У сучасным грамадстве, якое кіруецца дадзенымі, вэб-скрапінг стаў найважнейшым метадам атрымання праніклівых даных з інтэрнэт-платформаў.
Будучы надзвычай папулярным сайтам у сацыяльных сетках, Instagram змяшчае шмат матэрыялаў, створаных карыстальнікамі. І гэтыя згенераваныя даныя можна выкарыстоўваць для маркетынгу, даследаванняў і іншых мэтаў.
Карыстальнікі могуць лёгка і эфектыўна здабываць даныя з Instagram дзякуючы шматфункцыянальным скрабкам Instagram Bright Data, вядучым вэб-соскоб інструмент. У гэтай публікацыі мы дамо дбайнае, пакрокавае інструкцыю па працэсе скрабінгу Instagram.
Такім чынам, давайце паглядзім, як мы можам сабраць даныя з Instagram.
Разуменне скрабкоў Instagram ад Bright Data
З дапамогай двух універсальных вэб-скрабкоў і папярэдне скампіляванага набору даных Bright Data прадастаўляе разнастайныя сэрвісы скрабінгу Instagram. Гэтыя тэхналогіі забяспечваюць універсальнасць здабывання даных і адаптуюцца да розных патрабаванняў.
Давайце разгледзім кожны з гэтых варыянтаў больш падрабязна:
a. Скрабаванне браўзэра
Інавацыйная тэхналогія, вядомая як Scraping Browser, была створана для выканання патрабаванняў праектаў па збору даных. Ён прапануе ўсё неабходнае для скрабавання ў маштабе ўнутры аднаго браўзера. Ён вылучаецца дзякуючы інтэграванай аўтаматызацыі разблакіроўкі вэб-сайтаў, што робіць яго адзіным браўзерам такога роду ва ўсім свеце.
Scraping Browser дае карыстальнікам доступ да надзейных функцый, якія выходзяць за рамкі аўтаматызаваных браўзераў без галавы, дазваляючы ім выйсці за межы нават самых складаных сцэнарыяў і бар'ераў вэб-сайтаў для выяўлення ботаў.
Скрабаванне даных больш эфектыўнае і бесклапотнае дзякуючы функцыям аўтаматызаванай налады, якія лёгка кіруюць новымі блокамі, рашэннямі CAPTCHA, адбіткамі пальцаў і паўторнымі спробамі і выглядаюць як сапраўдны карыстальнік.
Выкарыстанне штучнага інтэлекту, каб перахітрыць сістэмы выяўлення ботаў
Выкарыстоўваючы перадавую тэхналогію штучнага інтэлекту, Scraping Browser можа перахітрыць сістэмы выяўлення ботаў і пастаянна падладжвацца пад іх зменлівыя стратэгіі. Каб лепш разблакіраваць вэб-старонкі, Scraping Browser вучыцца на спробах гэтых сістэм выяўляць і блакіраваць спробы скрабавання і адпаведным чынам змяняе свае паводзіны.
Ён пераўзыходзіць эфектыўнасць звычайных проксі-сервераў, імітуючы паводзіны браўзера, якім карыстаецца рэальны карыстальнік. У выніку кліенты могуць засяродзіцца на сваіх мэтах па збору даных без неабходнасці сутыкацца з цяжкасцямі і выдаткамі на бягучыя працэдуры выяўлення ботаў.
b. IDE вэб-скрабка
Надзейны інструмент скрабінгу, створаны для распрацоўшчыкаў, Web Scraper IDE можа апрацоўваць складаныя задачы скрабінгу. Гэта значна скарачае час распрацоўкі, адначасова забяспечваючы бясконцую маштабаванасць дзякуючы цалкам размешчанаму рашэнню і загадзя ўбудаваным функцыям скрабавання. Прыкладанне забяспечвае хуткае і маштабаванае стварэнне інтэрнэт-скрабкоў, падаючы шаблоны кода і гатовыя функцыі JavaScript з папулярных вэб-сайтаў.
Усё неабходнае для паспяховага вэб-скрабання забяспечваецца IDE Web Scraper. Гэта поўнае рашэнне для вымання даных у інтэрнэце, паколькі варыянты інтэграцыі дазваляюць кліентам планаваць сканаванне або запускаць іх праз API і звязваць з асноўнымі сістэмамі захоўвання дадзеных.
Як ім карыстацца? – Падручнік
Спачатку перайдзіце на прыборную панэль карыстальніка на сайце.

Давайце пачнем з нашых крокаў, каб саскрабаць Instagram.
1- Перайдзіце да прыборная панэль і націсніце на раздзел Datasets & Web Scraper IDE.
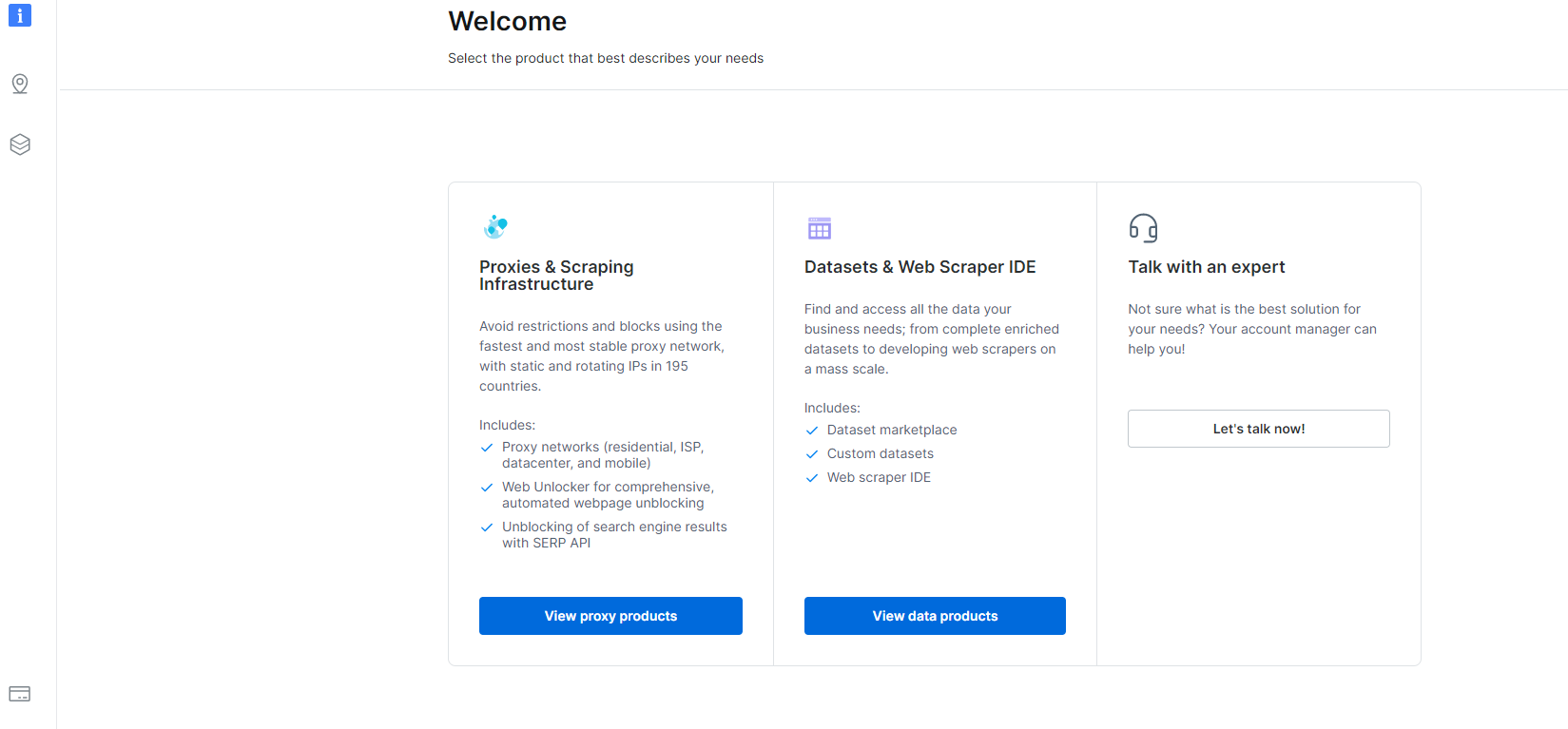
2- Апынуўшыся там, націсніце Мае скрабкі.
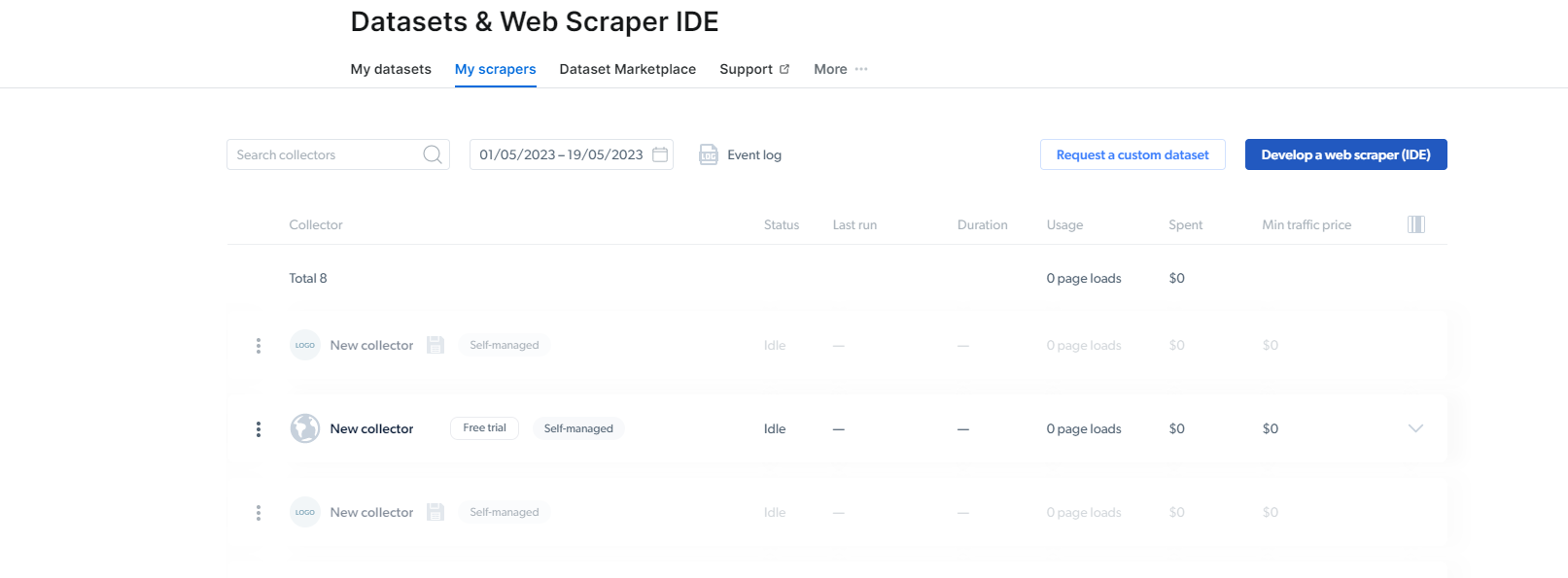
Тут вам трэба націснуць «Распрацаваць вэб-скрабок (IDE)». Тут мы створым наш скрабок для Instagram.
3-Цяпер нам трэба распрацаваць новы вэб-скрабок. Толькі для гэтага прыкладу я выбраў ачыстку ўліковага запісу «NASA». Гэта проста дзеля гэтага прыкладу.
Такім чынам, мой код будзе выглядаць так:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Вам трэба націснуць кнопку «прайграць» уверсе справа, каб запусціць гэты код.
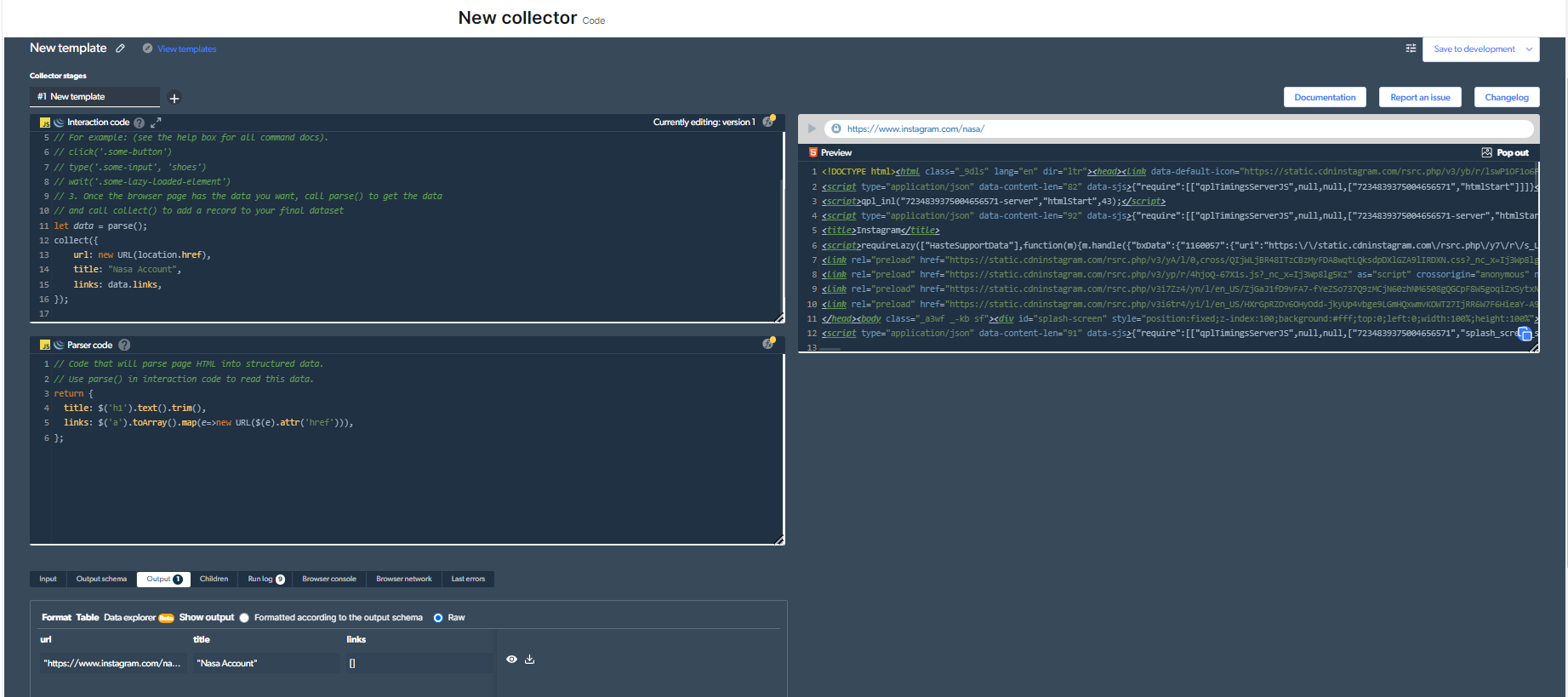
4- Зараз у нас будзе вынік.
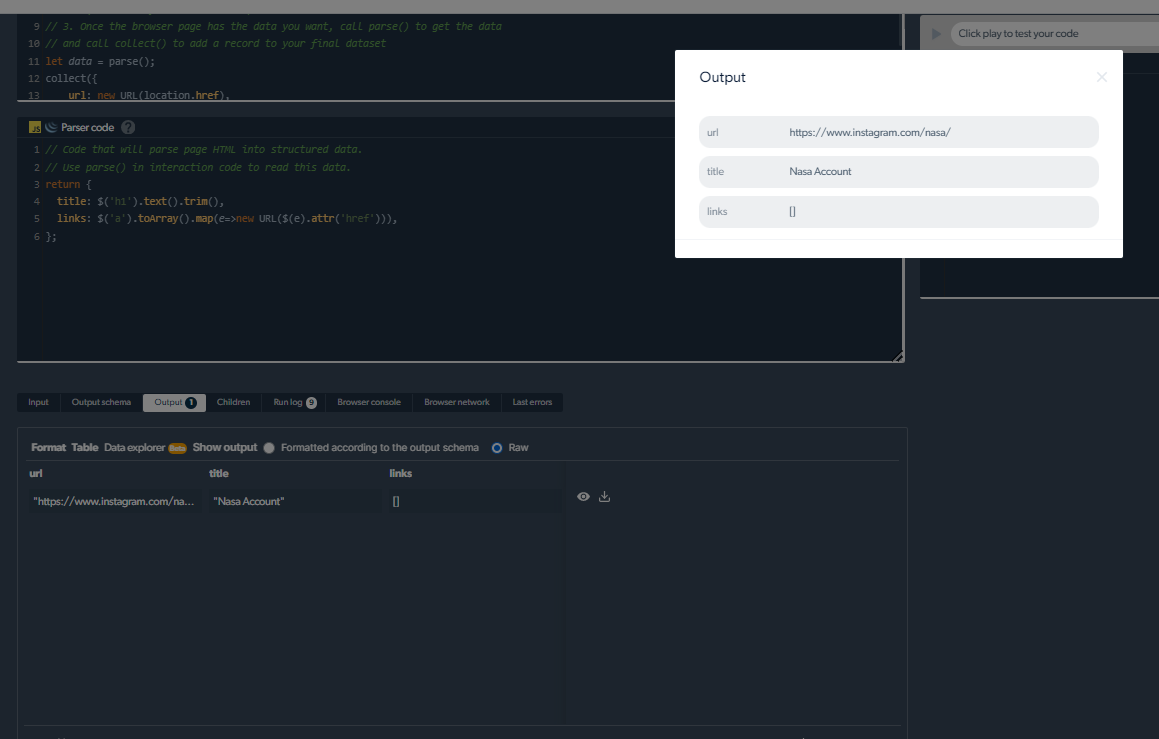
Кіраванне праблемамі выскрабання
Публікацыі ў Instagram з кнопкай «паказаць больш» можа быць цяжка захапіць скрабкам. Аднак скрабкі Instagram ад Bright Data створаны для таго, каб паспяхова справіцца з такой складанасцю. Гэтыя скрабкі валодаюць перадавымі навыкамі праходжання пагінацыі і загрузкі дадатковых кнопак.
Скрэперы Instagram ад Bright Data эфектыўна спраўляюцца з гэтымі цяжкасцямі, каб забяспечыць дбайнае выманне даных, дазваляючы вам сабраць усю калекцыю інфармацыі, неабходнай для аналізу або даследавання.
Вы можаце абыйсці праблемы, звязаныя з дынамічнай прыродай паведамленняў у Instagram, выкарыстоўваючы гэтыя інструменты скрабка.
c. Папярэдне сабраны набор даных
Bright Data разумее, што не кожны хоча запускаць свой скраб. Яны пастаўляюць загадзя сабраныя дадзеныя для Instagram, каб прывабіць такіх спажыўцоў.
Гэты набор даных прапануе мноства карыснай інфармацыі, такой як падпісчыкі, профілі, паведамленні і г.д.
Bright Data прапануе параметры наладкі для персаналізацыі набору даных у адпаведнасці з вашымі патрэбамі, незалежна ад таго, хочаце вы цэлы набор даных або падмноства спецыялізаваных даных. Гэты падыход дазваляе пазбегнуць стварэння скрабка і кіравання ім, даючы вам гатовыя да выкарыстання даныя для аналізу і разумення.
Зараз давайце праверым інфраструктуру, якая робіць гэтыя інструменты настолькі эфектыўнымі: інфраструктуру проксі і Web Unlocker.
Дайце волю моцы проксі
Выкарыстанне проксі мае вырашальнае значэнне падчас вэб-скрабання, каб гарантаваць, што вашы дзеянні застануцца незаўважанымі.
Bright Data прапануе шырокі выбар проксі-сэрвісы якія настроены ў адпаведнасці з вашымі патрабаваннямі. Вы можаце выбраць з Жылыя давераныя асобы, якія прапануюць больш за 72 мільёны IP-адрасоў, перададзеных з рэальных аднарангавых прылад у 195 краінах.
Вы можаце выбраць проксі-серверы ISP, якія прапануюць больш за 700,000 770,000 рэальных хатніх IP-адрасоў па ўсім свеце для доўгатэрміновага выкарыстання; Проксі цэнтраў апрацоўкі дадзеных, якія маюць 3 4+ агульных IP-адрасоў з любой геалакацыі; і мабільныя проксі-серверы, якія ўтвараюць найбуйнейшую мабільную сетку 7,000,000G/XNUMXG з рэальнымі партнёрамі з больш чым XNUMX XNUMX XNUMX IP.
З дапамогай гэтых проксі можна лёгка збіраць дадзеныя, выдаючы сябе за аўтарызаванага карыстальніка ў многіх месцах.

Менеджэр проксі: палягчае кіраванне проксі
Кіраванне некалькімі проксі можа быць цяжкім, але Proxy Manager робіць гэта простым.
Гэты інтэрфейс з адкрытым зыходным кодам дазваляе вам кіраваць усімі вашымі проксі з адной платформы. Развітайцеся з ручной наладай і пераключэннем проксі. Proxy Manager спрашчае працэдуру і эканоміць ваш час і намаганні.
Пашырэнне проксі-браўзера: лёгка змяніце сваё месцазнаходжанне
Вам трэба збіраць вэб-дадзеныя з некалькіх рэгіёнаў? Вы ахоплены нашым пашырэннем проксі-браўзера. Вы можаце змяніць месцазнаходжанне прагляду адным пстрычкай мышы, каб атрымаць інфармацыю па рэгіёне.
Скарыстайцеся перавагамі гнуткасці і прастаты збору даных з некалькіх рэгіёнаў без якіх-небудзь тэхналагічных ускладненняў.
Як гэта працуе? – Падручнік
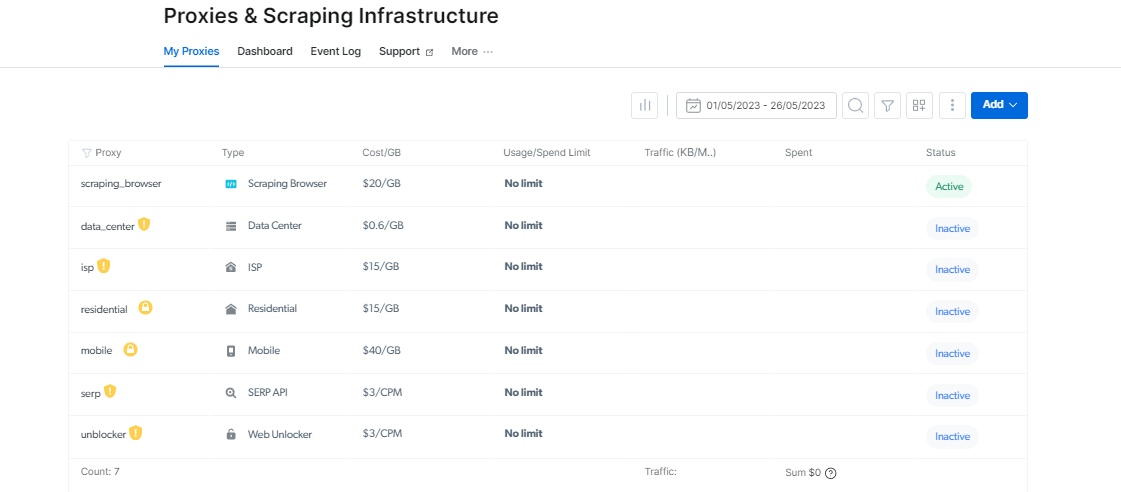
Вы можаце знайсці свой Скрабаванне браўзэра інфармацыя для ўваходу на старонцы параметраў доступу, якая будзе выкарыстоўвацца пры запуску новай сесіі браўзера.
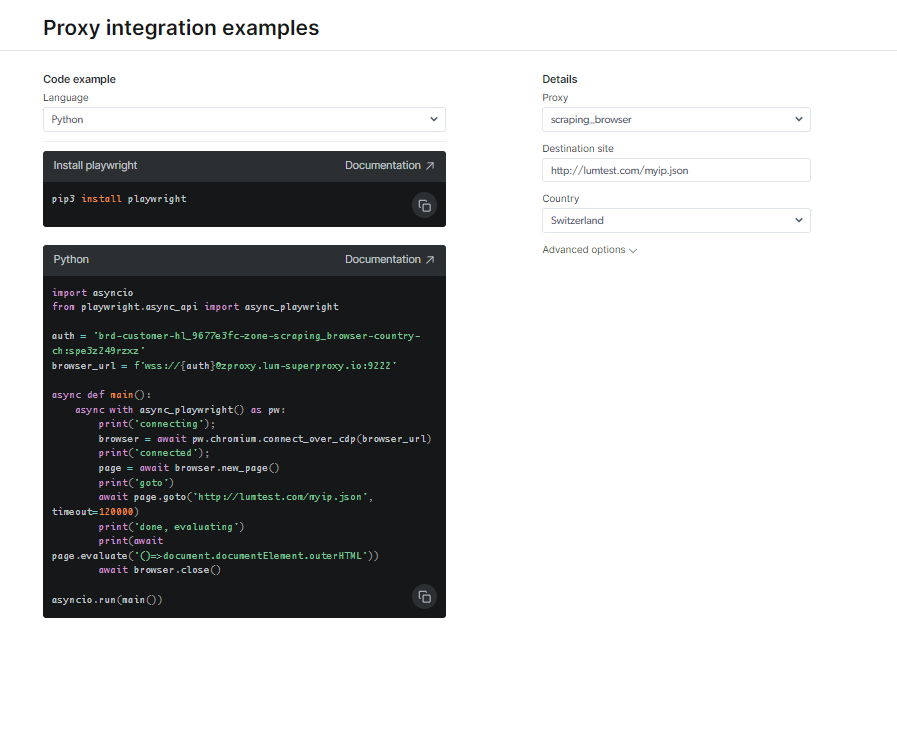
Праверце дакументацыю і ўзоры кода, у тым ліку поўнафункцыянальны прыклад сцэнарыя, гатовы да выкарыстання, або паглядзіце кароткае відэа з інструкцыямі па запуску. Напрыклад; вось а Код Python прыклад інтэграцыі:
Хочаце дапамогі? Для размовы з адным са спецыялістаў вы можаце націснуць на значок чата.
Майце на ўвазе, што вы цалкам кантралюеце сеансы браўзера пры выкарыстанні Scraping Browser і можаце выконваць любыя аперацыі, якія падтрымліваюцца Puppeteer, Playwright або непасрэдна выкарыстоўваць пратакол Chrome DevTools.
Разблакіроўка сайта без блакіроўкі
Scraping Browser створаны для працы ў маштабе і па меры неабходнасці. Вам не трэба турбавацца аб тым, што вас забаняць; вы можаце запускаць колькі заўгодна сеансаў браўзера.
Гэтая ёмістасць у спалучэнні з магутнасцю проксі-сервераў гарантуе бесперапынны збор даных, дазваляючы вам эфектыўна атрымліваць патрэбныя даныя.
Убудаваныя навыкі разблакіроўкі Scraping Browser і надзейная проксі-сетка дапамогуць вам зэканоміць час, павысіць прадукцыйнасць і адкрыць новыя магчымасці.
Вы таксама можаце праверыць статыстыку непасрэдна з гэтай жа старонкі.
Кошт Scraping Browser
Bright Data забяспечвае наладжвальны выбар цэн для задавальнення розных мэтаў. Вы можаце выбраць месячны або гадавы разліковы перыяд.
Параметр Pay as You Go дазваляе вам плаціць толькі за тое, што вы выкарыстоўваеце, без абавязацельстваў, пачынаючы з $20.00/ГБ і $0.1/гадзіну.
План росту ў памеры 500 долараў ЗША падыходзіць для прадпрыемстваў, якія развіваюцца, са зніжкай у 15.30 долараў за ГБ і 0.1 долара за гадзіну.
,en Бізнес пакет, які каштуе 1000 долараў, з'яўляецца самым папулярным варыянтам, а API браўзера Scraping каштуе 13.50 долараў за ГБ і 0.1 долараў за гадзіну.
Звяртаючыся непасрэдна да каманды Bright Data, карпаратыўныя карыстальнікі могуць карыстацца бясконцым маштабаваннем і персаналізаванай цаной. Пачніце бясплатную пробную версію сёння, каб адкрыць для сябе патэнцыял Scraping Browser ад Bright Data і змяніць свае спробы сканіравання ў Інтэрнэце.
Разблакіроўка сайтаў
Web Unlocker - гэта магутны інструмент, створаны, каб выйсці за рамкі абмежаванняў вэб-сайтаў і забяспечыць лёгкі збор даных. Ён пераадольвае некалькі праблем, у тым ліку файлы cookie, карыстальніцкія агенты для канкрэтных сайтаў і рашэнні captcha, выкарыстоўваючы аўтаматызаваныя працэдуры.
Выкарыстоўваючы аўтаматычную ратацыю IP-адрасоў, карыстальнікі Web Unlocker могуць пастаянна сканаваць мэтавыя вэб-сайты, забяспечваючы пастаянны доступ да важных даных.
Паляпшэнне маршрутаў па запытах распрацоўшчыкаў
Некаторыя функцыі робяць Web Unlocker папулярным сярод распрацоўшчыкаў. Праграма аптымізуе працэс збору даных, аўтаматычна вызначаючы карыстальніцкія агенты, неабходныя для кожнага вэб-сайта, эканомячы каштоўны час і рэсурсы.
Web Unlocker адаптуецца ў рэжыме рэальнага часу, каб пазбегнуць выяўлення ў адказ на пастаянна змяняюцца стратэгіі, якія выкарыстоўваюцца блакіруючымі ботамі, забяспечваючы пастаянны доступ да цікавых вэб-сайтаў. Алгарытмы машыннага навучання платформы могуць хутка вырашаць капчу, якая з'яўляецца частай перашкодай для ініцыятыў па зборы даных.

Цэны на Web Unlocker
Пачынаючы з прыкладна $2.03 за тысячу запытаў (CPM), Web Unlocker прапануе некалькі варыянтаў цэн для задавальнення розных патрабаванняў. Карыстальнікам даступная 7-дзённая бясплатная пробная версія, якая дапаможа ім пачаць працу і дазволіць ім праверыць функцыі Web Unlocker, перш чым прыступіць да выканання.
Web Unlocker мае магчымасць адаптацыі для падтрымкі розных мадэляў выкарыстання, незалежна ад таго, жадаюць спажыўцы аплату па меры выкарыстання або патрэбны індывідуальны план, які адпавядае іх канкрэтным патрабаванням. Акрамя таго, тыя, хто выбірае доўгатэрміновыя цэнавыя планы, могуць зэканоміць 32%.
Параўнанне Web Unlocker з самакіраванымі проксі
Web Unlocker прапануе мноства імгненных пераваг у параўнанні з самакіраванымі проксі. Для бесперабойнай рэалізацыі ён прапануе шырокую тэхніку інтэграцыі, якая спалучае ў сабе функцыі суперпроксі і менеджэр проксі. Карыстальнікі могуць эфектыўна пашыраць свае аперацыі па зборы даных з дапамогай бясконцай колькасці адначасовых злучэнняў.
Web Unlocker забяспечвае аўтаматычную разблакіроўку, вырашае CAPTCHA і паспяхова кіруе мадыфікацыямі разметкі на мэтавых сайтах.
Платформа гарантуе бесперапыннае і надзейнае выманне дадзеных шляхам укаранення сістэмы аўтаматычнага паўтору і асінхронных выклікаў для пэўных даменаў. Акрамя таго, растучая калекцыя запытаў HTTP-загалоўкаў у сетцы Unlocker, файлаў cookie для канкрэтных сайтаў і імітаваных гаджэтаў дазваляе карыстальнікам заставацца незаўважанымі, адначасова дазваляючы ім атрымліваць онлайн-дадзеныя ў рэжыме рэальнага часу.
Апошнія думкі і важныя рэчы, якія трэба памятаць
Нарэшце, пры выкарыстанні Bright Data для скрэпінгу ў Instagram важна мець на ўвазе некалькі важных момантаў.
Калі ласка, звярніце ўвагу, што іх магчымасці сканіравання абмежаваныя агульнадаступнымі дадзенымі ў адпаведнасці з этычнымі правіламі.
Вы заўсёды павінны прытрымлівацца ўмоў абслугоўвання і палітыкі прыватнасці Instagram. Скрабаванне павінна праводзіцца этычна і адказна, без парушэння правоў карыстальнікаў і законаў.
Па-другое, рэгулярна абнаўляйце і наладжвайце параметры сканіравання, каб гарантаваць дакладнасць і рэлевантнасць атрыманых даных. Платформа і алгарытмы Instagram могуць змяняцца, таму вы павінны адпаведным чынам змяніць свае стратэгіі сканіравання.
І, нарэшце, скарыстайцеся дапамогай і рэсурсамі платформы Bright Data, каб аптымізаваць поспех вашых намаганняў па скрапінгу ў Instagram. Звяртайцеся да іх дакументацыі, падручнікаў і абслугоўвання кліентаў, каб палепшыць свае веды аб іх інструментах для выскрабання.
Вы можаце атрымаць карысную інфармацыю, паўплываць на прыняцце мудрых рашэнняў і дамагчыся поспеху ў сваіх ініцыятывах, якія кіруюцца дадзенымі, на платформе Instagram, прытрымліваючыся гэтых перадавых практык і выкарыстоўваючы магчымасці Bright Data для сканіравання ў Instagram.





Пакінуць каментар