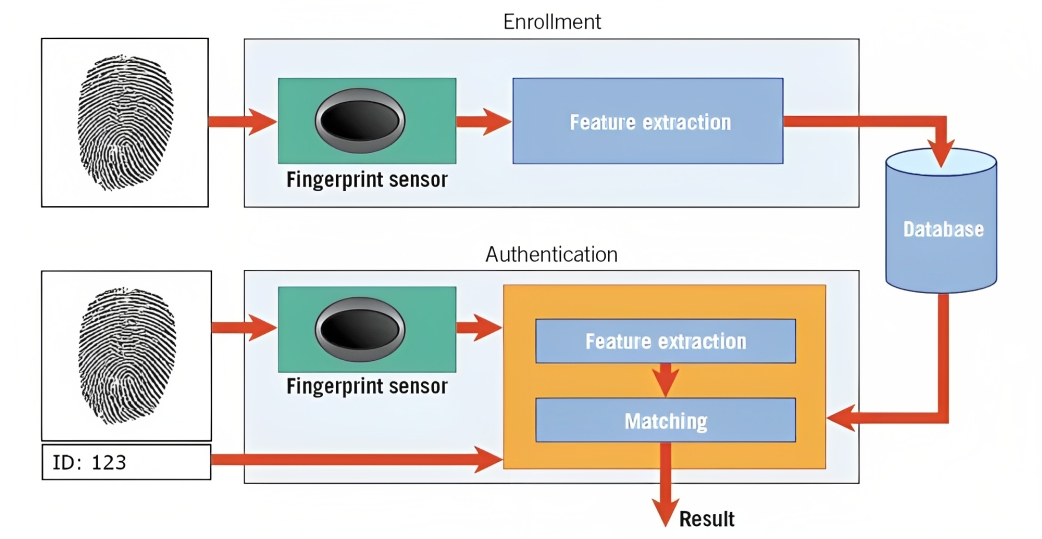
Biometrija je jedan primjer ovoga. Na primjer, u prepoznavanju otiska prsta, algoritam analizira izbočine, krivine i jedinstvene karakteristike otiska prsta osobe kako bi stvorio digitalni prikaz koji se zove šablon.
Kada pokušate da otključate svoj pametni telefon ili pristupite bezbednom objektu, sistem za prepoznavanje uzoraka uspoređuje snimljene biometrijske podatke (npr. otisak prsta) sa pohranjenim šablonima u svojoj bazi podataka.
Upoređujući obrasce i procjenjujući nivo sličnosti, sistem može utvrditi da li se dati biometrijski podaci podudaraju sa pohranjenim šablonom i u skladu s tim odobriti pristup.
9. Učenje pod nadzorom
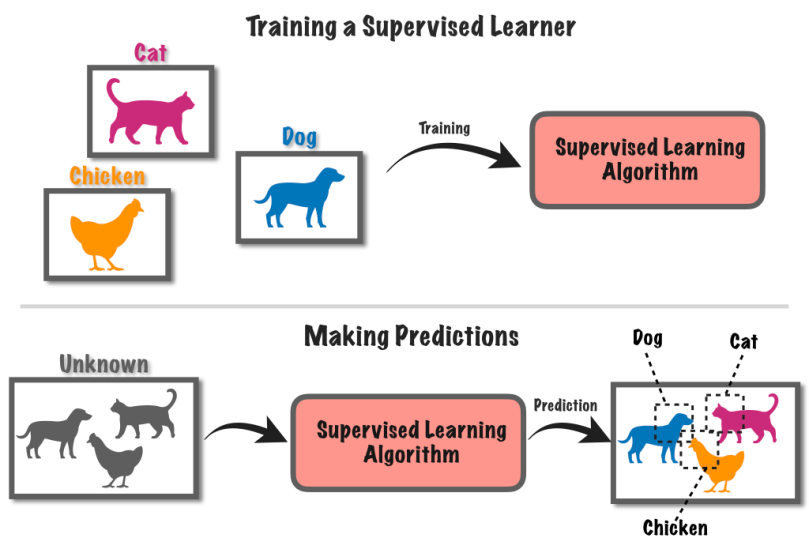
Nadzirano učenje je pristup mašinskog učenja koji uključuje obuku računarskog sistema koristeći označene podatke. U ovoj metodi, računar dobija skup ulaznih podataka zajedno sa odgovarajućim poznatim oznakama ili ishodima.
Recimo da imate gomilu slika, neke sa psima, a neke sa mačkama.
Vi kažete kompjuteru na kojim slikama se nalaze psi, a na kojima mačke. Računar tada uči da prepozna razlike između pasa i mačaka pronalazeći obrasce na slikama.
Nakon što nauči, možete dati kompjuteru nove slike, a ono će pokušati otkriti imaju li pse ili mačke na osnovu onoga što je naučio iz označenih primjera. To je kao da trenirate kompjuter da predviđa predviđanja koristeći poznate informacije.
10. Učenje bez nadzora
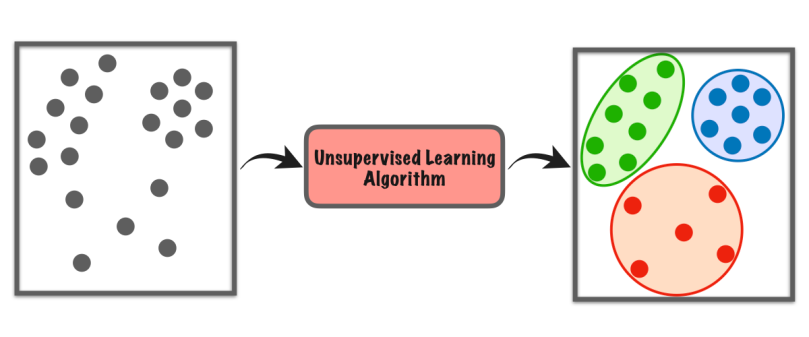
Učenje bez nadzora je vrsta mašinskog učenja u kojoj računar samostalno istražuje skup podataka kako bi pronašao obrasce ili sličnosti bez ikakvih posebnih uputstava.
Ne oslanja se na označene primjere kao kod učenja pod nadzorom. Umjesto toga, traži skrivene strukture ili grupe u podacima. To je kao da kompjuter otkriva stvari sam, a da mu učitelj ne govori šta da traži.
Ova vrsta učenja pomaže nam da pronađemo nove uvide, organiziramo podatke ili identificiramo neobične stvari bez prethodnog znanja ili eksplicitnih smjernica.
11. Obrada prirodnog jezika (NLP)
Obrada prirodnog jezika fokusira se na to kako kompjuteri razumiju i komuniciraju s ljudskim jezikom. Pomaže kompjuterima da analiziraju, tumače i reaguju na ljudski jezik na način koji nam se čini prirodnijim.
NLP je ono što nam omogućava da komuniciramo sa glasovnim asistentima i chatbotovima, pa čak i da naše e-poruke automatski sortiraju u foldere.
To uključuje podučavanje kompjutera da razumiju značenje riječi, rečenica, pa čak i cijelih tekstova, tako da nam mogu pomoći u različitim zadacima i učiniti našu interakciju s tehnologijom lakšom.
12. Kompjuterski vid
Computer vision je fascinantna tehnologija koja omogućava kompjuterima da vide i razumiju slike i video zapise, baš kao što mi ljudi radimo očima. Sve je u učenju kompjutera da analiziraju vizuelne informacije i da daju smisao onome što vide.
Jednostavnije rečeno, kompjuterski vid pomaže kompjuterima da prepoznaju i interpretiraju vizuelni svet. To uključuje zadatke poput podučavanja da prepoznaju određene objekte na slikama, klasificiraju slike u različite kategorije ili čak podijele slike na smislene dijelove.
Zamislite samovozeći automobil koji koristi kompjuterski vid da „vidi“ cestu i sve oko njega.
Može otkriti i pratiti pješake, saobraćajne znakove i druga vozila, pomažući im da se bezbedno kreću. Ili razmislite o tome kako tehnologija prepoznavanja lica koristi kompjuterski vid da otključa naše pametne telefone ili potvrdi naše identitete prepoznavanjem naših jedinstvenih crta lica.
Takođe se koristi u sistemima za nadzor za praćenje gužvi i uočavanje bilo kakvih sumnjivih aktivnosti.
Kompjuterski vid je moćna tehnologija koja otvara svijet mogućnosti. Omogućavajući kompjuterima da vide i razumiju vizuelne informacije, možemo razviti aplikacije i sisteme koji mogu percipirati i interpretirati svijet oko nas, čineći naš život lakšim, sigurnijim i efikasnijim.
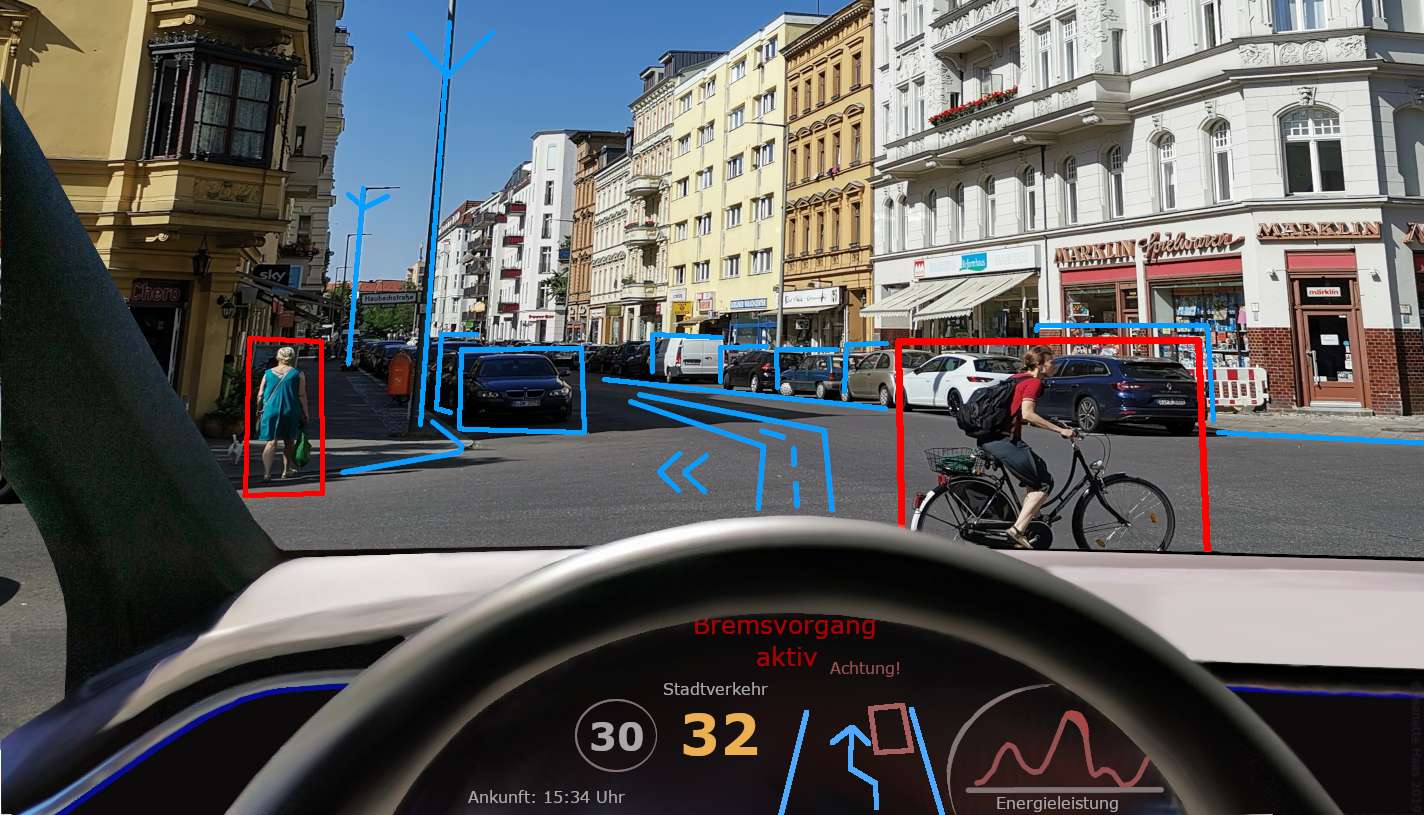
13.Chatbot
Chatbot je poput kompjuterskog programa koji može razgovarati s ljudima na način koji izgleda kao pravi ljudski razgovor.
Često se koristi u online korisničkoj službi da pomogne klijentima i da se osjećaju kao da razgovaraju s osobom, iako je to zapravo program koji radi na računaru.
Chatbot može razumjeti i odgovarati na poruke ili pitanja kupaca, pružajući korisne informacije i pomoć baš kao što bi to činio predstavnik korisničke službe.
14. Prepoznavanje glasa
Prepoznavanje glasa se odnosi na sposobnost kompjuterskog sistema da razumije i interpretira ljudski govor. To uključuje tehnologiju koja omogućava kompjuteru ili uređaju da „sluša“ izgovorene reči i pretvara ih u tekst ili komande koje može da razume.
sa prepoznavanje glasa, možete komunicirati s uređajima ili aplikacijama tako što ćete jednostavno razgovarati s njima umjesto da kucate ili koristite druge metode unosa.
Sistem analizira izgovorene riječi, prepoznaje obrasce i zvukove, a zatim ih prevodi u razumljiv tekst ili radnje. Omogućava prirodnu komunikaciju s tehnologijom bez upotrebe ruku, čineći zadatke kao što su glasovne komande, diktiranje ili interakcije kontrolirane glasom. Najčešći primjeri su AI asistenti kao što su Siri i Google Assistant.
15. Analiza osjećaja
Analiza raspoloženja je tehnika koja se koristi za razumijevanje i tumačenje emocija, mišljenja i stavova izraženih u tekstu ili govoru. To uključuje analizu pisanog ili govornog jezika kako bi se utvrdilo da li je izraženo osjećanje pozitivno, negativno ili neutralno.
Koristeći algoritme za strojno učenje, algoritmi za analizu osjećaja mogu skenirati i analizirati velike količine tekstualnih podataka, kao što su recenzije kupaca, objave na društvenim mrežama ili povratne informacije kupaca, kako bi identificirali temeljni osjećaj iza riječi.
Algoritmi traže određene riječi, fraze ili obrasce koji ukazuju na emocije ili mišljenja.
Ova analiza pomaže preduzećima ili pojedincima da shvate kako ljudi misle o proizvodu, usluzi ili temi i može se koristiti za donošenje odluka na osnovu podataka ili za sticanje uvida u preferencije kupaca.
Na primjer, kompanija može koristiti analizu osjećaja za praćenje zadovoljstva kupaca, identificiranje područja za poboljšanje ili praćenje javnog mnijenja o svom brendu.
16. Mašinsko prevođenje
Mašinsko prevođenje, u kontekstu AI, odnosi se na korištenje kompjuterskih algoritama i umjetne inteligencije za automatsko prevođenje teksta ili govora s jednog jezika na drugi.
To uključuje podučavanje kompjutera da razumiju i obrađuju ljudske jezike kako bi se obezbijedili tačni prijevodi. Najčešći primjer je Google prevodilac.
Sa mašinskim prevođenjem možete uneti tekst ili govor na jednom jeziku, a sistem će analizirati unos i generisati odgovarajući prevod na drugom jeziku. Ovo je posebno korisno kada komunicirate ili pristupate informacijama na različitim jezicima.
Sistemi mašinskog prevođenja oslanjaju se na kombinaciju lingvističkih pravila, statističkih modela i algoritama mašinskog učenja. Oni uče iz ogromne količine podataka o jeziku kako bi vremenom poboljšali tačnost prijevoda. Neki pristupi mašinskog prevođenja takođe uključuju neuronske mreže za poboljšanje kvaliteta prevoda.
17. Robotika
Robotika je kombinacija umjetne inteligencije i strojarstva za stvaranje inteligentnih strojeva zvanih roboti. Ovi roboti su dizajnirani da obavljaju zadatke autonomno ili uz minimalnu ljudsku intervenciju.
Roboti su fizički entiteti koji mogu osjetiti svoje okruženje, donositi odluke na osnovu tog senzornog unosa i obavljati određene radnje ili zadatke.
Opremljeni su raznim senzorima, kao što su kamere, mikrofoni ili senzori za dodir, koji im omogućavaju prikupljanje informacija iz svijeta oko sebe. Uz pomoć AI algoritama i programiranja, roboti mogu analizirati ove podatke, interpretirati ih i donositi inteligentne odluke kako bi izvršili svoje određene zadatke.
AI igra ključnu ulogu u robotici omogućavajući robotima da uče iz svojih iskustava i prilagode se različitim situacijama.
Algoritmi za strojno učenje mogu se koristiti za obuku robota da prepoznaju objekte, navigaciju okolinom ili čak interakciju s ljudima. To omogućava robotima da postanu svestraniji, fleksibilniji i sposobniji za rukovanje složenim zadacima.
18 Drones
Dronovi su vrsta robota koji mogu letjeti ili lebdjeti u zraku bez ljudskog pilota. Poznate su i kao bespilotne letjelice (UAV). Dronovi su opremljeni raznim senzorima, kao što su kamere, GPS i žiroskopi, koji im omogućavaju prikupljanje podataka i navigaciju okolinom.
Njima daljinski upravlja ljudski operater ili mogu raditi autonomno koristeći unaprijed programirana uputstva.
Bespilotne letjelice služe za širok spektar namjena, uključujući zračnu fotografiju i video snimanje, snimanje i mapiranje, usluge dostave, misije potrage i spašavanja, praćenje poljoprivrede, pa čak i rekreativnu upotrebu. Mogu pristupiti udaljenim ili opasnim područjima koja su teška ili opasna za ljude.
19. Proširena stvarnost (AR)
Proširena stvarnost (AR) je tehnologija koja kombinira stvarni svijet s virtualnim objektima ili informacijama kako bi poboljšala našu percepciju i interakciju s okolinom. Prekriva kompjuterski generisane slike, zvukove ili druge senzorne inpute u stvarni svijet, stvarajući impresivno i interaktivno iskustvo.
Jednostavno, zamislite da nosite posebne naočale ili koristite svoj pametni telefon da vidite svijet oko sebe, ali s dodanim dodatnim virtuelnim elementima.
Na primjer, možete usmjeriti svoj pametni telefon na gradsku ulicu i vidjeti virtuelne putokaze koji pokazuju upute, ocjene i recenzije za obližnje restorane ili čak virtualne likove koji komuniciraju sa stvarnim okruženjem.
Ovi virtuelni elementi se neprimjetno spajaju sa stvarnim svijetom, poboljšavajući vaše razumijevanje i doživljaj okoline. Proširena stvarnost se može koristiti u raznim poljima poput igara, obrazovanja, arhitekture, pa čak i za svakodnevne zadatke poput navigacije ili isprobavanja novog namještaja u vašem domu prije nego što ga kupite.
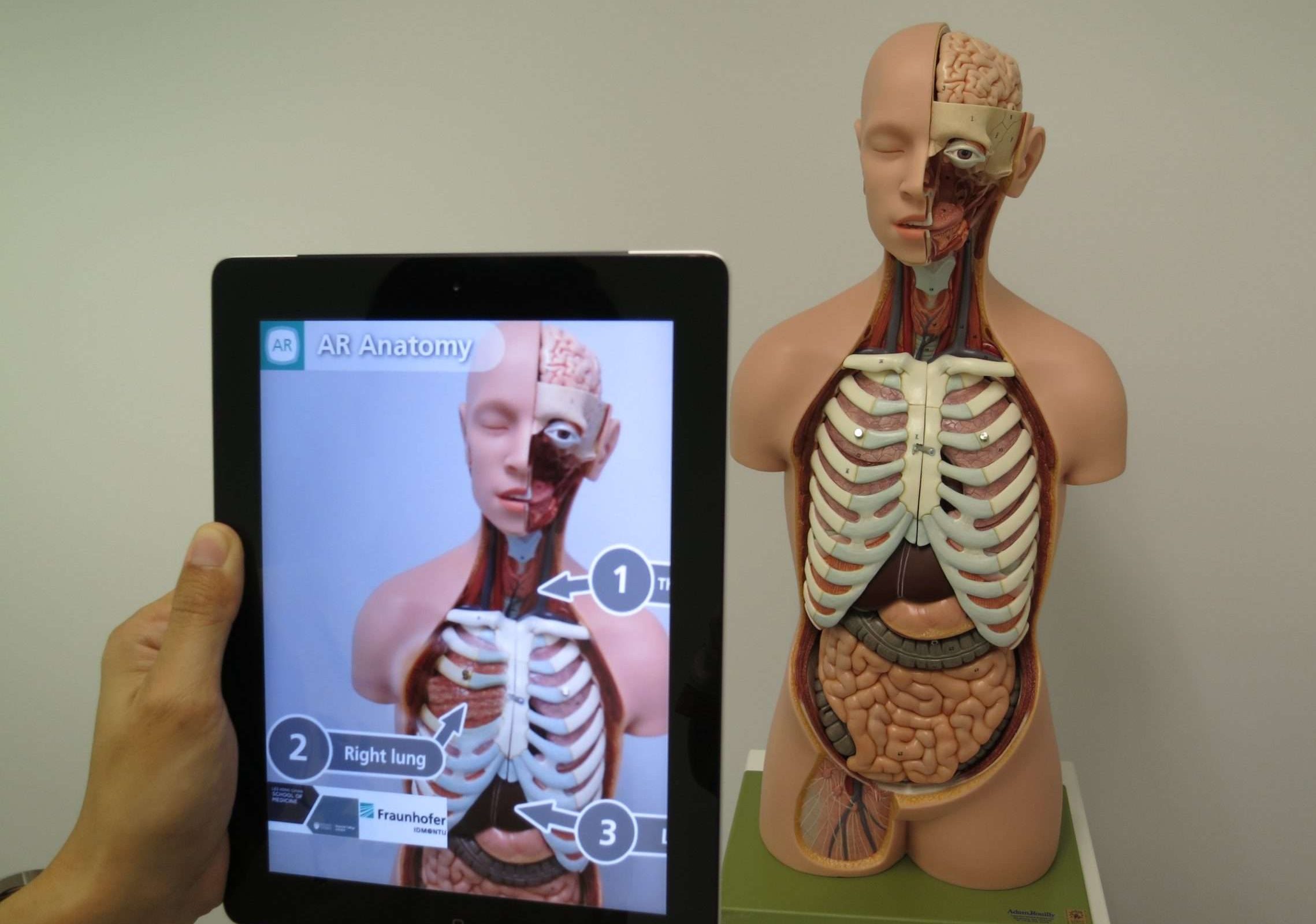
20. Virtualna stvarnost (VR)
Virtuelna stvarnost (VR) je tehnologija koja koristi kompjuterski generisane simulacije za stvaranje veštačkog okruženja koje osoba može da istražuje i da sa njim komunicira. On uranja korisnika u virtuelni svijet, blokirajući stvarni svijet i zamjenjujući ga digitalnim svijetom.
Jednostavno, zamislite da stavite posebne slušalice koje pokrivaju vaše oči i uši i prenose vas na potpuno drugo mjesto. U ovom virtuelnom svetu, sve što vidite i čujete deluje neverovatno stvarno, iako je sve generisano kompjuterom.
Možete se kretati okolo, gledati u bilo kojem smjeru i komunicirati s objektima ili likovima kao da su fizički prisutni.
Na primjer, u igri virtuelne stvarnosti, možete se naći unutar srednjovjekovnog zamka, gdje možete prošetati njegovim hodnicima, pokupiti oružje i upustiti se u borbe mačevima s virtuelnim protivnicima. Okruženje virtuelne stvarnosti reaguje na vaše pokrete i radnje, čineći da se osećate potpuno uronjeni i uključeni u iskustvo.
Virtuelna stvarnost se ne koristi samo za igranje igara već i za razne druge aplikacije kao što su simulacije obuke za pilote, hirurge ili vojno osoblje, arhitektonska uputstva, virtuelni turizam, pa čak i terapija za određena psihološka stanja. Stvara osjećaj prisutnosti i prenosi korisnike u nove i uzbudljive virtuelne svjetove, čineći iskustvo što bliže stvarnosti.
21. Nauka o podacima
Nauka o podacima je polje koje uključuje korištenje naučnih metoda, alata i algoritama za izvlačenje vrijednog znanja i uvida iz podataka. Kombinira elemente matematike, statistike, programiranja i ekspertize u domenu za analizu velikih i složenih skupova podataka.
Jednostavnije rečeno, nauka o podacima je pronalaženje značajnih informacija i obrazaca skrivenih u gomili podataka. To uključuje prikupljanje, čišćenje i organiziranje podataka, zatim korištenje različitih tehnika za njihovo istraživanje i analizu. Naučnici podataka koristiti statističke modele i algoritme za otkrivanje trendova, predviđanja i rješavanje problema.
Na primjer, u području zdravstvene zaštite, nauka o podacima može se koristiti za analizu kartona pacijenata i medicinskih podataka kako bi se identificirali faktori rizika za bolesti, predvidjeli ishodi pacijenata ili optimizirali planovi liječenja. U poslovanju, nauka o podacima može se primijeniti na podatke o kupcima kako bi se razumjele njihove preferencije, preporučile proizvode ili poboljšale marketinške strategije.
22. Data Wrangling
Razmatranje podataka, također poznato kao prikupljanje podataka, je proces prikupljanja, čišćenja i transformacije neobrađenih podataka u format koji je korisniji i pogodniji za analizu. To uključuje rukovanje i pripremu podataka kako bi se osigurao njihov kvalitet, konzistentnost i kompatibilnost s alatima ili modelima za analizu.
Jednostavnije rečeno, svađanje podataka je kao priprema sastojaka za kuvanje. To uključuje prikupljanje podataka iz različitih izvora, njihovo razvrstavanje i čišćenje kako bi se uklonile sve greške, nedosljednosti ili nebitne informacije.
Dodatno, podaci će možda morati da se transformišu, restrukturiraju ili agregiraju kako bi se olakšalo rad sa njima i izvlačenje uvida iz njih.
Na primjer, svađanje podataka može uključivati uklanjanje duplih unosa, ispravljanje pogrešno napisanih ili problema s formatiranjem, rukovanje vrijednostima koje nedostaju i pretvaranje tipova podataka. To također može uključivati spajanje ili spajanje različitih skupova podataka zajedno, dijeljenje podataka u podskupove ili kreiranje novih varijabli na osnovu postojećih podataka.
23. Data Storytelling
Data storytelling je umjetnost predstavljanja podataka na uvjerljiv i privlačan način kako bi se djelotvorno prenijela priča ili poruka. To uključuje korištenje vizualizacije podataka, naracije i kontekst kako bi se prenijeli uvidi i nalazi na način koji je razumljiv i pamtljiv publici.
Jednostavnije rečeno, pripovijedanje podataka je korištenje podataka za pričanje priče. To ide dalje od samo predstavljanja brojeva i grafikona. Uključuje kreiranje naracije oko podataka, korištenje vizualnih elemenata i tehnika pripovijedanja kako bi podaci oživjeli i učinili ih povezanim sa publikom.
Na primjer, umjesto jednostavnog predstavljanja tabele prodajnih podataka, pripovijedanje podataka može uključivati kreiranje interaktivne kontrolne ploče koja omogućava korisnicima da vizualno istraže trendove prodaje.
Može uključivati narativ koji ističe ključne nalaze, objašnjava razloge iza trendova i predlaže preporuke koje se mogu primijeniti na osnovu podataka.
24. Donošenje odluka vođeno podacima
Donošenje odluka vođeno podacima je proces donošenja izbora ili poduzimanja radnji na osnovu analize i interpretacije relevantnih podataka. To uključuje korištenje podataka kao temelja za usmjeravanje i podršku procesa donošenja odluka, a ne oslanjanje isključivo na intuiciju ili ličnu prosudbu.
Jednostavnije rečeno, donošenje odluka zasnovano na podacima znači korištenje činjenica i dokaza iz podataka za informiranje i usmjeravanje izbora koje donosimo. To uključuje prikupljanje i analizu podataka kako bi se razumjeli obrasci, trendovi i odnosi i korištenje tog znanja za donošenje informiranih odluka i rješavanje problema.
Na primjer, u poslovnom okruženju, donošenje odluka vođeno podacima može uključivati analizu podataka o prodaji, povratnih informacija kupaca i tržišnih trendova kako bi se odredila najefikasnija strategija određivanja cijena ili identificirala područja za poboljšanje u razvoju proizvoda.
U zdravstvu, to može uključivati analizu podataka o pacijentima kako bi se optimizirali planovi liječenja ili predvidjeli ishodi bolesti.
25. Data Lake
Jezero podataka je centralizirano i skalabilno spremište podataka koje pohranjuje ogromne količine podataka u sirovom i neobrađenom obliku. Dizajniran je da drži širok spektar tipova podataka, formata i struktura, kao što su strukturirani, polustrukturirani i nestrukturirani podaci, bez potrebe za unaprijed definiranim shemama ili transformacijama podataka.
Na primjer, kompanija može prikupljati i pohranjivati podatke iz različitih izvora, kao što su zapisnici web stranice, transakcije kupaca, feedovi društvenih medija i IoT uređaji, u jezeru podataka.
Ovi podaci se zatim mogu koristiti u različite svrhe, kao što je provođenje napredne analitike, izvođenje algoritama strojnog učenja ili istraživanje obrazaca i trendova u ponašanju kupaca.
26. Skladište podataka
Skladište podataka je specijalizovani sistem baze podataka koji je posebno dizajniran za skladištenje, organizovanje i analizu velikih količina podataka iz različitih izvora. Strukturiran je na način koji podržava efikasno pronalaženje podataka i složene analitičke upite.
Služi kao centralno spremište koje integriše podatke iz različitih operativnih sistema, kao što su transakcijske baze podataka, CRM sistemi i drugi izvori podataka unutar organizacije.
Podaci se transformišu, čiste i učitavaju u skladište podataka u strukturiranom formatu optimiziranom za analitičke svrhe.
27. Poslovna inteligencija (BI)
Poslovna inteligencija se odnosi na proces prikupljanja, analiziranja i predstavljanja podataka na način koji pomaže preduzećima da donose informirane odluke i steknu vrijedne uvide. To uključuje korištenje različitih alata, tehnologija i tehnika za transformaciju sirovih podataka u smislene, djelotvorne informacije.
Na primjer, sistem poslovne inteligencije može analizirati podatke o prodaji kako bi identifikovao najprofitabilnije proizvode, prati nivoe zaliha i prati želje kupaca.
Može da pruži uvid u realnom vremenu u ključne indikatore učinka (KPI) kao što su prihod, privlačenje kupaca ili performanse proizvoda, omogućavajući preduzećima da donose odluke zasnovane na podacima i poduzmu odgovarajuće radnje za poboljšanje svog poslovanja.
Alati poslovne inteligencije često uključuju funkcije kao što su vizualizacija podataka, ad hoc upiti i mogućnosti istraživanja podataka. Ovi alati omogućavaju korisnicima, kao npr poslovni analitičari ili menadžere, da komuniciraju sa podacima, iseku ih na kockice i generišu izveštaje ili vizuelne prikaze koji ističu važne uvide i trendove.
28. Prediktivna analitika
Prediktivna analiza je praksa korištenja podataka i statističkih tehnika za pravljenje informiranih predviđanja ili prognoza o budućim događajima ili ishodima. To uključuje analizu istorijskih podataka, identifikaciju obrazaca i izgradnju modela za ekstrapolaciju i procjenu budućih trendova, ponašanja ili pojava.
Cilj mu je otkriti odnose između varijabli i koristiti te informacije za predviđanje. To ide dalje od jednostavnog opisivanja prošlih događaja; umjesto toga, koristi istorijske podatke kako bi razumio i predvidio šta će se vjerovatno dogoditi u budućnosti.
Na primjer, u oblasti finansija, prediktivna analiza se može koristiti za predviđanje zaliha cijene zasnovane na istorijskim tržišnim podacima, ekonomskim pokazateljima i drugim relevantnim faktorima.
U marketingu se može koristiti za predviđanje ponašanja i preferencija kupaca, omogućavajući ciljano oglašavanje i personalizirane marketinške kampanje.
U zdravstvu, prediktivna analiza može pomoći u identifikaciji pacijenata sa visokim rizikom za određene bolesti ili predvidjeti vjerovatnoću ponovnog prijema na osnovu medicinske istorije i drugih faktora.
29. Preskriptivna analitika
Preskriptivna analitika je primjena podataka i analitike za određivanje najboljih mogućih radnji koje treba poduzeti u određenoj situaciji ili scenariju donošenja odluka.
To ide dalje od deskriptivnog i prediktivna analitika ne samo pružanjem uvida o tome šta bi se moglo dogoditi u budućnosti, već i preporukom najoptimalnijeg pravca djelovanja za postizanje željenog ishoda.
Kombinira istorijske podatke, prediktivne modele i tehnike optimizacije za simulaciju različitih scenarija i procjenu potencijalnih ishoda različitih odluka. Uzima u obzir višestruka ograničenja, ciljeve i faktore kako bi se generirale praktične preporuke koje maksimiziraju željene rezultate ili minimiziraju rizike.
Na primjer, u lanac opskrbe menadžment, preskriptivna analitika može analizirati podatke o nivoima zaliha, proizvodnim kapacitetima, troškovima transporta i potražnji kupaca kako bi se odredio najefikasniji plan distribucije.
Može preporučiti idealnu alokaciju resursa, kao što su lokacije za skladištenje zaliha ili transportne rute, kako bi se minimizirali troškovi i osigurala pravovremena isporuka.
30. Marketing vođen podacima
Marketing vođen podacima odnosi se na praksu korištenja podataka i analitike za pokretanje marketinških strategija, kampanja i procesa donošenja odluka.
To uključuje korištenje različitih izvora podataka za stjecanje uvida u ponašanje kupaca, preferencije i trendove i korištenje tih informacija za optimizaciju marketinških napora.
Fokusira se na prikupljanje i analizu podataka iz više dodirnih tačaka, kao što su interakcije na web stranici, angažman na društvenim mrežama, demografija kupaca, istorija kupovine i još mnogo toga. Ovi podaci se zatim koriste za stvaranje sveobuhvatnog razumijevanja ciljne publike, njenih preferencija i potreba.
Koristeći podatke, trgovci mogu donijeti informirane odluke u vezi segmentacije kupaca, ciljanja i personalizacije.
Oni mogu identificirati specifične segmente kupaca za koje je vjerojatnije da će pozitivno odgovoriti na marketinške kampanje i u skladu s tim prilagoditi svoje poruke i ponude.
Osim toga, marketing vođen podacima pomaže u optimizaciji marketinških kanala, određivanju najefikasnijeg marketinškog miksa i mjerenju uspjeha marketinških inicijativa.
Na primjer, marketinški pristup vođen podacima može uključivati analizu podataka o kupcima kako bi se identificirali obrasci ponašanja i preferencija pri kupovini. Na osnovu ovih uvida, trgovci mogu kreirati ciljane kampanje s personaliziranim sadržajem i ponudama koje odgovaraju određenim segmentima kupaca.
Kroz stalnu analizu i optimizaciju, oni mogu mjeriti djelotvornost svojih marketinških napora i precizirati strategije tokom vremena.
31. Upravljanje podacima
Upravljanje podacima je okvir i skup praksi koje organizacije usvajaju kako bi osigurale pravilno upravljanje, zaštitu i integritet podataka tokom njihovog životnog ciklusa. Obuhvaća procese, politike i procedure koje upravljaju načinom na koji se podaci prikupljaju, pohranjuju, pristupaju, koriste i dijele unutar organizacije.
Ima za cilj uspostavljanje odgovornosti, odgovornosti i kontrole nad imovinom podataka. Osigurava da su podaci tačni, potpuni, dosljedni i pouzdani, omogućavajući organizacijama da donose informirane odluke, održavaju kvalitet podataka i ispunjavaju regulatorne zahtjeve.
Upravljanje podacima uključuje definisanje uloga i odgovornosti za upravljanje podacima, uspostavljanje standarda i politika podataka i implementaciju procesa za praćenje i sprovođenje usklađenosti. Obrađuje različite aspekte upravljanja podacima, uključujući privatnost podataka, sigurnost podataka, kvalitet podataka, klasifikaciju podataka i upravljanje životnim ciklusom podataka.
Na primjer, upravljanje podacima može uključivati implementaciju procedura kako bi se osiguralo da se ličnim ili osjetljivim podacima rukuje u skladu s primjenjivim propisima o privatnosti, kao što je Opća uredba o zaštiti podataka (GDPR).
To također može uključivati uspostavljanje standarda kvaliteta podataka i implementaciju procesa validacije podataka kako bi se osiguralo da su podaci tačni i pouzdani.
32. Sigurnost podataka
Sigurnost podataka je zaštita naših vrijednih informacija od neovlaštenog pristupa ili krađe. To uključuje poduzimanje mjera za zaštitu povjerljivosti, integriteta i dostupnosti podataka.
U suštini, to znači osigurati da samo pravi ljudi mogu pristupiti našim podacima, da oni ostanu tačni i nepromijenjeni i da su dostupni kada je to potrebno.
Za postizanje sigurnosti podataka koriste se različite strategije i tehnologije. Na primjer, kontrole pristupa i metode šifriranja pomažu da se ograniči pristup ovlaštenim pojedincima ili sistemima, što otežava pristup našim podacima osobama izvana.
Sistemi za nadzor, zaštitni zidovi i sistemi za otkrivanje upada djeluju kao čuvari, upozoravajući nas na sumnjive aktivnosti i sprječavajući neovlašteni pristup.
33. Internet stvari
Internet stvari (IoT) se odnosi na mrežu fizičkih objekata ili "stvari" koje su povezane na Internet i mogu međusobno komunicirati. To je poput velike mreže svakodnevnih objekata, uređaja i mašina koji su u stanju da dijele informacije i obavljaju zadatke interakcijom putem interneta.
Jednostavno rečeno, IoT uključuje davanje „pametnih“ mogućnosti raznim objektima ili uređajima koji tradicionalno nisu bili povezani na internet. Ovi predmeti mogu uključivati kućanske aparate, nosive uređaje, termostate, automobile, pa čak i industrijske mašine.
Povezivanjem ovih objekata na internet, oni mogu prikupljati i dijeliti podatke, primati upute i obavljati zadatke samostalno ili kao odgovor na korisničke komande.
Na primjer, pametni termostat može pratiti temperaturu, podešavati postavke i slati izvještaje o potrošnji energije aplikaciji za pametni telefon. Nosivi fitnes tracker može prikupljati podatke o vašim fizičkim aktivnostima i sinkronizirati ih s platformom zasnovanom na oblaku za analizu.
34. Stablo odluka
Stablo odlučivanja je vizuelni prikaz ili dijagram koji nam pomaže da donesemo odluke ili odredimo pravac delovanja na osnovu niza izbora ili uslova.
To je poput dijagrama toka koji nas vodi kroz proces donošenja odluka razmatrajući različite opcije i njihove potencijalne ishode.
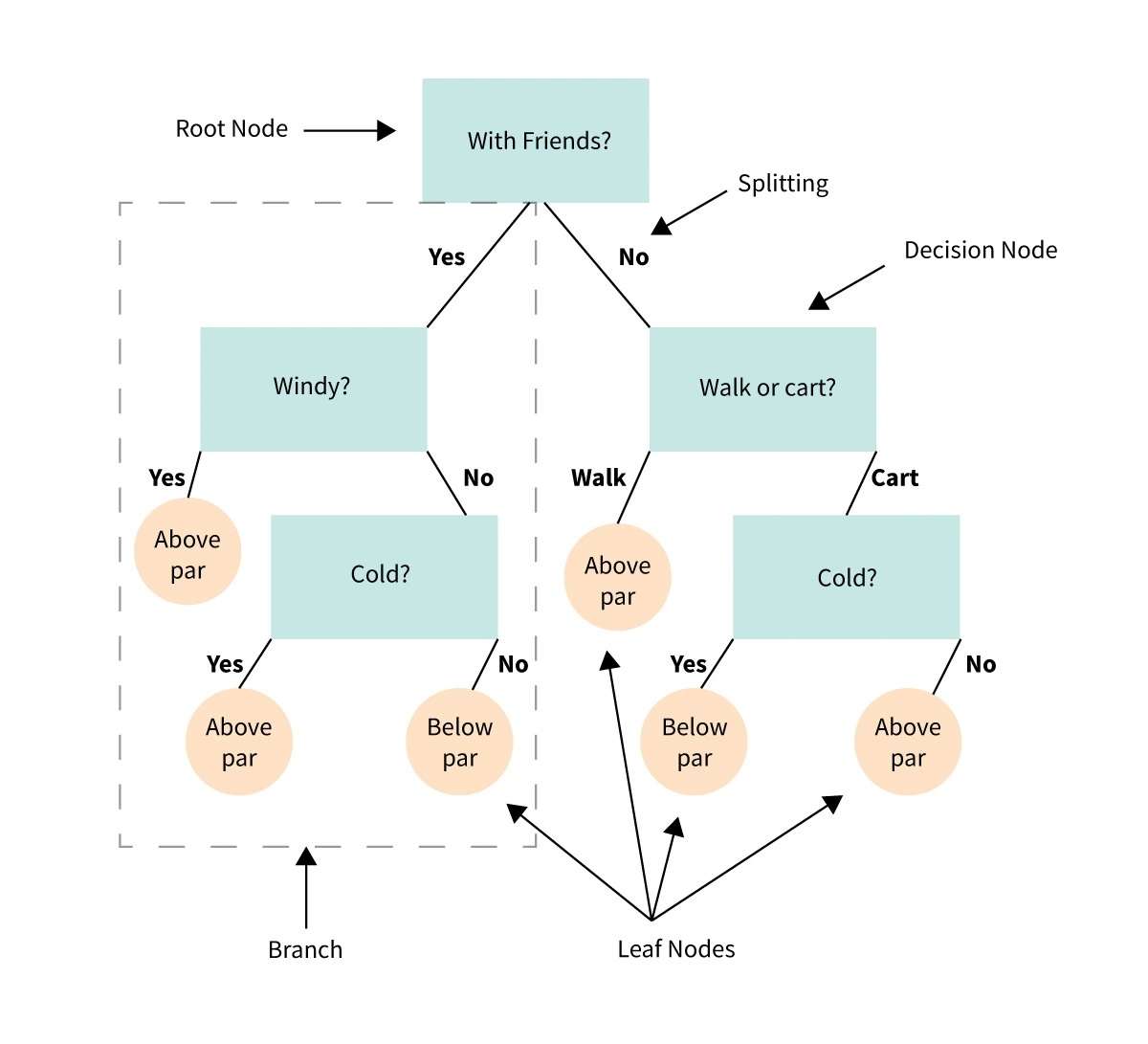
Zamislite da imate problem ili pitanje i morate napraviti izbor.
Stablo odlučivanja rastavlja odluku na manje korake, počevši od početnog pitanja i granajući se na različite moguće odgovore ili radnje na osnovu uslova ili kriterijuma u svakom koraku.
35. Kognitivno računarstvo
Kognitivno računarstvo, jednostavnim rečima, odnosi se na kompjuterske sisteme ili tehnologije koje oponašaju ljudske kognitivne sposobnosti, kao što su učenje, rasuđivanje, razumevanje i rešavanje problema.
To uključuje stvaranje kompjuterskih sistema koji mogu obraditi i interpretirati informacije na način koji liči na ljudsko razmišljanje.
Kognitivno računarstvo ima za cilj razvoj mašina koje mogu razumjeti i komunicirati s ljudima na prirodniji i inteligentniji način. Ovi sistemi su dizajnirani da analiziraju ogromne količine podataka, prepoznaju obrasce, daju predviđanja i daju smislene uvide.
Zamislite kognitivno računarstvo kao pokušaj da se kompjuteri natjeraju da razmišljaju i ponašaju se više kao ljudi.
To uključuje korištenje tehnologija kao što su umjetna inteligencija, strojno učenje, obrada prirodnog jezika i kompjuterski vid kako bi se omogućilo kompjuterima da obavljaju zadatke koji su tradicionalno bili povezani s ljudskom inteligencijom.
36. Računarska teorija učenja
Teorija računarskog učenja je specijalizirana grana u području umjetne inteligencije koja se vrti oko razvoja i ispitivanja algoritama posebno dizajniranih za učenje iz podataka.
Ovo polje istražuje različite tehnike i metodologije za konstruisanje algoritama koji mogu autonomno poboljšati svoje performanse analizom i obradom velikih količina informacija.
Koristeći moć podataka, teorija računarskog učenja ima za cilj da otkrije obrasce, odnose i uvide koji omogućavaju mašinama da unaprede svoje sposobnosti donošenja odluka i efikasnije obavljaju zadatke.
Krajnji cilj je stvaranje algoritama koji se mogu prilagoditi, generalizirati i napraviti tačna predviđanja na osnovu podataka kojima su bili izloženi, doprinoseći napretku umjetne inteligencije i njene praktične primjene.
37. Tjuringov test
Tjuringov test, koji je prvobitno predložio briljantni matematičar i informatičar Alan Turing, je zadivljujući koncept koji se koristi za procenu da li mašina može da pokaže inteligentno ponašanje koje se može uporediti ili se praktično ne razlikuje od ljudskog bića.
U Tjuringovom testu, ljudski evaluator ulazi u razgovor na prirodnom jeziku i sa mašinom i sa drugim ljudskim učesnikom, a da ne zna koji je od njih mašina.
Uloga evaluatora je da razluči koji je entitet mašina isključivo na osnovu njihovih odgovora. Ako je mašina u stanju da uvjeri ocjenjivača da je ljudski pandan, onda se kaže da je prošla Turingov test, pokazujući na taj način nivo inteligencije koji odražava ljudske sposobnosti.
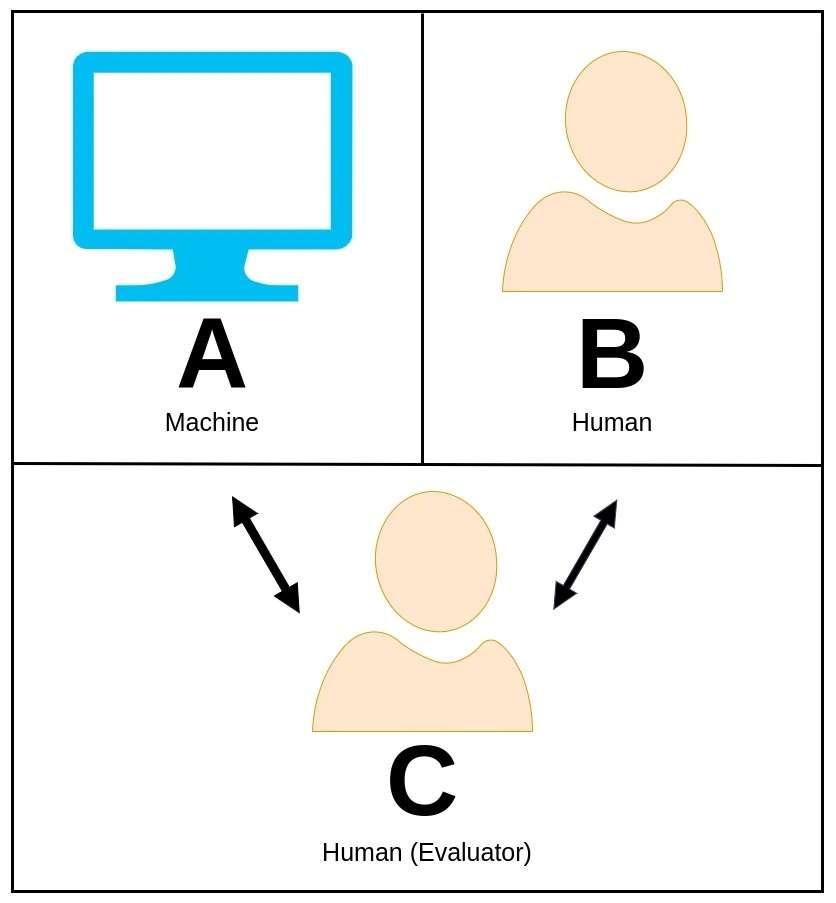
Alan Turing je predložio ovaj test kao sredstvo za istraživanje koncepta mašinske inteligencije i za postavljanje pitanja da li mašine mogu postići spoznaju na ljudskom nivou.
Uokvirujući test u smislu ljudske nerazlučivosti, Turing je istakao potencijal mašina da pokažu ponašanje koje je toliko uvjerljivo inteligentno da postaje izazov razlikovati ih od ljudi.
Tjuringov test je izazvao opsežne rasprave i istraživanja u oblastima veštačke inteligencije i kognitivne nauke. Iako polaganje Turingovog testa ostaje značajna prekretnica, to nije jedina mjera inteligencije.
Ipak, test služi kao mjerilo za razmišljanje, stimulirajući stalne napore da se razviju mašine sposobne da oponašaju inteligenciju i ponašanje nalik ljudima i doprinose širem istraživanju onoga što znači biti inteligentan.
38. Učenje s pojačanjem
Ojačavanje učenja je vrsta učenja koja se događa putem pokušaja i pogrešaka, gdje "agent" (koji može biti kompjuterski program ili robot) uči da obavlja zadatke primajući nagrade za dobro ponašanje i suočavanje s posljedicama ili kaznama za loše ponašanje.
Zamislite scenario u kojem agent pokušava izvršiti određeni zadatak, kao što je navigacija lavirintom. U početku, agent ne zna ispravan put kojim treba krenuti, pa pokušava različite akcije i istražuje različite rute.
Kada odabere dobru akciju koja ga približava cilju, dobija nagradu, poput virtuelnog „tapšanja po leđima“. Međutim, ako donese lošu odluku koja vodi u ćorsokak ili ga udalji od cilja, dobija kaznu ili negativnu povratnu informaciju.
Kroz ovaj proces pokušaja i pogrešaka, agent uči da poveže određene radnje s pozitivnim ili negativnim ishodima. Postepeno smišlja najbolji slijed radnji kako bi maksimizirao svoje nagrade i minimizirao kazne, na kraju postaje vještiji u zadatku.
Učenje s pojačanjem crpi inspiraciju iz načina na koji ljudi i životinje uče primajući povratne informacije iz okoline.
Primenjujući ovaj koncept na mašine, istraživači imaju za cilj da razviju inteligentne sisteme koji mogu da uče i prilagođavaju se različitim situacijama autonomno otkrivajući najefikasnija ponašanja kroz proces pozitivnog pojačanja i negativnih posledica.
39. Ekstrakcija entiteta
Ekstrakcija entiteta se odnosi na proces u kojem identifikujemo i izdvajamo važne delove informacija, poznatih kao entiteti, iz bloka teksta. Ti entiteti mogu biti različite stvari poput imena ljudi, imena mjesta, imena organizacija itd.
Zamislimo da imate paragraf koji opisuje novinski članak.
Ekstrakcija entiteta bi uključivala analizu teksta i odabir specifičnih bitova koji predstavljaju različite entitete. Na primjer, ako se u tekstu spominje ime osobe kao što je “John Smith”, lokacija “New York City” ili organizacija “OpenAI”, to bi bili entiteti koje želimo identificirati i izdvojiti.
Izvođenjem ekstrakcije entiteta, u suštini učimo kompjuterski program da prepozna i izoluje značajne elemente iz teksta. Ovaj proces nam omogućava da efikasnije organizujemo i kategorizujemo informacije, što olakšava pretragu, analizu i dobijanje uvida iz velikih količina tekstualnih podataka.
Sve u svemu, izdvajanje entiteta nam pomaže da automatiziramo zadatak preciziranja važnih entiteta, kao što su ljudi, mjesta i organizacije, unutar teksta, pojednostavljujući izdvajanje vrijednih informacija i poboljšavajući našu sposobnost obrade i razumijevanja tekstualnih podataka.
40. Lingvistička anotacija
Jezičko označavanje uključuje obogaćivanje teksta dodatnim lingvističkim informacijama kako bismo poboljšali naše razumijevanje i analizu jezika koji se koristi. To je kao dodavanje korisnih oznaka ili oznaka različitim dijelovima teksta.
Kada izvodimo lingvističku notaciju, idemo dalje od osnovnih riječi i rečenica u tekstu i počinjemo označavati ili označavati određene elemente. Na primjer, možemo dodati oznake dijela govora, koje označavaju gramatičku kategoriju svake riječi (kao što su imenica, glagol, pridjev, itd.). Ovo nam pomaže da razumijemo ulogu koju svaka riječ igra u rečenici.
Drugi oblik jezičke notacije je prepoznavanje imenovanih entiteta, gdje identificiramo i označavamo određene imenovane entitete, kao što su imena ljudi, mjesta, organizacija ili datumi. To nam omogućava da brzo lociramo i izvučemo važne informacije iz teksta.
Obilježavanjem teksta na ove načine stvaramo strukturiraniju i organiziraniju reprezentaciju jezika. Ovo može biti izuzetno korisno u raznim aplikacijama. Na primjer, pomaže u poboljšanju tačnosti pretraživača razumijevanjem namjere iza korisničkih upita. Takođe pomaže u mašinskom prevođenju, analizi osećanja, ekstrakciji informacija i mnogim drugim zadacima obrade prirodnog jezika.
Lingvističke beleške služe kao vitalni alat za istraživače, lingviste i programere, omogućavajući im da proučavaju jezičke obrasce, grade jezičke modele i razvijaju sofisticirane algoritme koji mogu bolje analizirati i razumeti tekst.
41. Hiperparametar
In mašinsko učenje, hiperparametar je poput posebne postavke ili konfiguracije za koju moramo odlučiti prije obučavanja modela. To nije nešto što model može sam naučiti iz podataka; umjesto toga, moramo to unaprijed odrediti.
Zamislite to kao dugme ili prekidač koji možemo podesiti da fino podesimo kako model uči i predviđa. Ovi hiperparametri upravljaju različitim aspektima procesa učenja, kao što su složenost modela, brzina obuke i kompromis između tačnosti i generalizacije.
Na primjer, razmotrimo neuronsku mrežu. Jedan važan hiperparametar je broj slojeva u mreži. Moramo izabrati koliko želimo da mreža bude duboka, a ova odluka utiče na njenu sposobnost da uhvati složene obrasce u podacima.
Drugi uobičajeni hiperparametri uključuju brzinu učenja, koja određuje koliko brzo model prilagođava svoje interne parametre na osnovu podataka o obuci, i snagu regularizacije, koja kontrolira koliko model kažnjava složene obrasce kako bi spriječio prekomjerno prilagođavanje.
Ispravno postavljanje ovih hiperparametara je ključno jer oni mogu značajno utjecati na performanse i ponašanje modela. Često uključuje malo pokušaja i grešaka, eksperimentisanje sa različitim vrednostima i posmatranje kako one utiču na performanse modela na skupu podataka za validaciju.
42. Metapodaci
Metapodaci se odnose na dodatne informacije koje pružaju detalje o drugim podacima. To je poput skupa oznaka ili oznaka koje nam daju više konteksta ili opisuju karakteristike glavnih podataka.
Kada imamo podatke, bilo da se radi o dokumentu, fotografiji, video zapisu ili bilo kojoj drugoj vrsti informacija, metapodaci nam pomažu da razumijemo važne aspekte tih podataka.
Na primjer, u dokumentu, metapodaci mogu uključivati detalje kao što su ime autora, datum kada je kreiran ili format datoteke. U slučaju fotografije, metapodaci nam mogu reći lokaciju na kojoj je snimljena, korištene postavke kamere ili čak datum i vrijeme snimanja.
Metapodaci nam pomažu da efikasnije organizujemo, pretražujemo i interpretiramo podatke. Dodavanjem ovih opisnih informacija možemo brzo pronaći određene datoteke ili razumjeti njihovo porijeklo, svrhu ili kontekst bez potrebe da kopamo po cijelom sadržaju.
43. Smanjenje dimenzionalnosti
Smanjenje dimenzionalnosti je tehnika koja se koristi za pojednostavljenje skupa podataka smanjenjem broja karakteristika ili varijabli koje sadrži. To je kao sažimanje ili sažimanje informacija u skupu podataka kako bi se njime lakše upravljalo i sa njim lakše raditi.
Zamislite da imate skup podataka s brojnim stupcima ili atributima koji predstavljaju različite karakteristike tačaka podataka. Svaki stupac doprinosi složenosti i računskim zahtjevima algoritama mašinskog učenja.
U nekim slučajevima, veliki broj dimenzija može otežati pronalaženje smislenih obrazaca ili odnosa u podacima.
Smanjenje dimenzionalnosti pomaže u rješavanju ovog problema transformacijom skupa podataka u nižedimenzionalni prikaz zadržavajući što je moguće više relevantnih informacija. Cilj mu je uhvatiti najvažnije aspekte ili varijacije u podacima uz odbacivanje suvišnih ili manje informativnih dimenzija.
44. Klasifikacija teksta
Klasifikacija teksta je proces koji uključuje dodjeljivanje specifičnih oznaka ili kategorija blokovima teksta na osnovu njihovog sadržaja ili značenja. To je poput sortiranja ili organiziranja tekstualnih informacija u različite grupe ili klase kako bi se olakšala daljnja analiza ili donošenje odluka.
Razmotrimo primjer klasifikacije e-pošte. U ovom scenariju želimo da utvrdimo da li je dolazna e-pošta neželjena pošta ili nije neželjena (poznata i kao šunka). Klasifikacija teksta algoritmi analiziraju sadržaj e-pošte i u skladu s tim mu dodijeljuju oznaku.
Ako algoritam utvrdi da e-pošta pokazuje karakteristike koje se obično povezuju sa neželjenom poštom, dodeljuje oznaku „neželjena pošta“. Suprotno tome, ako se e-pošta čini legitimnom i ne-spamnom, ona dodeljuje oznaku „nije neželjena pošta“ ili „šunka“.
Klasifikacija teksta pronalazi primjene u različitim domenama izvan filtriranja e-pošte. Koristi se u analizi sentimenta kako bi se odredilo raspoloženje izraženo u recenzijama kupaca (pozitivno, negativno ili neutralno).
Članci vijesti mogu se klasificirati u različite teme ili kategorije poput sporta, politike, zabave i još mnogo toga. Dnevnici razgovora za korisničku podršku mogu se kategorizirati na osnovu namjere ili problema koji se rješava.
45. Slab AI
Slaba AI, također poznata kao uska AI, odnosi se na sisteme umjetne inteligencije koji su dizajnirani i programirani za obavljanje određenih zadataka ili funkcija. Za razliku od ljudske inteligencije, koja obuhvata širok spektar kognitivnih sposobnosti, slaba AI je ograničena na određenu domenu ili zadatak.
Zamislite slabu umjetnu inteligenciju kao specijalizirani softver ili mašine koje su izvrsne u obavljanju određenih poslova. Na primjer, AI program za igranje šaha može biti kreiran za analizu situacija u igri, strategiju poteza i nadmetanje protiv ljudskih igrača.
Drugi primjer je sistem za prepoznavanje slika koji može identificirati objekte na fotografijama ili video zapisima.
Ovi sistemi veštačke inteligencije su obučeni i optimizovani da se ističu u svojim specifičnim oblastima stručnosti. Oni se oslanjaju na algoritme, podatke i unaprijed definirana pravila kako bi efikasno izvršili svoje zadatke.
Međutim, oni ne poseduju opštu inteligenciju koja im omogućava da razumeju ili obavljaju zadatke izvan njihovog domena.
46. Jaka AI
Jaka AI, takođe poznata kao opšta AI ili veštačka opšta inteligencija (AGI), odnosi se na oblik veštačke inteligencije koja poseduje sposobnost razumevanja, učenja i obavljanja bilo kojeg intelektualnog zadatka koji ljudsko biće može.
Za razliku od slabe AI, koja je dizajnirana za specifične zadatke, jaka AI ima za cilj da replicira inteligenciju i kognitivne sposobnosti slične ljudskoj. Nastoji da stvori mašine ili softver koji ne samo da se ističu u specijalizovanim zadacima, već i poseduju šire razumevanje i prilagodljivost za rešavanje širokog spektra intelektualnih izazova.
Cilj jake AI je razviti sisteme koji mogu razumjeti, razumjeti složene informacije, učiti iz iskustva, uključiti se u razgovore na prirodnom jeziku, pokazati kreativnost i pokazati druge kvalitete povezane s ljudskom inteligencijom.
U suštini, teži stvaranju AI sistema koji mogu simulirati ili replicirati razmišljanje i rješavanje problema na ljudskom nivou u više domena.
47. Naprijed lančano
Ulančavanje naprijed je metoda zaključivanja ili logike koja počinje od dostupnih podataka i koristi ih za donošenje zaključaka i izvlačenje novih zaključaka. To je poput povezivanja tačaka korištenjem dostupnih informacija kako biste krenuli naprijed i došli do dodatnih uvida.
Zamislite da imate skup pravila ili činjenica i želite izvući nove informacije ili na osnovu njih doći do konkretnih zaključaka. Unaprijeđeno lančano povezivanje radi ispitivanjem početnih podataka i primjenom logičkih pravila za generiranje dodatnih činjenica ili zaključaka.
Da pojednostavimo, razmotrimo jednostavan scenario određivanja šta obući na osnovu vremenskih uslova. Imate pravilo koje kaže: „Ako pada kiša, ponesite kišobran“, i drugo pravilo koje kaže „Ako je hladno, nosite jaknu“. Sada, ako primijetite da zaista pada kiša, možete upotrijebiti ulančavanje naprijed da zaključite da biste trebali ponijeti kišobran.
48. Lanac unatrag
Lanac unatrag je metoda rasuđivanja koja počinje sa željenim zaključkom ili ciljem i radi unatrag kako bi se utvrdili potrebni podaci ili činjenice potrebne za potporu tog zaključka. To je kao da pratite svoje korake od željenog ishoda do početnih informacija potrebnih za postizanje istog.
Da bismo razumjeli ulančavanje unatrag, razmotrimo jednostavan primjer. Pretpostavimo da želite da utvrdite da li je prikladno za kupanje. Željeni zaključak je da li je plivanje prikladno ili ne na osnovu određenih uslova.
Umjesto da počne s uvjetima, ulančavanje unatrag počinje zaključkom i radi unatrag kako bi se pronašli prateći podaci.
U ovom slučaju, ulančavanje unatrag bi uključivalo postavljanje pitanja poput "Je li vrijeme toplo?" Ako je odgovor potvrdan, onda biste pitali: „Ima li dostupan bazen?“ Ako je odgovor ponovo potvrdan, postavili biste dodatna pitanja poput: „Ima li dovoljno vremena za plivanje?“
Iterativnim odgovaranjem na ova pitanja i radom unatrag, možete odrediti neophodne uslove koji se moraju ispuniti da bi se podržao zaključak o odlasku na plivanje.
49. Heuristički
Heuristika, jednostavno rečeno, je praktično pravilo ili strategija koja nam pomaže da donosimo odluke ili rješavamo probleme, obično na temelju naših prošlih iskustava ili intuicije. To je poput mentalne prečice koja nam omogućava da brzo dođemo do razumnog rješenja bez prolaska kroz dug ili iscrpan proces.
Kada se suoče sa složenim situacijama ili zadacima, heuristika služi kao vodeći principi ili „pravila palca“ koja pojednostavljuju donošenje odluka. Oni nam pružaju općenite smjernice ili strategije koje su često efikasne u određenim situacijama, iako možda ne garantuju optimalno rješenje.
Na primjer, uzmimo u obzir heuristiku za pronalaženje parking mjesta u gužvi. Umjesto da pomno analizirate svako dostupno mjesto, mogli biste se osloniti na heuristiku traženja parkiranih automobila s uključenim motorima.
Ova heuristika pretpostavlja da će ovi automobili krenuti, povećavajući šanse za pronalaženje slobodnog mjesta.
50. Modeliranje prirodnog jezika
Modeliranje prirodnog jezika, jednostavno rečeno, je proces obuke kompjuterskih modela da razumiju i generiraju ljudski jezik na način koji je sličan načinu na koji ljudi komuniciraju. To uključuje podučavanje računara da obrađuju, tumače i generišu tekst na prirodan i smislen način.
Cilj modeliranja prirodnog jezika je omogućiti kompjuterima da shvate i generišu ljudski jezik na način koji je tečan, koherentan i kontekstualno relevantan.
Uključuje modele obuke na ogromnim količinama tekstualnih podataka, kao što su knjige, članci ili razgovori, kako bi se naučili obrasci, strukture i semantika jezika.
Jednom obučeni, ovi modeli mogu obavljati različite zadatke vezane za jezik, kao što su prevođenje jezika, sažimanje teksta, odgovaranje na pitanja, interakcije s chatbotovima i još mnogo toga.
Oni mogu razumjeti značenje i kontekst rečenica, izvući relevantne informacije i generirati tekst koji je gramatički ispravan i koherentan.





Ostavite odgovor