ভিডিও গেমগুলি বিশ্বজুড়ে কোটি কোটি খেলোয়াড়দের চ্যালেঞ্জ প্রদান করে চলেছে৷ আপনি এটি এখনও জানেন না, তবে মেশিন লার্নিং অ্যালগরিদমগুলিও চ্যালেঞ্জের জন্য উঠতে শুরু করেছে।
ভিডিও গেমগুলিতে মেশিন লার্নিং পদ্ধতি প্রয়োগ করা যায় কিনা তা দেখার জন্য বর্তমানে এআই এর ক্ষেত্রে উল্লেখযোগ্য পরিমাণে গবেষণা চলছে। এই ক্ষেত্রে উল্লেখযোগ্য অগ্রগতি তা দেখায় মেশিন লার্নিং এজেন্টদের অনুকরণ বা এমনকি মানব প্লেয়ার প্রতিস্থাপন করতে ব্যবহার করা যেতে পারে।
এর ভবিষ্যতের জন্য এর অর্থ কী ভিডিও গেমস?
এই প্রকল্পগুলি কি কেবল মজা করার জন্য, নাকি অনেক গবেষক গেমগুলিতে মনোনিবেশ করছেন তার আরও গভীর কারণ আছে?
এই নিবন্ধটি ভিডিও গেমগুলিতে AI এর ইতিহাস সংক্ষিপ্তভাবে অন্বেষণ করবে। পরে, আমরা আপনাকে কিছু মেশিন লার্নিং কৌশলের একটি দ্রুত ওভারভিউ দেব যা আমরা গেমগুলিকে কীভাবে হারাতে হয় তা শিখতে ব্যবহার করতে পারি। আমরা তারপর কিছু সফল অ্যাপ্লিকেশন দেখব নিউরাল নেট নির্দিষ্ট ভিডিও গেম শিখতে এবং আয়ত্ত করতে।
গেমিং এ AI এর সংক্ষিপ্ত ইতিহাস
ভিডিও গেমগুলি সমাধান করার জন্য কেন নিউরাল নেট আদর্শ অ্যালগরিদম হয়ে উঠেছে তা জানার আগে, কম্পিউটার বিজ্ঞানীরা কীভাবে AI-তে তাদের গবেষণাকে এগিয়ে নিতে ভিডিও গেমগুলি ব্যবহার করেছেন তা সংক্ষেপে দেখা যাক।
আপনি যুক্তি দিতে পারেন যে, এর সূচনা থেকেই, ভিডিও গেমগুলি এআই-তে আগ্রহী গবেষকদের জন্য গবেষণার একটি উত্তপ্ত ক্ষেত্র।
যদিও আদিতে কঠোরভাবে একটি ভিডিও গেম নয়, দাবা এআই-এর প্রাথমিক দিনগুলিতে একটি বড় ফোকাস ছিল। 1951 সালে, ডঃ ডিট্রিচ প্রিঞ্জ ফেরান্তি মার্ক 1 ডিজিটাল কম্পিউটার ব্যবহার করে একটি দাবা খেলার প্রোগ্রাম লিখেছিলেন। এটি সেই যুগে ফিরে এসেছিল যখন এই বিশাল কম্পিউটারগুলিকে কাগজের টেপ থেকে প্রোগ্রামগুলি পড়তে হত।

প্রোগ্রামটি নিজেই একটি সম্পূর্ণ দাবা এআই ছিল না। কম্পিউটারের সীমাবদ্ধতার কারণে, প্রিঞ্জ শুধুমাত্র এমন একটি প্রোগ্রাম তৈরি করতে পারে যা মেট-ইন-টু দাবা সমস্যা সমাধান করে। সাদা এবং কালো খেলোয়াড়দের জন্য প্রতিটি সম্ভাব্য পদক্ষেপ গণনা করতে প্রোগ্রামটি গড়ে 15-20 মিনিট সময় নেয়।
দাবা এবং চেকার AI উন্নত করার কাজটি কয়েক দশক ধরে ক্রমাগত উন্নতি করেছে। 1997 সালে আইবিএমের ডিপ ব্লু রাশিয়ান দাবা গ্র্যান্ডমাস্টার গ্যারি কাসপারভকে ছয়-গেমের ম্যাচে পরাজিত করার সময় এই অগ্রগতি চূড়ান্ত পর্যায়ে পৌঁছেছিল। আজকাল, আপনি আপনার মোবাইল ফোনে যে দাবা ইঞ্জিনগুলি খুঁজে পেতে পারেন তা ডিপ ব্লুকে পরাস্ত করতে পারে।
ভিডিও আর্কেড গেমের সুবর্ণ যুগে এআই বিরোধীরা জনপ্রিয়তা পেতে শুরু করে। 1978-এর মহাকাশ আক্রমণকারী এবং 1980-এর দশকের প্যাক-ম্যান হল AI তৈরির ক্ষেত্রে শিল্পের অগ্রগামীদের মধ্যে যারা এমনকি সবচেয়ে অভিজ্ঞ আর্কেড গেমারদেরও যথেষ্ট চ্যালেঞ্জ করতে পারে।
প্যাক-ম্যান, বিশেষত, এআই গবেষকদের পরীক্ষা করার জন্য একটি জনপ্রিয় খেলা ছিল। বিভিন্ন প্রতিযোগিতায় Ms. Pac-Man-এর জন্য কোন দল সেরা AI নিয়ে গেমটি হারাতে পারে তা নির্ধারণ করার জন্য আয়োজন করা হয়েছে।
গেম এআই এবং হিউরিস্টিক অ্যালগরিদমগুলি বিকশিত হতে থাকে যেহেতু স্মার্ট প্রতিপক্ষের প্রয়োজন দেখা দেয়। উদাহরণস্বরূপ, প্রথম-ব্যক্তি শ্যুটারদের মতো জেনারগুলি আরও মূলধারায় পরিণত হওয়ায় যুদ্ধ এআই জনপ্রিয়তা বৃদ্ধি পেয়েছে।
ভিডিও গেমে মেশিন লার্নিং
যেহেতু মেশিন লার্নিং কৌশল দ্রুত জনপ্রিয়তা পেয়েছে, বিভিন্ন গবেষণা প্রকল্প ভিডিও গেম খেলতে এই নতুন কৌশলগুলি ব্যবহার করার চেষ্টা করেছে।
ডোটা 2, স্টারক্রাফ্ট এবং ডুমের মতো গেমগুলি এইগুলির জন্য সমস্যা হিসাবে কাজ করতে পারে মেশিন লার্নিং অ্যালগরিদম সমাধান করা. গভীর শিক্ষার অ্যালগরিদম, বিশেষ করে, অর্জন করতে এবং এমনকি মানব-স্তরের কর্মক্ষমতা অতিক্রম করতে সক্ষম হয়েছিল।
সার্জারির আর্কেড লার্নিং এনভায়রনমেন্ট বা ALE গবেষকদের একশোর বেশি Atari 2600 গেমের জন্য একটি ইন্টারফেস দিয়েছে। ওপেন সোর্স প্ল্যাটফর্ম গবেষকদের ক্লাসিক আটারি ভিডিও গেমগুলিতে মেশিন লার্নিং কৌশলগুলির কার্যকারিতা বেঞ্চমার্ক করার অনুমতি দেয়। গুগল এমনকি তাদের নিজস্ব প্রকাশ করেছে কাগজ ALE থেকে সাতটি গেম ব্যবহার করে

এদিকে, প্রকল্পের মত ভিজডুম AI গবেষকদের 3D ফার্স্ট-পারসন শ্যুটার খেলতে মেশিন লার্নিং অ্যালগরিদম প্রশিক্ষণ দেওয়ার সুযোগ দিয়েছে।

এটি কিভাবে কাজ করে: কিছু মূল ধারণা
নিউরাল নেটওয়ার্ক
মেশিন লার্নিং দিয়ে ভিডিও গেমস সমাধানের বেশিরভাগ পদ্ধতির মধ্যে এক ধরনের অ্যালগরিদম জড়িত যা নিউরাল নেটওয়ার্ক নামে পরিচিত।
আপনি একটি নিউরাল নেটকে একটি প্রোগ্রাম হিসাবে ভাবতে পারেন যা একটি মস্তিষ্ক কীভাবে কাজ করতে পারে তা অনুকরণ করার চেষ্টা করে। আমাদের মস্তিষ্ক যেভাবে একটি সংকেত প্রেরণকারী নিউরন দ্বারা গঠিত, তেমনি একটি নিউরাল নেটেও কৃত্রিম নিউরন থাকে।
এই কৃত্রিম নিউরনগুলি একে অপরের কাছে সংকেত স্থানান্তর করে, প্রতিটি সংকেত একটি প্রকৃত সংখ্যা। একটি নিউরাল নেট ইনপুট এবং আউটপুট স্তরগুলির মধ্যে একাধিক স্তর ধারণ করে, যাকে একটি গভীর নিউরাল নেটওয়ার্ক বলা হয়।
শক্তিবৃদ্ধি শেখা
ভিডিও গেম শেখার জন্য প্রাসঙ্গিক আরেকটি সাধারণ মেশিন লার্নিং কৌশল হল রিইনফোর্সমেন্ট লার্নিং এর ধারণা।
এই কৌশলটি হল পুরস্কার বা শাস্তি ব্যবহার করে এজেন্টকে প্রশিক্ষণ দেওয়ার প্রক্রিয়া। এই পদ্ধতির সাথে, এজেন্টকে ট্রায়াল এবং ত্রুটির মাধ্যমে একটি সমস্যার সমাধান নিয়ে আসতে সক্ষম হওয়া উচিত।
ধরা যাক কিভাবে স্নেক গেমটি খেলতে হয় তা খুঁজে বের করার জন্য আমরা একটি AI চাই। গেমটির উদ্দেশ্য সহজ: আইটেমগুলি খেয়ে এবং আপনার ক্রমবর্ধমান লেজ এড়িয়ে যতটা সম্ভব পয়েন্ট পান।
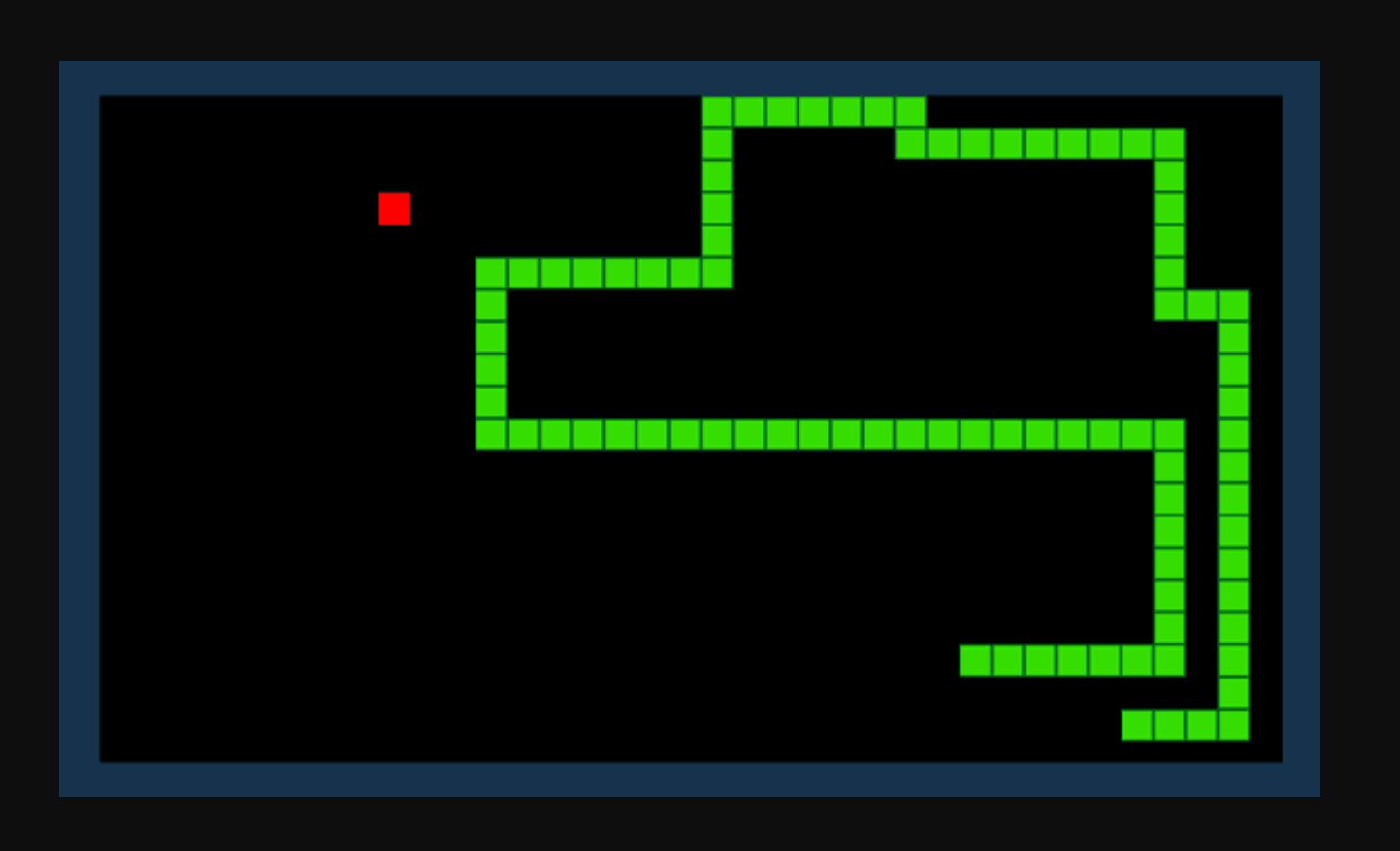
শক্তিবৃদ্ধি শেখার মাধ্যমে, আমরা একটি পুরষ্কার ফাংশন R সংজ্ঞায়িত করতে পারি। ফাংশনটি পয়েন্ট যোগ করে যখন একটি সাপ একটি আইটেম খায় এবং যখন সাপ একটি বাধাকে আঘাত করে তখন পয়েন্ট বাদ দেয়। বর্তমান পরিবেশ এবং সম্ভাব্য ক্রিয়াগুলির একটি সেটের পরিপ্রেক্ষিতে, আমাদের শক্তিবৃদ্ধি শেখার মডেলটি সর্বোত্তম 'নীতি' গণনা করার চেষ্টা করবে যা আমাদের পুরষ্কারের কার্যকারিতাকে সর্বাধিক করে তোলে।
নিউরোবিবর্তন
প্রকৃতির দ্বারা অনুপ্রাণিত হওয়ার সাথে থিমের মধ্যে রেখে, গবেষকরা নিউরোইভোলিউশন নামে পরিচিত একটি কৌশলের মাধ্যমে ভিডিও গেমগুলিতে এমএল প্রয়োগ করার ক্ষেত্রেও সাফল্য পেয়েছেন।
পরিবর্তে ব্যবহার গ্রেডিয়েন্ট বংশধর একটি নেটওয়ার্কে নিউরন আপডেট করতে, আমরা আরও ভাল ফলাফল অর্জনের জন্য বিবর্তনীয় অ্যালগরিদম ব্যবহার করতে পারি।
বিবর্তনীয় অ্যালগরিদমগুলি সাধারণত এলোমেলো ব্যক্তিদের প্রাথমিক জনসংখ্যা তৈরি করে শুরু হয়। তারপরে আমরা নির্দিষ্ট মানদণ্ড ব্যবহার করে এই ব্যক্তিদের মূল্যায়ন করি। সেরা ব্যক্তিদের "পিতামাতা" হিসাবে বেছে নেওয়া হয় এবং একটি নতুন প্রজন্মের ব্যক্তি গঠনের জন্য একসাথে বংশবৃদ্ধি করা হয়। এই ব্যক্তিরা জনসংখ্যার মধ্যে সবচেয়ে কম উপযুক্ত ব্যক্তিদের প্রতিস্থাপন করবে।
এই অ্যালগরিদমগুলি সাধারণত জিনগত বৈচিত্র্য বজায় রাখার জন্য ক্রসওভার বা "প্রজনন" পদক্ষেপের সময় মিউটেশন অপারেশনের কিছু রূপ প্রবর্তন করে।
ভিডিও গেমে মেশিন লার্নিং এর নমুনা গবেষণা
OpenAI ফাইভ

OpenAI ফাইভ ওপেনএআই-এর একটি কম্পিউটার প্রোগ্রাম যার লক্ষ্য DOTA 2, একটি জনপ্রিয় মাল্টিপ্লেয়ার মোবাইল ব্যাটল অ্যারেনা (MOBA) গেম খেলা।
প্রোগ্রামটি বিদ্যমান শক্তিবৃদ্ধি শেখার কৌশলগুলিকে কাজে লাগিয়েছে, প্রতি সেকেন্ডে লক্ষ লক্ষ ফ্রেম থেকে শিখতে স্কেল করা হয়েছে। একটি বিতরণকৃত প্রশিক্ষণ ব্যবস্থার জন্য ধন্যবাদ, OpenAI প্রতিদিন 180 বছরের মূল্যের গেম খেলতে সক্ষম হয়েছিল।
প্রশিক্ষণের পর ওপেনএআই ফাইভ বিশেষজ্ঞ পর্যায়ের কর্মক্ষমতা অর্জন করতে এবং মানব খেলোয়াড়দের সাথে সহযোগিতা প্রদর্শন করতে সক্ষম হয়। 2019 সালে, OpenAI ফাইভ করতে সক্ষম হয়েছিল পরাজয় পাবলিক ম্যাচে 99.4% খেলোয়াড়।
কেন ওপেনএআই এই গেমের সিদ্ধান্ত নিয়েছে? গবেষকদের মতে, DOTA 2 এর জটিল মেকানিক্স ছিল যা বিদ্যমান গভীরের নাগালের বাইরে ছিল শক্তিবৃদ্ধি শেখার আলগোরিদিম।
সুপার মারিও BROS.
ভিডিও গেমগুলিতে নিউরাল নেটগুলির আরেকটি আকর্ষণীয় প্রয়োগ হল সুপার মারিও ব্রোস-এর মতো প্ল্যাটফর্মে খেলতে নিউরোইভোলিউশনের ব্যবহার।
উদাহরণস্বরূপ, এটি হ্যাকাথন এন্ট্রি খেলার কোন জ্ঞান না থাকা দিয়ে শুরু হয় এবং ধীরে ধীরে একটি স্তরের মাধ্যমে অগ্রগতির জন্য যা প্রয়োজন তার একটি ভিত্তি তৈরি করে।
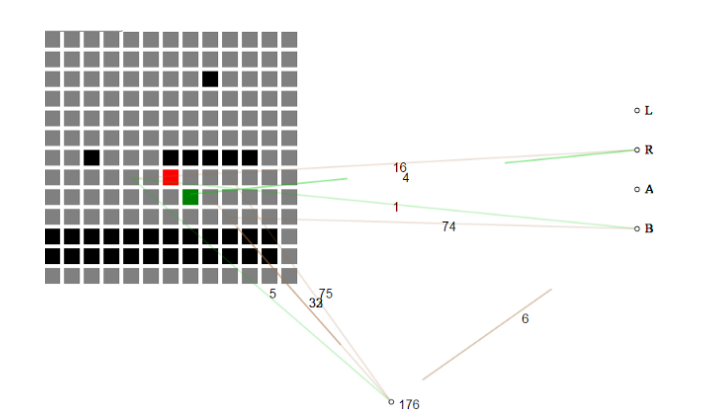
স্ব-বিকশিত নিউরাল নেট গেমের বর্তমান অবস্থায় টাইলসের গ্রিড হিসাবে গ্রহণ করে। প্রথমে, নিউরাল নেট প্রতিটি টাইলের অর্থ কী তা বুঝতে পারে না, শুধুমাত্র "এয়ার" টাইলগুলি "গ্রাউন্ড টাইলস" এবং "শত্রু টাইলস" থেকে আলাদা।
হ্যাকাথন প্রকল্পের একটি নিউরোইভোলিউশন বাস্তবায়নের জন্য NEAT জেনেটিক অ্যালগরিদম ব্যবহার করে বেছে বেছে বিভিন্ন নিউরাল জালের প্রজনন করা হয়েছে।
গুরুত্ব
এখন আপনি ভিডিও গেম খেলার নিউরাল নেটগুলির কিছু উদাহরণ দেখেছেন, আপনি হয়তো ভাবছেন এই সবের উদ্দেশ্য কী।
যেহেতু ভিডিও গেমগুলি এজেন্ট এবং তাদের পরিবেশের মধ্যে জটিল মিথস্ক্রিয়া জড়িত, তাই এটি এআই তৈরির জন্য নিখুঁত পরীক্ষার স্থল। ভার্চুয়াল পরিবেশ নিরাপদ এবং নিয়ন্ত্রণযোগ্য এবং ডেটার অসীম সরবরাহ প্রদান করে।
এই ক্ষেত্রে করা গবেষণা গবেষকদের অন্তর্দৃষ্টি দিয়েছে যে কীভাবে স্নায়ু জাল অপ্টিমাইজ করা যায় তা শিখতে কিভাবে বাস্তব জগতে সমস্যা সমাধান করা যায়।
নিউরাল নেটওয়ার্ক প্রাকৃতিক বিশ্বে মস্তিষ্ক কীভাবে কাজ করে তা দ্বারা অনুপ্রাণিত হয়। একটি ভিডিও গেম কীভাবে খেলতে হয় তা শেখার সময় কৃত্রিম নিউরনগুলি কীভাবে আচরণ করে তা অধ্যয়ন করে, আমরা কীভাবে সে সম্পর্কে অন্তর্দৃষ্টি অর্জন করতে পারি মানুষের মস্তিষ্ক কাজ করে।
উপসংহার
নিউরাল নেটওয়ার্ক এবং মস্তিষ্কের মধ্যে মিল উভয় ক্ষেত্রেই অন্তর্দৃষ্টির দিকে পরিচালিত করেছে। কীভাবে নিউরাল নেট সমস্যাগুলি সমাধান করতে পারে সে সম্পর্কে ক্রমাগত গবেষণা একদিন আরও উন্নত ফর্মের দিকে নিয়ে যেতে পারে কৃত্রিম বুদ্ধিমত্তা.
আপনার স্পেসিফিকেশন অনুসারে তৈরি একটি AI ব্যবহার করে কল্পনা করুন যা কেনার আগে একটি সম্পূর্ণ ভিডিও গেম খেলতে পারে যাতে এটি আপনার সময়ের মূল্য আছে কিনা তা জানাতে। ভিডিও গেম কোম্পানিগুলি কি গেম ডিজাইন, টুইক লেভেল এবং প্রতিপক্ষের অসুবিধা উন্নত করতে নিউরাল নেট ব্যবহার করবে?
আপনি কি মনে করেন যখন নিউরাল নেট চূড়ান্ত গেমার হয়ে উঠবে?





নির্দেশিকা সমন্ধে মতামত দিন