Video oyunlar dünyada milyardlarla oyunçuya problem yaratmağa davam edir. Siz hələ bunu bilmirsiniz, amma maşın öyrənmə alqoritmləri də problemə qarşı çıxmağa başlayıb.
Hazırda süni intellekt sahəsində maşın öyrənmə üsullarının video oyunlarda tətbiq oluna biləcəyini görmək üçün əhəmiyyətli miqdarda araşdırma aparılır. Bu sahədə ciddi irəliləyişlər bunu göstərir maşın təlim agentlər insan oyunçunu təqlid etmək və ya hətta əvəz etmək üçün istifadə edilə bilər.
Bunun gələcəyi üçün nə deməkdir video oyun?
Bu layihələr sadəcə əyləncə üçündür, yoxsa bir çox tədqiqatçının oyunlara diqqət yetirməsinin daha dərin səbəbləri varmı?
Bu məqalə video oyunlarda süni intellekt tarixini qısaca araşdıracaq. Daha sonra sizə oyunları məğlub etməyi öyrənmək üçün istifadə edə biləcəyimiz bəzi maşın öyrənmə üsulları haqqında qısa məlumat verəcəyik. Daha sonra bəzi uğurlu tətbiqlərə baxacağıq sinir şəbəkələri xüsusi video oyunları öyrənmək və mənimsəmək.
Oyunda AI-nin qısa tarixi
Neyron şəbəkələrinin niyə video oyunları həll etmək üçün ideal alqoritmə çevrildiyini başa düşməzdən əvvəl, kompüter alimlərinin süni intellekt sahəsində tədqiqatlarını inkişaf etdirmək üçün video oyunlardan necə istifadə etdiklərinə qısaca nəzər salaq.
Siz iddia edə bilərsiniz ki, yarandığı gündən video oyunları AI ilə maraqlanan tədqiqatçılar üçün isti tədqiqat sahəsi olmuşdur.
Mənşəcə ciddi bir video oyunu olmasa da, AI-nin ilk günlərində şahmat böyük diqqət mərkəzində olmuşdur. 1951-ci ildə doktor Ditrix Prinz Ferranti Mark 1 rəqəmsal kompüterindən istifadə edərək şahmat proqramı yazdı. Bu, bu həcmli kompüterlərin proqramları kağız lentdən oxumaq məcburiyyətində qaldığı dövrdə idi.

Proqramın özü tam şahmat AI deyildi. Kompüterin məhdudiyyətləri səbəbindən Prinz yalnız şahmatla bağlı problemləri həll edən bir proqram yarada bildi. Ağ və Qara oyunçular üçün hər bir mümkün hərəkəti hesablamaq üçün proqram orta hesabla 15-20 dəqiqə çəkdi.
Şahmat və dama süni intellektinin təkmilləşdirilməsi üzərində aparılan işlər onilliklər ərzində davamlı olaraq təkmilləşmişdir. Tərəqqi 1997-ci ildə IBM-in Deep Blue şirkəti altı oyunluq cütlükdə rus şahmat qrossmeysteri Qarri Kasparovu məğlub edəndə kulminasiya nöqtəsinə çatdı. Hazırda mobil telefonunuzda tapa biləcəyiniz şahmat mühərrikləri Deep Blue-nu məğlub edə bilir.
AI rəqibləri video arcade oyunlarının qızıl dövründə populyarlıq qazanmağa başladı. 1978-ci illərin Kosmos İşğalçıları və 1980-ci illərin Pac-Manları, hətta ən arcade oyunçularına kifayət qədər meydan oxuya bilən süni intellekt yaratmaqda sənayenin qabaqcıllarından bəziləridir.
Xüsusilə Pac-Man, süni intellekt tədqiqatçılarının sınaqdan keçirməsi üçün məşhur bir oyun idi. Müxtəlif müsabiqələr Xanım Pac-Man üçün hansı komandanın oyunu məğlub etmək üçün ən yaxşı süni intellektlə çıxış edə biləcəyini müəyyən etmək üçün təşkil edilmişdir.
Daha ağıllı rəqiblərə ehtiyac yarandıqca oyun AI və evristik alqoritmlər inkişaf etməyə davam etdi. Məsələn, birinci şəxs atıcıları kimi janrlar daha çox populyarlaşdıqca döyüş süni intellekt populyarlıq qazandı.
Video Oyunlarda Maşın Öyrənmə
Maşın öyrənmə üsulları sürətlə populyarlaşdıqca, müxtəlif tədqiqat layihələri video oyunları oynamaq üçün bu yeni üsullardan istifadə etməyə çalışdı.
Dota 2, StarCraft və Doom kimi oyunlar bunlar üçün problem ola bilər maşın öyrənmə alqoritmləri həll etmək. Dərin öyrənmə alqoritmləri, xüsusilə, insan səviyyəsindəki performansa nail ola bilmiş və hətta ondan da üstün olmuşdur.
The Arkada Öyrənmə Mühiti və ya ALE tədqiqatçılara yüzdən çox Atari 2600 oyunu üçün interfeys verdi. Açıq mənbə platforması tədqiqatçılara klassik Atari video oyunlarında maşın öyrənmə üsullarının performansını müqayisə etməyə imkan verdi. Google hətta özlərini nəşr etdi kağız ALE-dən yeddi oyundan istifadə edir

Bu arada kimi layihələr VizDoom AI tədqiqatçılarına 3D birinci şəxs atıcılarını oynamaq üçün maşın öyrənmə alqoritmlərini öyrətmək imkanı verdi.

Necə işləyir: bəzi əsas anlayışlar
Sinir şəbəkələri
Maşın öyrənməsi ilə video oyunların həllinə yanaşmaların əksəriyyəti neyron şəbəkəsi kimi tanınan bir növ alqoritmi əhatə edir.
Neyron şəbəkəsini beynin necə işlədiyini təqlid etməyə çalışan bir proqram kimi düşünə bilərsiniz. Beynimiz siqnal ötürən neyronlardan ibarət olduğu kimi, sinir şəbəkəsi də süni neyronları ehtiva edir.
Bu süni neyronlar da siqnalları bir-birinə ötürür, hər bir siqnal faktiki rəqəmdir. Neyron şəbəkəsi dərin neyron şəbəkəsi adlanan giriş və çıxış təbəqələri arasında çoxlu təbəqədən ibarətdir.
Armatur öyrənmə
Video oyunlarını öyrənməklə əlaqəli başqa bir ümumi maşın öyrənmə texnikası gücləndirici öyrənmə ideyasıdır.
Bu texnika agentin mükafat və ya cəzalardan istifadə edərək öyrədilməsi prosesidir. Bu yanaşma ilə agent sınaq və səhv yolu ilə problemin həllini tapmalıdır.
Deyək ki, biz Snake oyununu necə oynayacağımızı öyrənmək üçün AI istəyirik. Oyunun məqsədi sadədir: əşyaları istehlak edərək və böyüyən quyruğunuzdan qaçaraq mümkün qədər çox xal əldə edin.
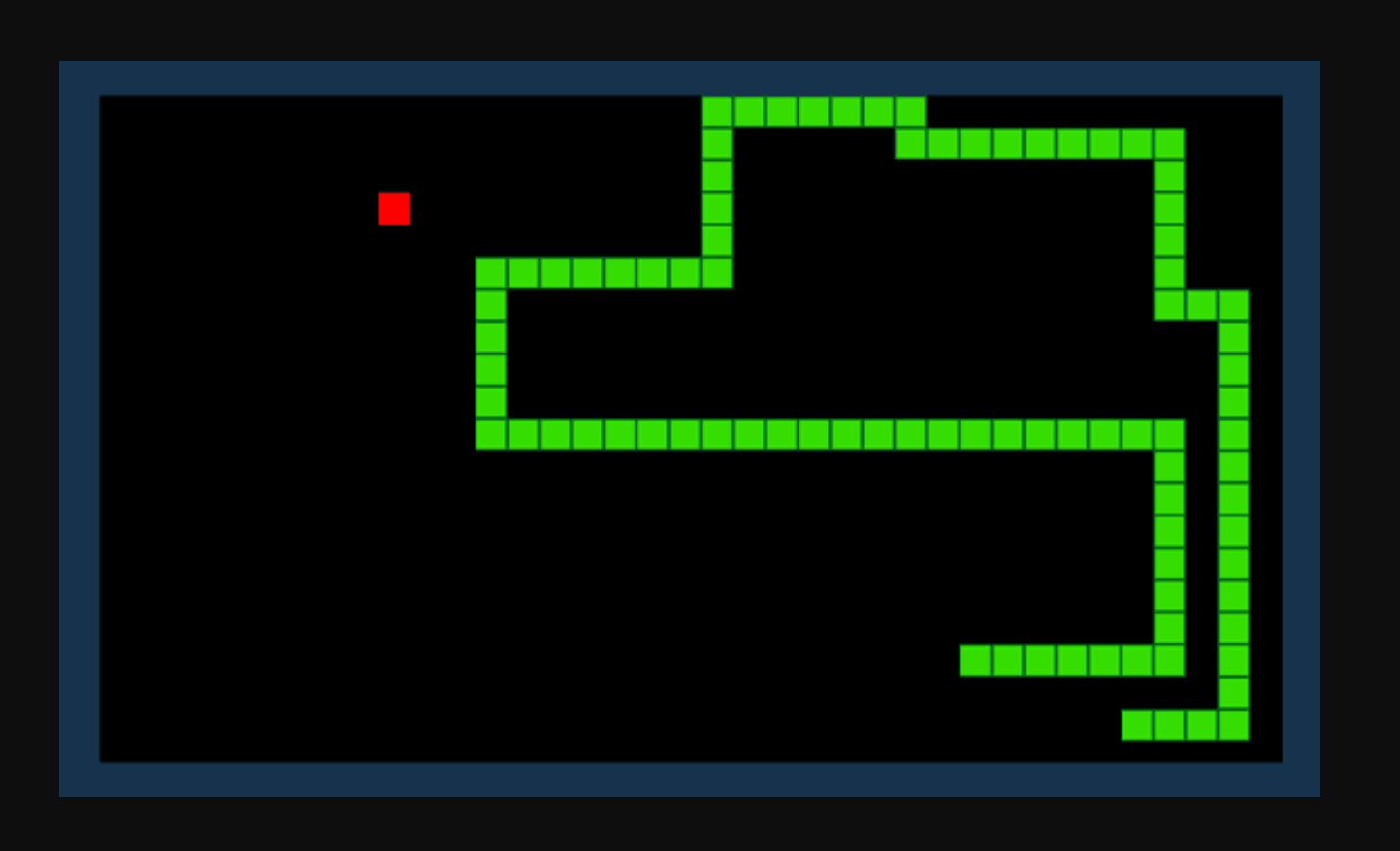
Möhkəmləndirici öyrənmə ilə biz R mükafat funksiyasını təyin edə bilərik. Funksiya İlan elementi istehlak etdikdə xal əlavə edir və İlan maneəyə dəydikdə xalları azaldır. Mövcud mühiti və bir sıra mümkün tədbirləri nəzərə alaraq, gücləndirici öyrənmə modelimiz mükafat funksiyamızı maksimuma çatdıran optimal "siyasəti" hesablamağa çalışacaq.
Neyrotəkamül
Təbiətdən ilhamlanaraq mövzunu davam etdirən tədqiqatçılar, neyroevolution kimi tanınan bir texnika vasitəsilə video oyunlarında ML-nin tətbiqində də uğur qazandılar.
İstifadə etmək əvəzinə gradient eniş şəbəkədəki neyronları yeniləmək üçün daha yaxşı nəticələr əldə etmək üçün təkamül alqoritmlərindən istifadə edə bilərik.
Təkamül alqoritmləri adətən təsadüfi fərdlərin ilkin populyasiyasını yaratmaqla başlayır. Daha sonra bu şəxsləri müəyyən meyarlar əsasında qiymətləndiririk. Ən yaxşı fərdlər “valideynlər” olaraq seçilir və yeni nəsil fərdlər yaratmaq üçün bir araya gətirilir. Bu şəxslər daha sonra əhalinin ən uyğun fərdlərini əvəz edəcəklər.
Bu alqoritmlər həmçinin genetik müxtəlifliyi qorumaq üçün krossover və ya “çoxaltma” addımı zamanı adətən mutasiya əməliyyatının bəzi formalarını təqdim edir.
Video Oyunlarda Maşın Öyrənməsinə dair Nümunə Tədqiqat
OpenAI Five

OpenAI Five populyar multiplayer mobil döyüş arenası (MOBA) oyunu olan DOTA 2-ni oynamaq məqsədi daşıyan OpenAI tərəfindən hazırlanmış kompüter proqramıdır.
Proqram saniyədə milyonlarla kadrdan öyrənmək üçün miqyaslanan mövcud möhkəmləndirmə öyrənmə üsullarından istifadə etdi. Paylanmış təlim sistemi sayəsində OpenAI hər gün 180 illik oyunlar oynaya bildi.
Təlim müddətindən sonra OpenAI Five mütəxəssis səviyyəsində performans əldə edə və insan oyunçularla əməkdaşlıq nümayiş etdirə bildi. 2019-cu ildə OpenAI beş bacardı məğlubiyyət Oyunçuların 99.4%-i ictimai matçlarda.
OpenAI niyə bu oyuna qərar verdi? Tədqiqatçıların fikrincə, DOTA 2 mövcud dərinlikdən kənarda olan mürəkkəb mexanikaya malik idi gücləndirici öyrənmə alqoritmlər.
Super Mario Bros
Video oyunlarda neyron şəbəkələrinin digər maraqlı tətbiqi Super Mario Bros.
Məsələn, bu hackathon girişi oyun haqqında heç bir məlumatın olmaması ilə başlayır və yavaş-yavaş bir səviyyədə irəliləmək üçün lazım olanların təməlini qurur.
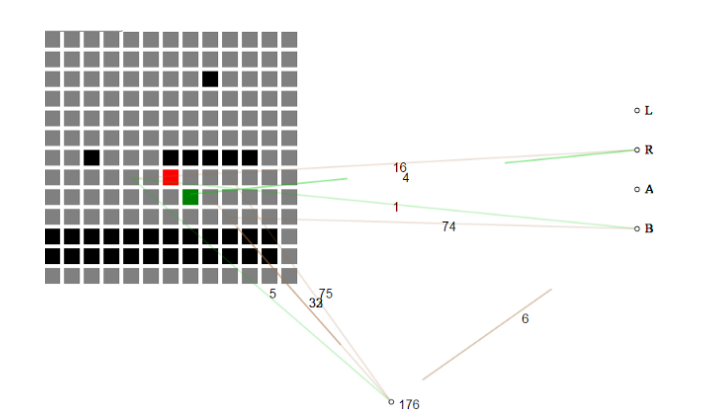
Öz-özünə inkişaf edən neyron şəbəkəsi oyunun hazırkı vəziyyətini plitələr şəbəkəsi kimi qəbul edir. Əvvəlcə neyron şəbəkəsi hər bir kafelin nə demək olduğunu başa düşmür, yalnız "hava" plitələrinin "yer plitələrindən" və "düşmən plitələrindən" fərqli olduğunu başa düşmür.
Hackathon layihəsinin neyrotəkamülü həyata keçirməsi NEAT genetik alqoritmindən istifadə edərək müxtəlif neyron şəbəkələrini seçici şəkildə yetişdirdi.
Əhəmiyyət
İndi video oyunları oynayan neyron şəbəkələrinin bəzi nümunələrini gördükdən sonra bütün bunların mənasının nə olduğunu düşünə bilərsiniz.
Video oyunlar agentlər və onların mühitləri arasında mürəkkəb qarşılıqlı əlaqəni ehtiva etdiyi üçün bu, AI yaratmaq üçün mükəmməl sınaq meydançasıdır. Virtual mühitlər təhlükəsiz və idarə oluna biləndir və sonsuz məlumat təchizatı təmin edir.
Bu sahədə aparılan tədqiqatlar tədqiqatçılara real dünyada problemlərin necə həll olunacağını öyrənmək üçün neyron şəbəkələrinin necə optimallaşdırıla biləcəyi barədə fikirlər verib.
Sinir şəbəkələri beyinlərin təbii dünyada necə işlədiyindən ilhamlanır. Video oyunu oynamağı öyrənərkən süni neyronların necə davrandığını öyrənməklə, biz həm də oyun oynamağın necə olduğunu başa düşə bilərik. insan beyni işləyir.
Nəticə
Neyron şəbəkələr və beyin arasındakı oxşarlıqlar hər iki sahədə anlayışlara səbəb olub. Neyron şəbəkələrinin problemləri necə həll edə biləcəyi ilə bağlı davam edən tədqiqatlar nə vaxtsa daha təkmil formalara gətirib çıxara bilər süni intellekt.
Təsəvvür edin ki, sizin spesifikasiyalarınıza uyğunlaşdırılmış, vaxtınıza dəyər olub olmadığını sizə bildirmək üçün satın almadan əvvəl bütöv bir video oyunu oynaya bilən AI istifadə edir. Video oyun şirkətləri oyun dizaynını yaxşılaşdırmaq, səviyyəni dəyişmək və rəqibin çətinliyini artırmaq üçün neyron şəbəkələrdən istifadə edərdilərmi?
Neyron şəbəkələri son oyunçuya çevrildikdə nə baş verəcək?





Cavab yaz