إنها مهمة حاسمة ومرغوبة في رؤية الكمبيوتر والرسومات لإنتاج أفلام بورتريه إبداعية على أعلى مستوى.
على الرغم من أنه تم اقتراح العديد من النماذج الفعالة لتوحيد الصورة الشخصية استنادًا إلى StyleGAN الفعال ، فإن هذه التقنيات الموجهة للصور لها عيوب واضحة عند استخدامها مع مقاطع الفيديو ، مثل حجم الإطار الثابت ، ومتطلبات محاذاة الوجه ، وغياب التفاصيل غير المتعلقة بالوجه ، وعدم الاتساق الزمني.
يتم استخدام إطار عمل VToonify الثوري لمعالجة نقل نمط الفيديو عالي الدقة الذي يتم التحكم فيه.
سنقوم بفحص أحدث دراسة حول VToonify في هذه المقالة ، بما في ذلك وظائفها وعيوبها وعوامل أخرى.
ما هو فتونيفي؟
يسمح إطار عمل VToonify بنقل نمط فيديو عمودي عالي الدقة وقابل للتخصيص.
يستخدم VToonify طبقات StyleGAN متوسطة وعالية الدقة لإنشاء صور فنية عالية الجودة بناءً على خصائص المحتوى متعدد المقاييس التي يتم استردادها بواسطة برنامج تشفير للاحتفاظ بتفاصيل الإطار.
تأخذ البنية التلافيفية الناتجة الوجوه غير المحاذاة في أفلام متغيرة الحجم كمدخلات ، مما ينتج عنه مناطق كاملة الوجه مع حركات واقعية في الإخراج.

يتوافق إطار العمل هذا مع النماذج الحالية لتوحيد الصورة القائمة على StyleGAN ، مما يسمح بتوسيعها لتشمل الفيديو ، وترث خصائص جذابة مثل اللون القابل للتعديل وتخصيص الكثافة.
هذه دراسة يقدم نسختين من VToonify استنادًا إلى Toonify و DualStyleGAN لنقل نمط فيديو عمودي قائم على التجميع والقائم على النموذج ، على التوالي.
تظهر النتائج التجريبية المكثفة أن إطار عمل VToonify المقترح يتفوق على الأساليب الحالية في إنتاج أفلام بورتريه فنية عالية الجودة ومتسقة زمنيًا مع معايير نمط متغيرة.
يقدم الباحثون دفتر جوجل كولاب، حتى تتسخ يديك.
كيف تعمل؟
لإنجاز نقل نمط فيديو عمودي قابل للتعديل وعالي الدقة ، يجمع VToonify بين مزايا إطار ترجمة الصور مع إطار العمل المستند إلى StyleGAN.
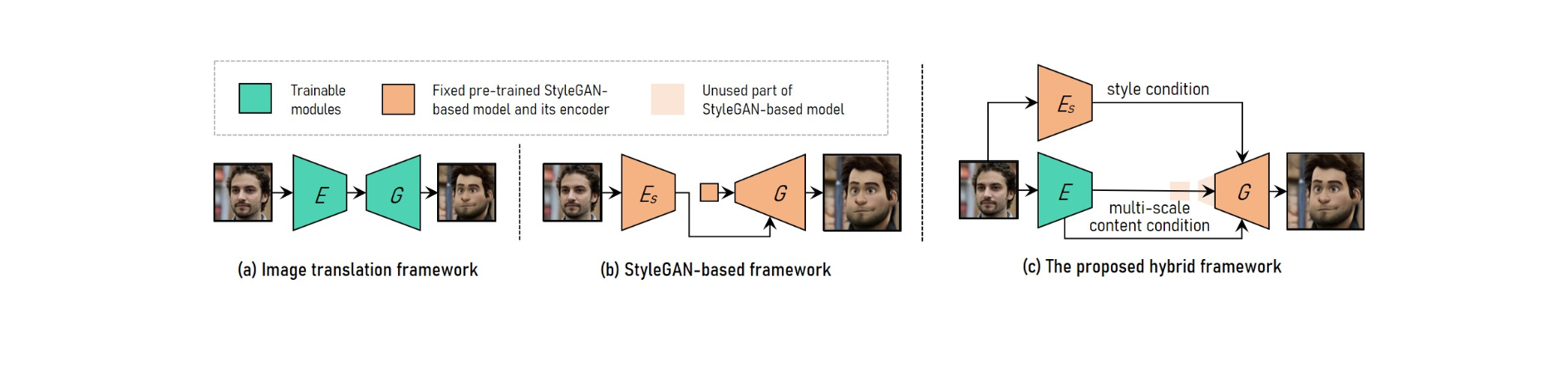
لاستيعاب أحجام الإدخال المختلفة ، يستخدم نظام ترجمة الصور شبكات تلافيفية بالكامل. من ناحية أخرى ، فإن التدريب من نقطة الصفر يجعل النقل عالي الدقة والأسلوب المتحكم فيه مستحيلاً.
يتم استخدام نموذج StyleGAN الذي تم تدريبه مسبقًا في إطار العمل المستند إلى StyleGAN لنقل أسلوب عالي الدقة والتحكم ، على الرغم من أنه يقتصر على حجم الصورة الثابت وفقدان التفاصيل.
تم تعديل StyleGAN في إطار العمل المختلط عن طريق حذف ميزة الإدخال ذات الحجم الثابت والطبقات منخفضة الدقة ، مما أدى إلى إنشاء بنية تلافيفية لمولد التشفير تمامًا مماثلة لتلك الخاصة بإطار عمل ترجمة الصور.
للحفاظ على تفاصيل الإطار ، قم بتدريب برنامج تشفير لاستخراج خصائص المحتوى متعدد المقاييس لإطار الإدخال كمتطلب محتوى إضافي للمولد. ترث Vtoonify مرونة التحكم في نمط طراز StyleGAN من خلال وضعها في المولد لتقطير بياناتها ونموذجها.
حدود StyleGAN و Vtoonify المقترحة
الصور الفنية شائعة في حياتنا اليومية وكذلك في الأعمال الإبداعية مثل الفن ، وسائل التواصل الاجتماعي الصور الرمزية والأفلام والإعلانات الترفيهية وما إلى ذلك.
مع تطور التعلم العميق التكنولوجيا ، أصبح من الممكن الآن إنشاء صور فنية عالية الجودة من صور الوجه الواقعية باستخدام النقل الآلي لنمط الصورة.
هناك مجموعة متنوعة من الطرق الناجحة التي تم إنشاؤها لنقل النمط المستند إلى الصور ، ويمكن الوصول إلى العديد منها بسهولة للمستخدمين المبتدئين في شكل تطبيقات الهاتف المحمول. أصبحت مواد الفيديو بسرعة دعامة أساسية لخلاصاتنا على وسائل التواصل الاجتماعي على مدار السنوات العديدة الماضية.
أدى ظهور وسائل التواصل الاجتماعي والأفلام المؤقتة إلى زيادة الطلب على تحرير الفيديو المبتكر ، مثل نقل نمط الفيديو العمودي ، لإنشاء مقاطع فيديو ناجحة ومثيرة للاهتمام.
التقنيات الحالية الموجهة للصور لها عيوب كبيرة عند تطبيقها على الأفلام ، مما يحد من فائدتها في الأسلوب الآلي للفيديو العمودي.
StyleGAN هو العمود الفقري الشائع لتطوير نموذج نقل نمط الصورة الشخصية نظرًا لقدرته على إنشاء وجوه عالية الجودة مع إدارة نمط قابلة للتعديل.
يقوم النظام المستند إلى StyleGAN (المعروف أيضًا باسم تحويل الصورة) بترميز وجه حقيقي في مساحة StyleGAN الكامنة ثم تطبيق رمز النمط الناتج على StyleGAN آخر تم ضبطه بدقة على مجموعة بيانات الصورة الفنية لإنشاء نسخة مبسطة.
ينشئ StyleGAN صورًا بأوجه محاذية وبحجم ثابت ، مما لا يفضل الوجوه الديناميكية في لقطات العالم الحقيقي. يؤدي اقتصاص الوجه ومحاذاته في الفيديو أحيانًا إلى وجه جزئي وإيماءات غير ملائمة. يطلق الباحثون على هذه المشكلة اسم "تقييد المحاصيل الثابتة" في StyleGAN.
تم اقتراح StyleGAN3 للوجوه غير المحاذاة ؛ ومع ذلك ، فإنه يدعم فقط حجم الصورة المحدد.
علاوة على ذلك ، اكتشفت دراسة حديثة أن تشفير الوجوه غير المحاذية يمثل تحديًا أكبر من الوجوه المحاذية. يعد ترميز الوجه غير الصحيح ضارًا بنقل نمط الصورة ، مما يؤدي إلى مشكلات مثل تغيير الهوية والمكونات المفقودة في الإطارات المعاد بناؤها ونمطها.
كما تمت مناقشته ، يجب أن تتعامل التقنية الفعالة لنقل نمط الفيديو العمودي مع المشكلات التالية:
- للحفاظ على الحركات الواقعية ، يجب أن يكون الأسلوب قادرًا على التعامل مع الوجوه غير المحاذاة وأحجام الفيديو المتنوعة. يمكن لحجم الفيديو الكبير أو زاوية الرؤية الواسعة التقاط المزيد من المعلومات مع منع الوجه من التحرك خارج الإطار.
- للتنافس مع الأدوات عالية الدقة المستخدمة بشكل شائع اليوم ، يلزم وجود فيديو عالي الدقة.
- يجب توفير تحكم مرن في النمط للمستخدمين لتغيير واختيار اختيارهم عند تطوير نظام تفاعل مستخدم واقعي.
لهذا الغرض ، يقترح الباحثون VToonify ، وهو إطار عمل هجين جديد لتحويل الفيديو. للتغلب على قيود المحاصيل الثابتة ، يدرس الباحثون أولاً معادلة الترجمة في StyleGAN.
يجمع VToonify بين مزايا البنية القائمة على StyleGAN وإطار عمل ترجمة الصور لتحقيق نقل نمط فيديو عمودي قابل للتعديل وعالي الدقة.
فيما يلي المساهمات الرئيسية:
- يدرس الباحثون قيود المحاصيل الثابتة في StyleGAN ويقترحون حلاً يعتمد على معادلة الترجمة.
- يقدم الباحثون إطار عمل VToonify تلافيفي فريد من نوعه لنقل نمط الفيديو الرأسي عالي الدقة المتحكم به والذي يدعم الوجوه غير المحاذاة وأحجام الفيديو المختلفة.
- يقوم الباحثون ببناء VToonify على العمود الفقري لـ Toonify و DualStyleGAN وتكثيف العمود الفقري من حيث البيانات والنموذج لتمكين نقل نمط الفيديو الرأسي القائم على التجميع والقائم على النموذج.
مقارنة Vtoonify مع أحدث النماذج الأخرى
توونيفاي
إنه بمثابة الأساس لنقل النمط القائم على التجميع على الوجوه المتوافقة باستخدام StyleGAN. لاسترداد رموز النمط ، يجب على الباحثين محاذاة الوجوه واقتصاص 256256 صورة لـ PSP. يستخدم Toonify لتوليد نتيجة مبسطة مع رموز نمط 1024 * 1024.
أخيرًا ، قاموا بإعادة محاذاة النتيجة في الفيديو إلى موقعها الأصلي. تم ضبط المنطقة غير المنمقة على اللون الأسود.

DualStyleGAN
إنه العمود الفقري لنقل النمط المستند إلى النموذج استنادًا إلى StyleGAN. يستخدمون نفس تقنيات المعالجة المسبقة واللاحقة للبيانات مثل Toonify.
Pix2pixHD
إنه نموذج ترجمة من صورة إلى صورة يُستخدم بشكل شائع لتكثيف النماذج المدربة مسبقًا للتحرير عالي الدقة. يتم تدريبه باستخدام البيانات المقترنة.
يستخدم الباحثون pix2pixHD كمدخلات إضافية لخريطة المثيل لأنه يستخدم خريطة التحليل المستخرجة.
الحركة من الدرجة الأولى
FOM هو نموذج نموذجي للرسوم المتحركة للصور. تم تدريبه على 256256 صورة وكان أداؤه ضعيفًا مع أحجام الصور الأخرى. نتيجة لذلك ، قام الباحثون أولاً بقياس إطارات الفيديو إلى 256 * 256 للرسوم المتحركة ثم غيروا حجم النتائج إلى حجمها الأصلي.
لإجراء مقارنة عادلة ، يستخدم FOM أول إطار منمق لنهجها كصورة نمط مرجعي.
دغان
إنه نموذج ثلاثي الأبعاد للرسوم المتحركة للوجه. يستخدمون نفس طرق إعداد البيانات والمعالجة اللاحقة مثل FOM.

المزايا
- يمكن توظيفها في الفنون والصور الرمزية لوسائل التواصل الاجتماعي والأفلام والإعلانات الترفيهية وما إلى ذلك.
- يمكن أيضًا استخدام Vtoonify في metaverse.
القيود
- تستخرج هذه المنهجية كلاً من البيانات والنموذج من العمود الفقري المستند إلى StyleGAN ، مما ينتج عنه تحيز في البيانات والنموذج.
- يرجع السبب في هذه القطع الأثرية في الغالب إلى اختلافات الحجم بين منطقة الوجه المنمقة والأقسام الأخرى.
- هذه الإستراتيجية أقل نجاحًا عند التعامل مع الأشياء في منطقة الوجه.
وفي الختام
أخيرًا ، VToonify هو إطار عمل لتوحيد الفيديو عالي الدقة المتحكم فيه بأسلوب.
يحقق إطار العمل هذا أداءً رائعًا في التعامل مع مقاطع الفيديو ويتيح تحكمًا واسعًا في النمط الهيكلي ونمط اللون ودرجة النمط من خلال تكثيف نماذج تحويل الصورة القائمة على StyleGAN من حيث كل من البيانات الاصطناعية وهياكل الشبكات.





اترك تعليق