لا تزال ألعاب الفيديو تشكل تحديًا لمليارات اللاعبين حول العالم. قد لا تعرف ذلك حتى الآن ، لكن خوارزميات التعلم الآلي بدأت في الارتقاء إلى مستوى التحدي أيضًا.
يوجد حاليًا قدر كبير من البحث في مجال الذكاء الاصطناعي لمعرفة ما إذا كان يمكن تطبيق أساليب التعلم الآلي على ألعاب الفيديو. التقدم الكبير في هذا المجال يدل على ذلك آلة التعلم يمكن استخدام الوكلاء لمحاكاة أو حتى استبدال اللاعب البشري.
ماذا يعني هذا بالنسبة لمستقبل ألعاب الفيديو?
هل هذه المشاريع للمتعة فقط ، أم أن هناك أسبابًا أعمق تجعل الكثير من الباحثين يركزون على الألعاب؟
ستستكشف هذه المقالة بإيجاز تاريخ الذكاء الاصطناعي في ألعاب الفيديو. بعد ذلك ، سنقدم لك نظرة عامة سريعة على بعض تقنيات التعلم الآلي التي يمكننا استخدامها لمعرفة كيفية التغلب على الألعاب. سننظر بعد ذلك في بعض التطبيقات الناجحة لـ شبكات عصبية لتعلم وإتقان ألعاب فيديو معينة.
تاريخ موجز للذكاء الاصطناعي في الألعاب
قبل أن نتطرق إلى سبب تحول الشبكات العصبية إلى الخوارزمية المثالية لحل ألعاب الفيديو ، دعونا ننظر بإيجاز في كيفية استخدام علماء الكمبيوتر لألعاب الفيديو لتطوير أبحاثهم في مجال الذكاء الاصطناعي.
يمكنك القول إن ألعاب الفيديو ، منذ بدايتها ، كانت مجال بحث ساخن للباحثين المهتمين بالذكاء الاصطناعي.
على الرغم من أن لعبة الشطرنج ليست لعبة فيديو في الأصل ، إلا أنها كانت محط تركيز كبير في الأيام الأولى للذكاء الاصطناعي. في عام 1951 ، كتب الدكتور ديتريش برينز برنامجًا للعب الشطرنج باستخدام الكمبيوتر الرقمي Ferranti Mark 1. كان هذا في زمن قديم عندما كان على أجهزة الكمبيوتر الضخمة هذه أن تقرأ البرامج من على شريط ورقي.

البرنامج نفسه لم يكن لعبة شطرنج كاملة AI. نظرًا لقيود الكمبيوتر ، لم يتمكن Prinz من إنشاء برنامج يحل مشاكل شريك الشطرنج. في المتوسط ، استغرق البرنامج 15-20 دقيقة لحساب كل حركة ممكنة للاعبين الأبيض والأسود.
العمل على تحسين لعبة الشطرنج والداما لقد تحسن الذكاء الاصطناعي بشكل مطرد على مر العقود. بلغ التقدم ذروته في عام 1997 عندما هزم ديب بلو من شركة آي بي إم لاعب الشطرنج الروسي غاري كاسباروف في مباراتين من ست مباريات. في الوقت الحاضر ، يمكن لمحركات الشطرنج التي يمكنك أن تجدها على هاتفك المحمول أن تهزم ديب بلو.
بدأ معارضو الذكاء الاصطناعي يكتسبون شعبية خلال العصر الذهبي لألعاب الفيديو. يعد Space Invaders في عام 1978 و Pac-Man في الثمانينيات من رواد الصناعة في إنشاء ذكاء اصطناعي يمكنه تحدي حتى أكثر لاعبي ألعاب الآركيد خبرة.
كانت لعبة Pac-Man ، على وجه الخصوص ، لعبة شائعة للباحثين في مجال الذكاء الاصطناعي لتجربتها. مختلف المسابقات لقد تم تنظيم السيدة باك مان لتحديد الفريق الذي يمكن أن يأتي بأفضل ذكاء اصطناعي للتغلب على اللعبة.
استمرت لعبة الذكاء الاصطناعي والخوارزميات التجريبية في التطور مع ظهور الحاجة إلى خصوم أكثر ذكاءً. على سبيل المثال ، ارتفعت شعبية معارك الذكاء الاصطناعي حيث أصبحت الأنواع مثل ألعاب إطلاق النار من منظور الشخص الأول أكثر انتشارًا.
تعلم الآلة في ألعاب الفيديو
مع ازدياد شعبية تقنيات التعلم الآلي بسرعة ، حاولت العديد من المشاريع البحثية استخدام هذه التقنيات الجديدة للعب ألعاب الفيديو.
ألعاب مثل Dota 2 و StarCraft و Doom يمكن أن تكون بمثابة مشاكل لهذه الألعاب خوارزميات التعلم الآلي لتحل. خوارزميات التعلم العميق، على وجه الخصوص ، كانت قادرة على تحقيق بل وتجاوز الأداء على المستوى البشري.
• بيئة التعلم الممرات أو ALE أعطى الباحثين واجهة لأكثر من مائة لعبة أتاري 2600. سمحت المنصة مفتوحة المصدر للباحثين بقياس أداء تقنيات التعلم الآلي على ألعاب الفيديو أتاري الكلاسيكية. نشرت جوجل حتى الخاصة بهم ورقة باستخدام سبع ألعاب من ALE

وفي الوقت نفسه ، مشاريع مثل فيزدوم منح الباحثين في مجال الذكاء الاصطناعي الفرصة لتدريب خوارزميات التعلم الآلي على لعب ألعاب التصويب ثلاثية الأبعاد من منظور الشخص الأول.

كيف يعمل: بعض المفاهيم الأساسية
الشبكات العصبية
تتضمن معظم طرق حل ألعاب الفيديو باستخدام التعلم الآلي نوعًا من الخوارزمية المعروفة باسم الشبكة العصبية.
يمكنك التفكير في الشبكة العصبية كبرنامج يحاول تقليد كيفية عمل الدماغ. على غرار الطريقة التي يتكون بها دماغنا من الخلايا العصبية التي تنقل الإشارات ، تحتوي الشبكة العصبية أيضًا على خلايا عصبية اصطناعية.
تقوم هذه الخلايا العصبية الاصطناعية أيضًا بنقل الإشارات إلى بعضها البعض ، حيث تكون كل إشارة رقمًا حقيقيًا. تحتوي الشبكة العصبية على طبقات متعددة بين طبقات الإدخال والإخراج ، تسمى الشبكة العصبية العميقة.
تعزيز التعلم
تقنية التعلم الآلي الشائعة الأخرى ذات الصلة بتعلم ألعاب الفيديو هي فكرة التعلم المعزز.
هذه التقنية هي عملية تدريب وكيل باستخدام المكافآت أو العقوبات. باستخدام هذا النهج ، يجب أن يكون الوكيل قادرًا على التوصل إلى حل لمشكلة من خلال التجربة والخطأ.
لنفترض أننا نريد الذكاء الاصطناعي لمعرفة كيفية لعب لعبة الثعبان. هدف اللعبة بسيط: الحصول على أكبر عدد ممكن من النقاط عن طريق استهلاك العناصر وتجنب نمو ذيلك.
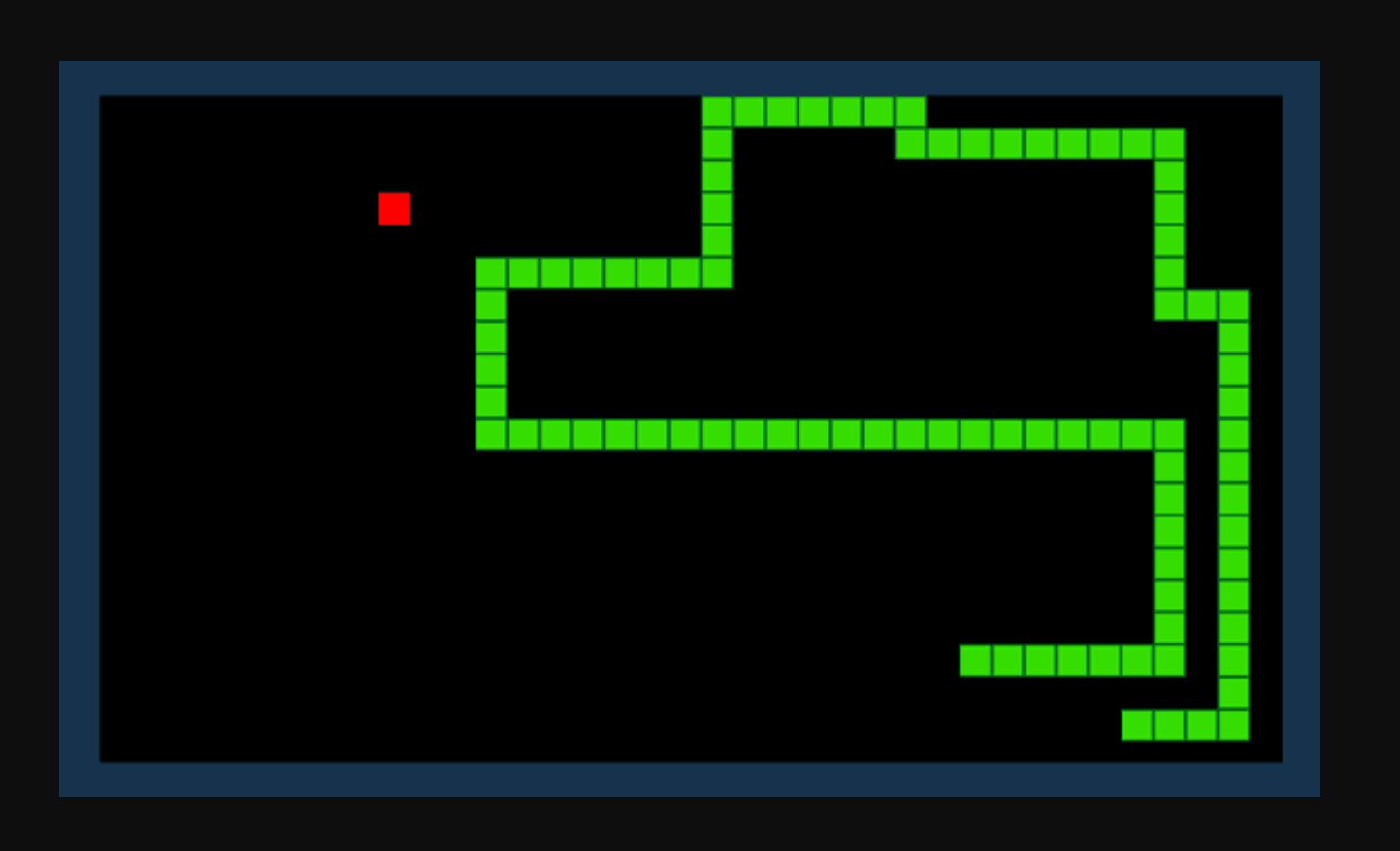
من خلال التعلم المعزز ، يمكننا تحديد وظيفة المكافأة R. تضيف الوظيفة نقاطًا عندما يستهلك الثعبان عنصرًا ويخصم النقاط عندما يصطدم الأفعى بعقبة. بالنظر إلى البيئة الحالية ومجموعة من الإجراءات الممكنة ، سيحاول نموذج التعلم المعزز لدينا حساب "السياسة" المثلى التي تزيد من وظيفة المكافأة لدينا.
التطور العصبي
تمشيا مع موضوع الإلهام من الطبيعة ، وجد الباحثون أيضًا نجاحًا في تطبيق ML على ألعاب الفيديو من خلال تقنية تُعرف باسم neuroevolution.
بدلا من استخدام نزول متدرج لتحديث الخلايا العصبية في الشبكة ، يمكننا استخدام الخوارزميات التطورية لتحقيق نتائج أفضل.
تبدأ الخوارزميات التطورية عادةً بتوليد مجموعة أولية من الأفراد العشوائيين. ثم نقوم بتقييم هؤلاء الأفراد باستخدام معايير معينة. يتم اختيار أفضل الأفراد كـ "آباء" ويتم تربيتهم معًا لتشكيل جيل جديد من الأفراد. سيحل هؤلاء الأفراد بعد ذلك محل الأفراد الأقل لياقة في السكان.
تقدم هذه الخوارزميات أيضًا بشكل نموذجي شكلاً من أشكال عملية الطفرة أثناء التقاطع أو خطوة "التربية" للحفاظ على التنوع الجيني.
نموذج بحث حول التعلم الآلي في ألعاب الفيديو
أوبن إيه آي خمسة

أوبن إيه آي خمسة هو برنامج كمبيوتر من OpenAI يهدف إلى لعب DOTA 2 ، وهي لعبة قتال متعددة اللاعبين (MOBA) مشهورة.
استفاد البرنامج من تقنيات التعلم التعزيزية الحالية ، والتي تم توسيع نطاقها للتعلم من ملايين الإطارات في الثانية. بفضل نظام التدريب الموزع ، تمكنت OpenAI من لعب ما يعادل 180 عامًا من الألعاب كل يوم.
بعد فترة التدريب ، تمكنت OpenAI Five من تحقيق أداء على مستوى الخبراء وإظهار التعاون مع اللاعبين البشريين. في عام 2019 ، تمكنت شركة OpenAI Five من القيام بذلك هزيمة 99.4٪ من اللاعبين في المباريات العامة.
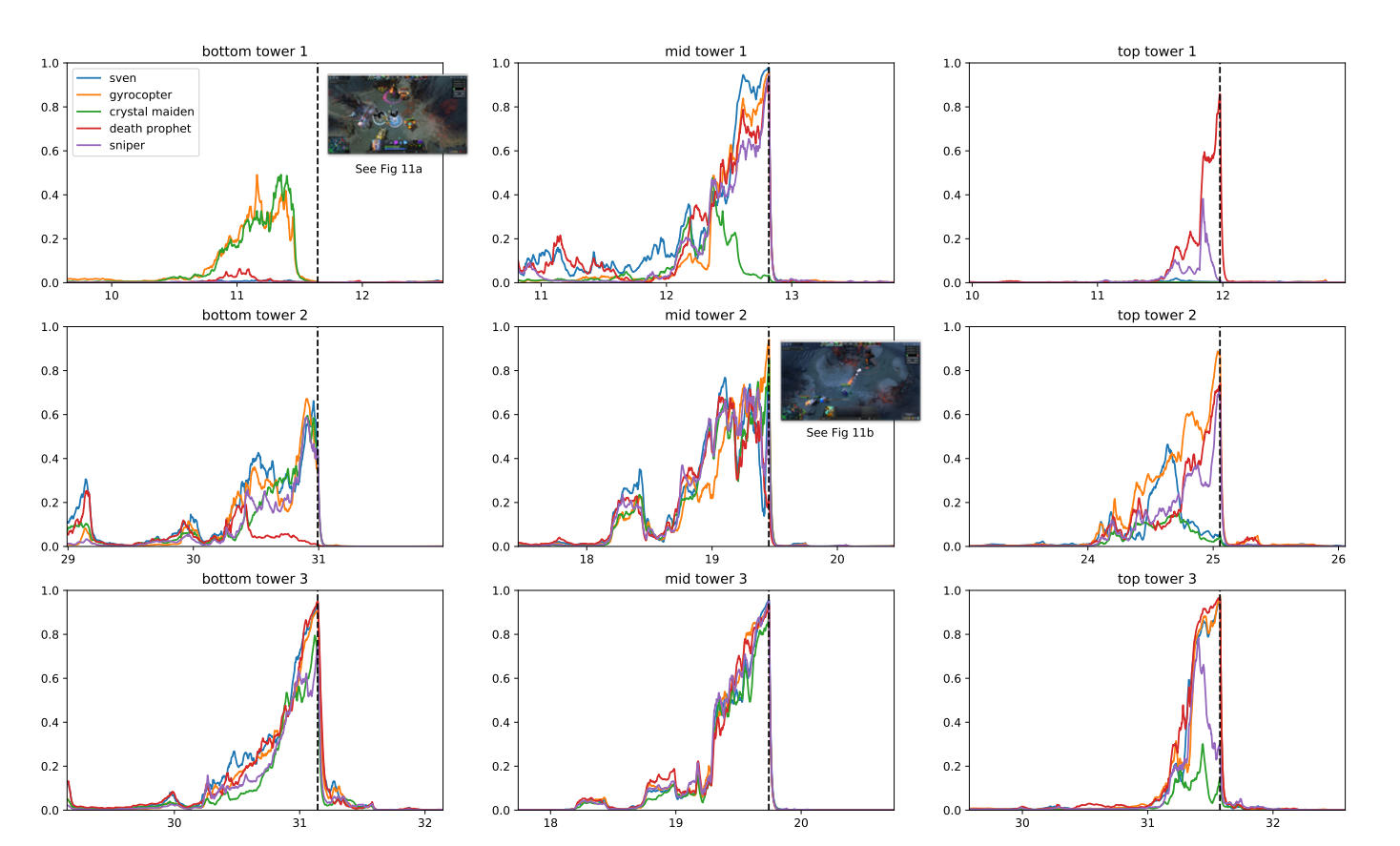
لماذا قررت شركة OpenAI هذه اللعبة؟ وفقًا للباحثين ، فإن DOTA 2 لديها ميكانيكا معقدة كانت بعيدة عن متناول الأعماق الموجودة تعزيز التعلم الخوارزميات.
سوبر ماريو بروس
تطبيق آخر مثير للاهتمام للشبكات العصبية في ألعاب الفيديو هو استخدام neuroevolution للعب منصات مثل Super Mario Bros.
على سبيل المثال ، هذا دخول الهاكاثون يبدأ بعدم وجود معرفة باللعبة ويبني ببطء أساسًا لما هو مطلوب للتقدم عبر المستوى.
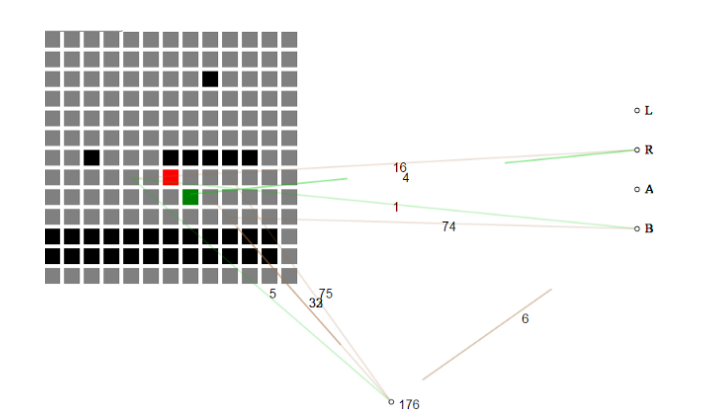
تأخذ الشبكة العصبية ذاتية التطور الوضع الحالي للعبة كشبكة من المربعات. في البداية ، لا تفهم الشبكة العصبية ما تعنيه كل قطعة ، فقط أن البلاط "الهوائي" يختلف عن "بلاطات الأرضية" و "بلاطات العدو".
استخدم تنفيذ مشروع الهاكاثون للتطور العصبي الخوارزمية الجينية NEAT لتربية شبكات عصبية مختلفة بشكل انتقائي.
أهمية
الآن بعد أن رأيت بعض الأمثلة على الشبكات العصبية التي تلعب ألعاب الفيديو ، قد تتساءل ما هو الهدف من كل هذا.
نظرًا لأن ألعاب الفيديو تتضمن تفاعلات معقدة بين الوكلاء وبيئاتهم ، فهي أرض الاختبار المثالية لصنع الذكاء الاصطناعي. البيئات الافتراضية آمنة ويمكن التحكم فيها وتوفر إمدادًا غير محدود من البيانات.
أعطت الأبحاث التي تم إجراؤها في هذا المجال للباحثين نظرة ثاقبة حول كيفية تحسين الشبكات العصبية لمعرفة كيفية حل المشكلات في العالم الحقيقي.
الشبكات العصبية مستوحاة من كيفية عمل العقول في العالم الطبيعي. من خلال دراسة كيفية تصرف الخلايا العصبية الاصطناعية عند تعلم كيفية لعب لعبة فيديو ، قد نكتسب أيضًا نظرة ثاقبة حول كيفية عمل العقل البشري الأشغال.
وفي الختام
أدت أوجه التشابه بين الشبكات العصبية والدماغ إلى رؤى في كلا المجالين. قد يؤدي البحث المستمر حول كيفية حل الشبكات العصبية للمشكلات في يوم من الأيام إلى أشكال أكثر تقدمًا من الذكاء الاصطناعي.
تخيل استخدام ذكاء اصطناعي مصمم وفقًا لمواصفاتك يمكنه تشغيل لعبة فيديو كاملة قبل شرائها لإعلامك بما إذا كانت تستحق وقتك. هل ستستخدم شركات ألعاب الفيديو الشبكات العصبية لتحسين تصميم اللعبة ، ومستوى القرص ، وصعوبة الخصم؟
ما رأيك سيحدث عندما تصبح الشبكات العصبية اللاعب النهائي؟





اترك تعليق