Webskraap het 'n deurslaggewende metode geword om insiggewende data vanaf internetplatforms in vandag se data-gedrewe samelewing te verkry.
As 'n uiters gewilde sosiale media-webwerf bied Instagram baie gebruikergegenereerde materiaal. En hierdie gegenereerde data kan vir bemarking, navorsing en ander redes gebruik word.
Gebruikers kan data van Instagram met gemak en doeltreffendheid onttrek danksy Bright Data se kenmerkryke Instagram-skrapers, 'n toonaangewende webskraap gereedskap. In hierdie pos gee ons 'n deeglike, stap-vir-stap deurbraak van die Instagram-skraapproses.
Dus, kom ons kyk na die stappe vir hoe ons data van Instagram kan skraap.
Verstaan Instagram-skrapers van Bright Data
Met die hulp van twee veeldoelige webskrapers en 'n vooraf saamgestelde datastel, bied Bright Data 'n verskeidenheid Instagram-skraapdienste. Hierdie tegnologieë bied veelsydigheid in data-onttrekking en pas by verskeie eise aan.
Kom ons ondersoek elkeen van hierdie keuses in meer besonderhede:
a. Skraapblaaier
Die innoverende tegnologie bekend as Scraping Browser is geskep om aan die vereistes van dataskraapprojekte te voldoen. Dit bied alles wat nodig is om op skaal binne 'n enkele blaaier te skraap. Dit staan uit danksy die geïntegreerde outomatisering van die ontblokkering van die webwerf, wat dit die enigste blaaier in sy soort ter wêreld maak.
Scraping Browser gee gebruikers toegang tot robuuste kenmerke wat verder gaan as outomatiese en koplose blaaiers, wat hulle in staat stel om verder te kom as selfs die moeilikste skrifte en webwerf-versperrings vir bot-opsporing.
Dataskraping is meer effektief en moeitevry vanweë die outomatiese aanpassingskenmerke, wat vars blokke, CAPTCHA-oplossings, vingerafdrukke en herproberings maklik bestuur, en verskyn as 'n opregte gebruiker.
Gebruik KI om bot-opsporingstelsels te uitoorlê
Deur die nuutste KI-tegnologie te gebruik, kan Scraping Browser bot-opsporingstelsels uitoorlê en voortdurend by hul verskuiwingstrategieë aanpas. Om webbladsye beter te ontsluit, leer Scraping Browser uit hierdie stelsels se pogings om skraappogings op te spoor en te blokkeer en wysig sy gedrag gepas.
Dit presteer beter as die doeltreffendheid van konvensionele gevolmagtigdes deur die gedrag van 'n blaaier wat deur 'n regte gebruiker gebruik word, na te boots. Gevolglik kan kliënte konsentreer op hul doelwitte vir dataskraap sonder om die moeilikheid en koste van voortdurende bot-opsporingsprosedures te hanteer.
b. Webskraper IDE
Web Scraper IDE, 'n robuuste webskraapinstrument wat vir ontwikkelaars geskep is, kan komplekse skraaptake hanteer. Dit verminder die ontwikkelingstyd aansienlik, terwyl dit oneindige skaalbaarheid bied danksy sy volledig gehuisveste oplossing en voorafgeboude skraapkenmerke. Die toepassing maak die vinnige en skaalbare bou van aanlynskrapers moontlik deur kodesjablone en klaargemaakte JavaScript-funksies vanaf gewilde webwerwe te verskaf.
Alles wat nodig is vir suksesvolle webskraap word verskaf deur die Web Scraper IDE. Dit is 'n volledige oplossing vir aanlyn data-onttrekking, aangesien integrasie-opsies kliënte in staat stel om deurkruise te beplan of dit deur API te begin en met hoofbergingstelsels te skakel.
Hoe om dit te gebruik? - Tutoriaal
Gaan eers na die gebruikerskontroleskerm op die webwerf.

Kom ons begin met ons stappe om Instagram te krap.
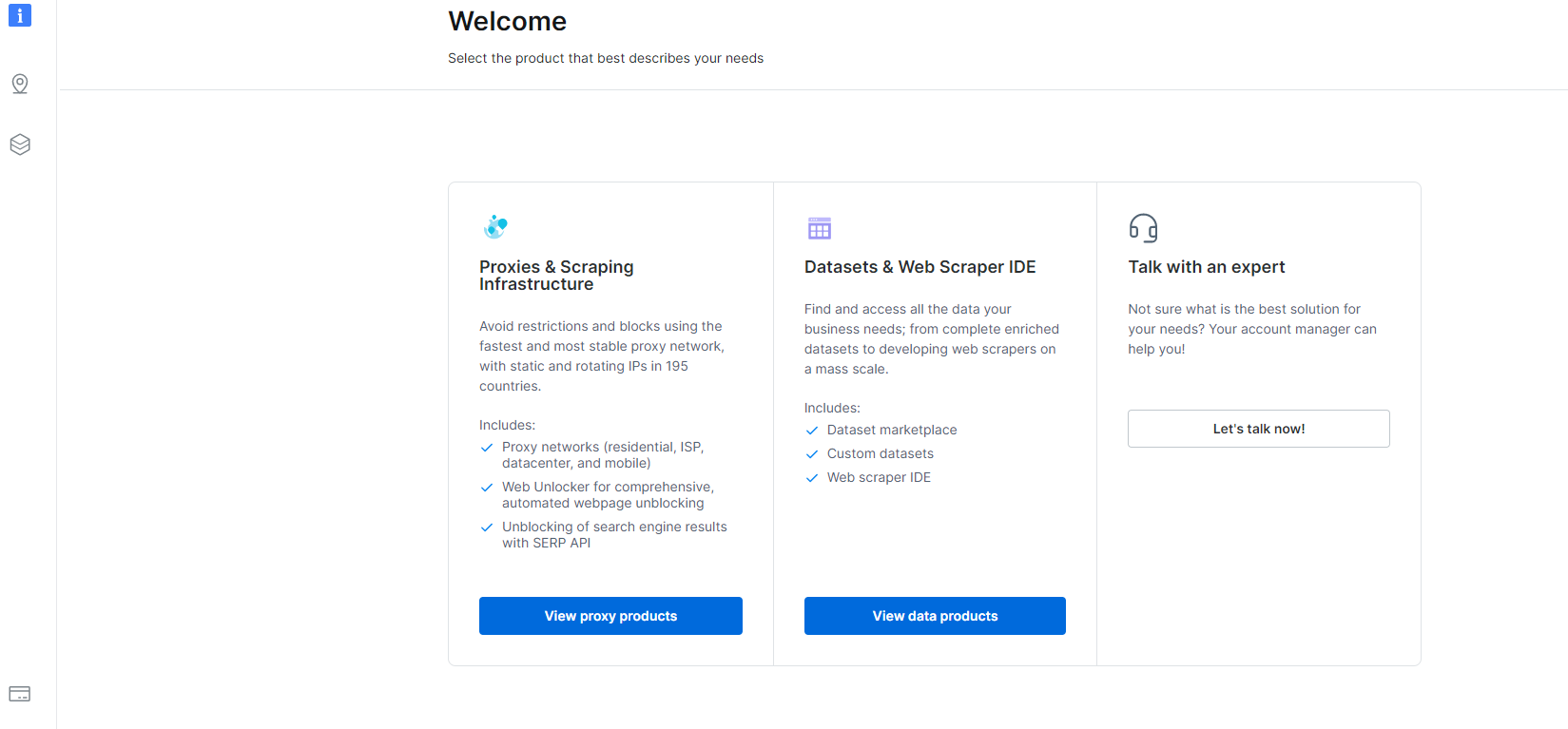
1- Navigeer na die Dashboard en klik op die Datasets & Web Scraper IDE-afdeling.
2- Sodra jy daar is, klik op My Scrapers.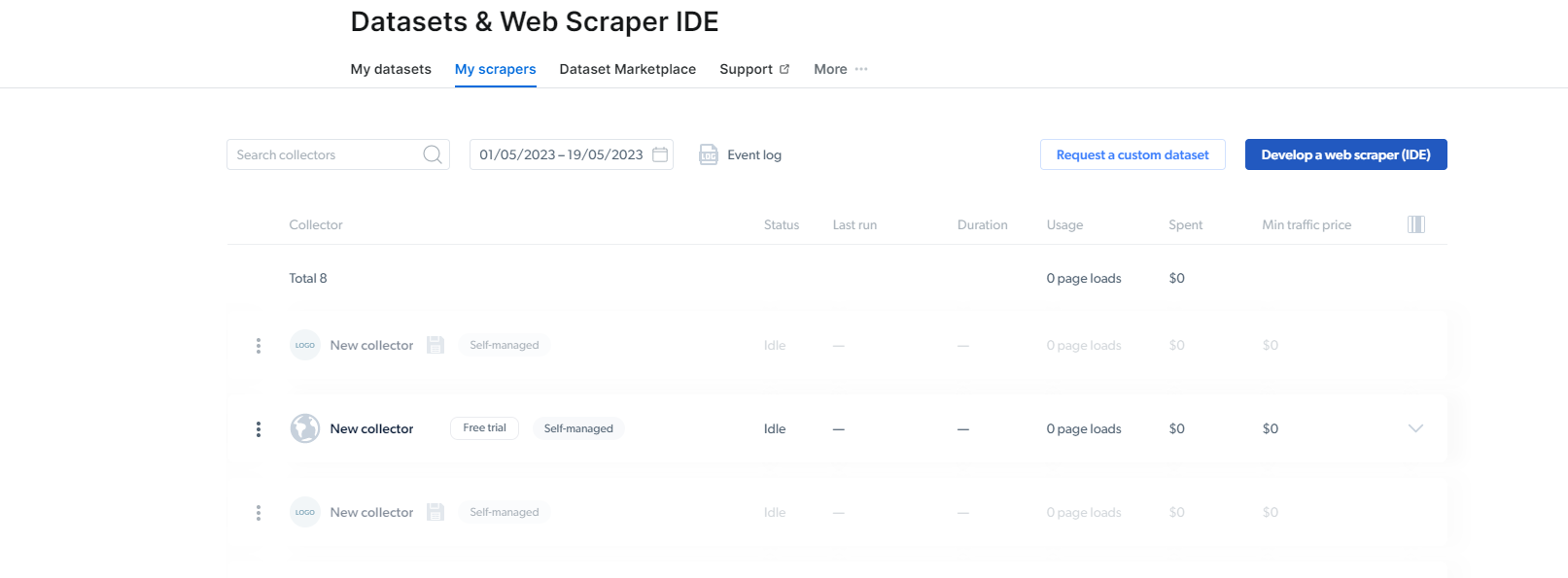
Hier moet u op "Ontwikkel 'n webskraper (IDE)" klik. Hier sal ons ons skraper vir Instagram skep.
3-Nou moet ons 'n nuwe webskraper ontwikkel. Net vir hierdie voorbeeld kies ek om die "NASA"-rekening te skraap. Dit is net ter wille van hierdie voorbeeld.
So, my kode sal soos volg lyk:
/ Click the 'play' button in the top right to run this code:
// 1. Go to the page where you want to start
navigate('https://www.instagram.com/nasa/');
// 2. Add anything else you need to do on the page.
// For example: (see the help box for all command docs).
// click('.some-button')
// type('.some-input', 'shoes')
// wait('.some-lazy-loaded-element')
// 3. Once the browser page has the data you want, call parse() to get the data
// and call collect() to add a record to your final dataset
let data = parse();
collect({
url: new URL(location.href),
title: "Nasa Account",
links: data.links,
});
Jy moet op die 'speel'-knoppie regs bo klik om hierdie kode uit te voer.
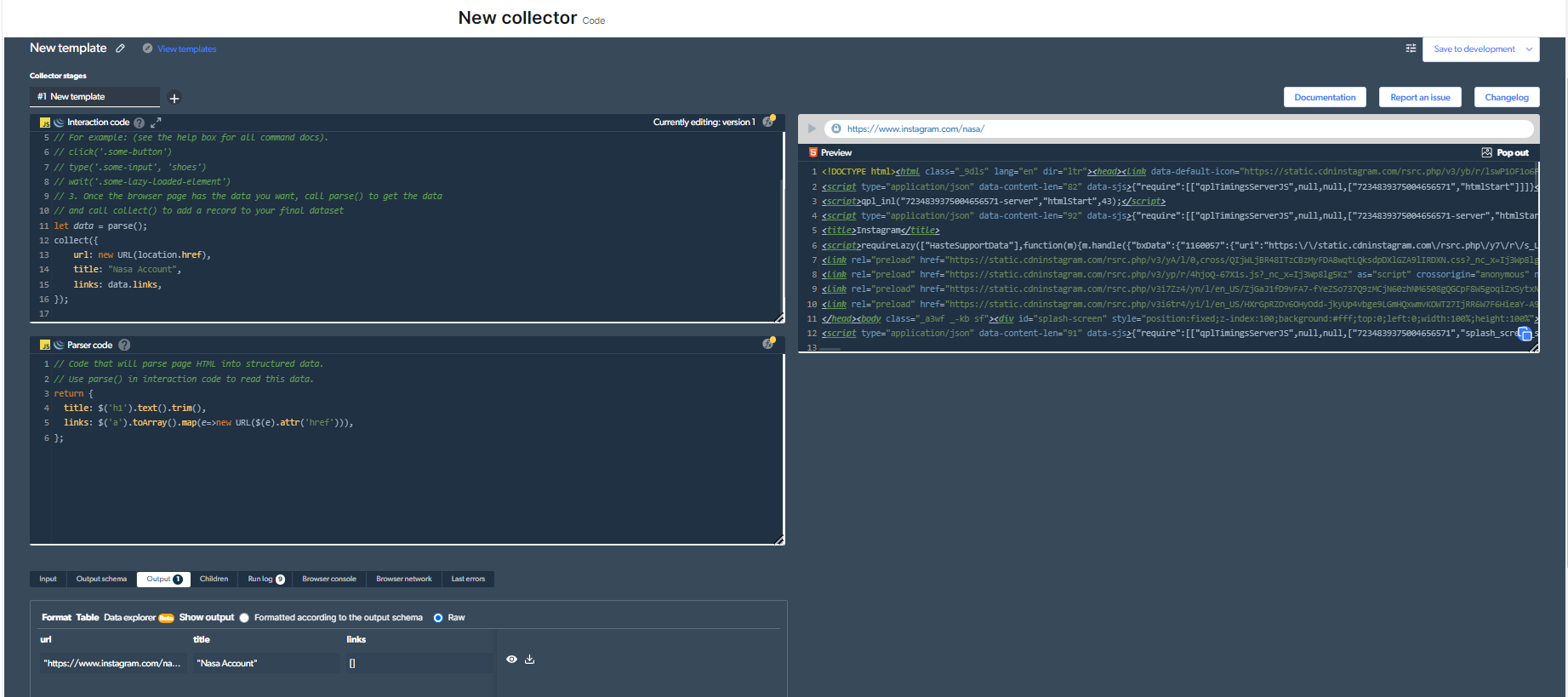
4- Nou sal ons 'n uitset hê.
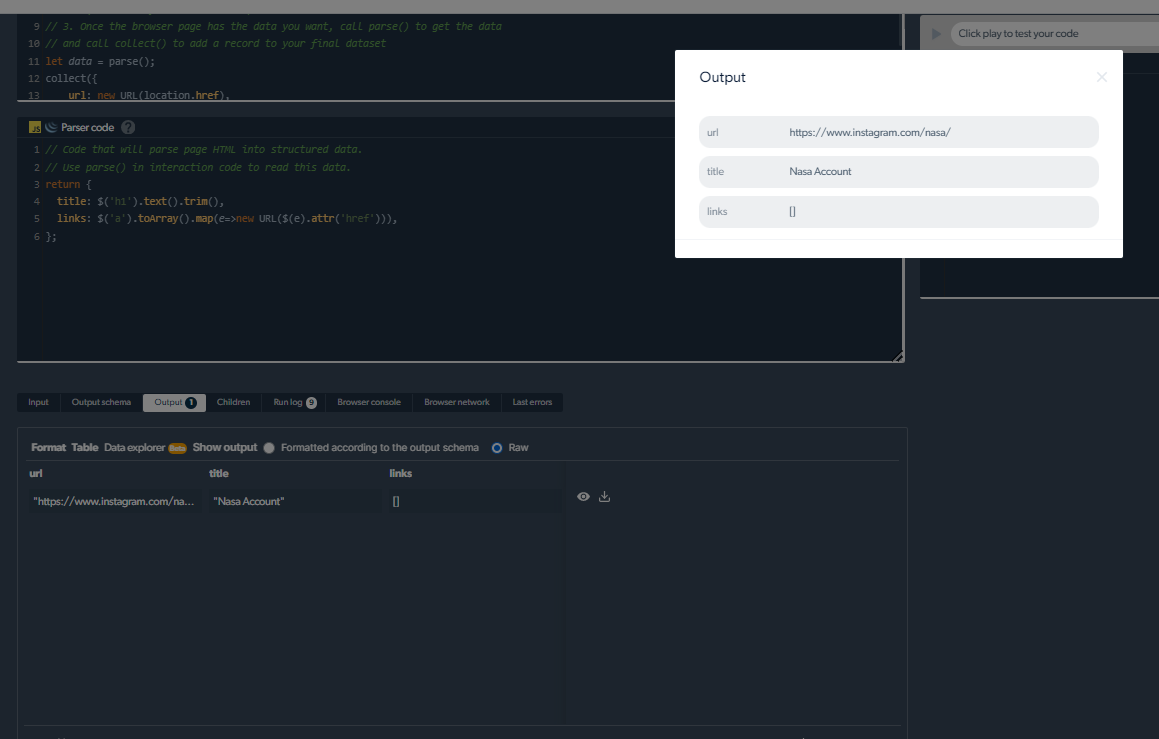
Hantering van skraapprobleme
Instagram-plasings met die "wys meer-knoppie" kan moeilik wees vir skrapers om vas te vang. Instagram-skrapers van Bright Data word egter gemaak om sulke kompleksiteit suksesvol te hanteer. Hierdie skrapers het die nuutste vaardighede om deur die paginering en laai van bykomende knoppies te beweeg.
Bright Data se Instagram-skrapers hanteer hierdie probleme effektief om deeglike data-onttrekking moontlik te maak, wat jou in staat stel om die hele versameling inligting te versamel wat nodig is vir jou ontleding of studie.
U kan die uitdagings wat deur Instagram-plasings se dinamiese aard bied, omseil deur hierdie skraapnutsmiddels te gebruik.
c. Vooraf versamelde datastel
Bright Data verstaan dat nie almal hul skraper wil gebruik nie. Hulle verskaf 'n voorafversamelde datastel vir Instagram om by sulke verbruikers 'n beroep te doen.
Hierdie datastel bied 'n magdom nuttige inligting, soos volgelinge, profiele, plasings en meer.
Bright Data bied pasmaakopsies om die datastel volgens jou behoeftes te verpersoonlik, of jy nou 'n hele datastel of 'n subset van gespesialiseerde data wil hê. Hierdie benadering vermy die konstruksie en bestuur van 'n skraper, en gee jou gereed-vir-gebruik data vir ontleding en insigte.
Kom ons kyk nou na die infrastruktuur wat hierdie nutsmiddels so doeltreffend maak: die proxy-infrastruktuur en Web Unlocker.
Maak die krag van gevolmagtigdes los
Die gebruik van gevolmagtigdes is van kardinale belang tydens webskraap om te verseker dat u optrede ongemerk bly.
Bright Data bied 'n wye verskeidenheid van proxy dienste wat volgens u vereistes aangepas is. Jy kan kies uit Residensiële volmag, wat meer as 72 miljoen IP's bied wat vanaf werklike eweknie-toestelle in 195 lande geroteer is.
U kan ISP-gevolmagtigdes kies, wat 700,000 770,000+ regte tuis-IP's wêreldwyd bied vir langtermyngebruik; Datacenter-gevolmagtigdes, wat 3 4+ gedeelde IP's van enige geo-ligging het; en Mobile Proxies, wat die grootste 7,000,000G/XNUMXG-selfoonnetwerk met werklike eweknie vorm met XNUMX+ IP's.
Met die gebruik van hierdie gevolmagtigdes kan 'n mens maklik data insamel terwyl jy hom op talle plekke as 'n gemagtigde gebruiker voordoen.

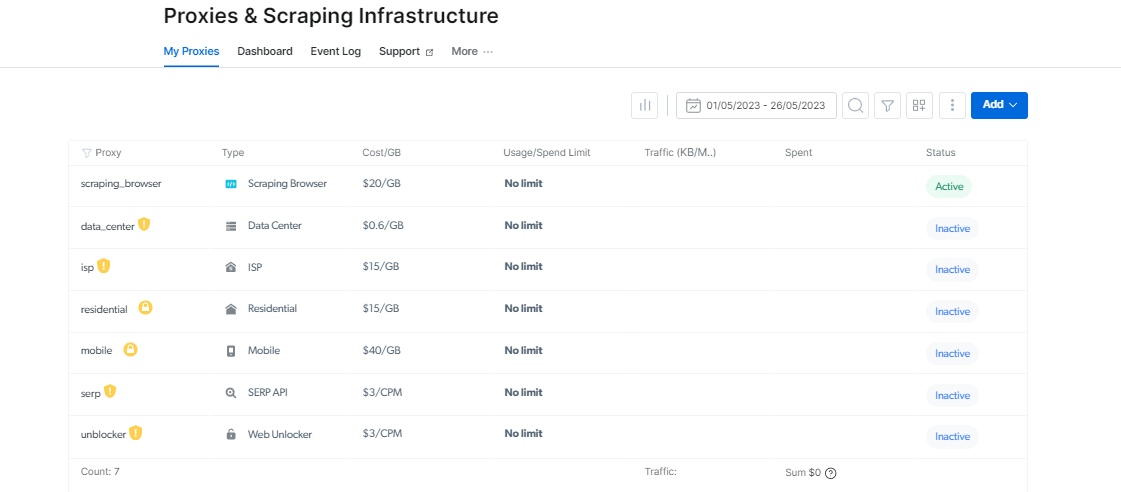
Proxy Bestuurder: Maak Proxy Bestuur makliker
Die bestuur van verskeie gevolmagtigdes kan moeilik wees, maar Proxy Manager maak dit maklik.
Hierdie oopbron-koppelvlak stel jou in staat om al jou gevolmagtigdes vanaf 'n enkele platform te bestuur. Sê totsiens om gevolmagtigdes handmatig in te stel en om te skakel. Proxy Manager vereenvoudig die prosedure en bespaar jou tyd en moeite.
Proxy-blaaieruitbreiding: Verander jou ligging maklik
Moet jy webdata van verskeie streke insamel? Jy word gedek deur ons Proxy Browser-uitbreiding. Jy kan jou blaaierligging verander met 'n enkele klik om streekspesifieke inligting te verkry.
Maak gebruik van die buigsaamheid en eenvoud van die insameling van data uit verskeie streke sonder enige tegnologiese komplikasies.
Hoe werk dit? - Tutoriaal
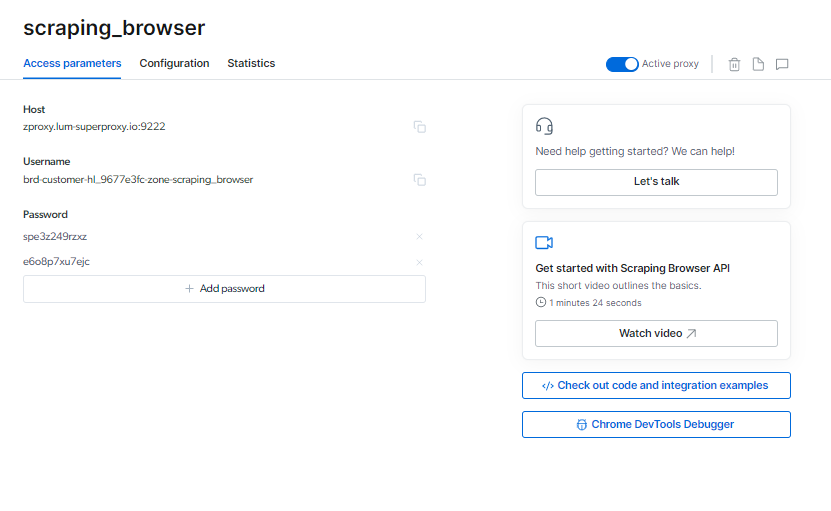
Jy kan jou Skraapblaaier aanmeldinligting op die Toegangsparameters-bladsy, wat gebruik sal word wanneer jy 'n nuwe blaaiersessie begin.
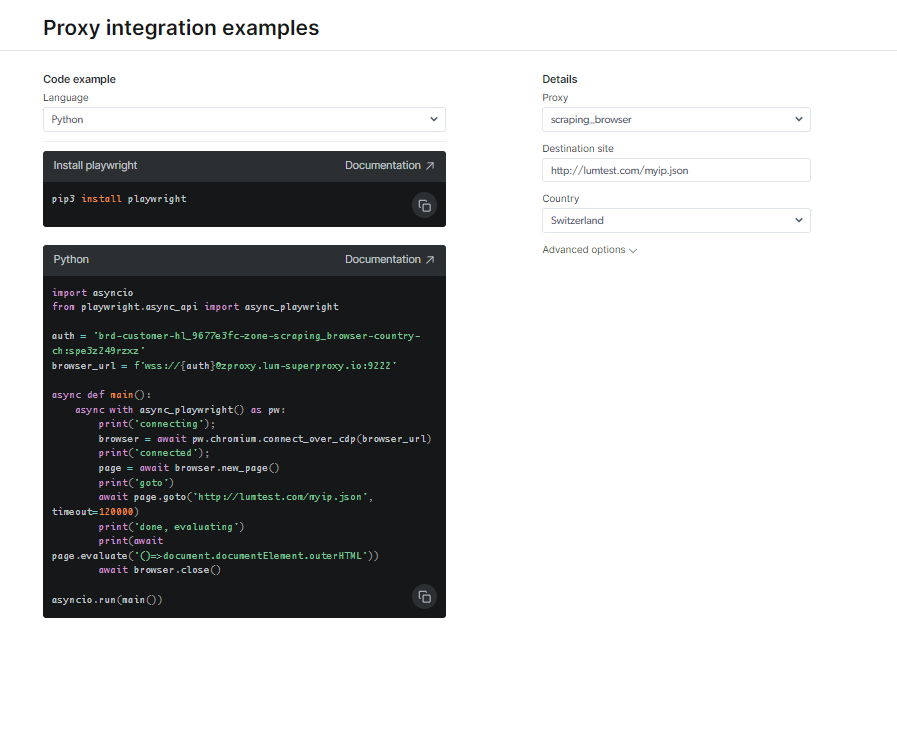
Kyk na dokumentasie en kodevoorbeelde, insluitend 'n ten volle funksionele voorbeeldskrif wat gereed is om te gebruik, of kyk na 'n kort begin-instruksievideo. Byvoorbeeld; hier is 'n Python-kode voorbeeld vir integrasie:
Wil jy hulp hê? Vir 'n gesprek met een van die spesialiste, kan jy op die kletsikoon klik.
Hou in gedagte dat jy volle beheer oor die blaaiersessies het terwyl jy Scraping Browser gebruik en enige bewerking kan uitvoer wat ondersteun word deur Puppeteer, Playwright of direkte Chrome DevTools Protocol gebruik.
Webwerf ontsluit sonder blokke
Scraping Browser is gemaak om op skaal en soos nodig te werk. Jy hoef nie bekommerd te wees dat jy verban word nie; jy kan soveel blaaiersessies begin as wat jy nodig het.
Hierdie kapasiteit, wanneer dit gepaard gaan met die sterkte van gevolmagtigdes, waarborg deurlopende data-insameling, wat jou in staat stel om effektief die data te bekom wat jy wil hê.
Scraping Browser se ingeboude ontsluitvaardighede en robuuste proxy-netwerk help jou om tyd te bespaar, produktiwiteit te verbeter en nuwe geleenthede te ontdek.
U kan ook die statistieke direk vanaf dieselfde bladsy nagaan.
Pryse van skraapblaaier
Bright Data bied aanpasbare pryskeuses om aan 'n verskeidenheid doeleindes te voldoen. Jy kan óf 'n maandelikse óf 'n jaarlikse faktuurtydperk kies.
Die Pay as You Go-opsie laat jou toe om net te betaal vir wat jy gebruik, sonder enige verpligting nodig, vanaf $20.00/GB en $0.1/uur.
Die $500-groeiplan is geskik vir besighede wat groei, met 'n afslagfooi van $15.30/GB en $0.1/uur.
Die Besigheidspakket, wat $1000 kos, is die gewildste opsie, met die Scraping Browser API wat $13.50/GB en $0.1/uur kos.
Deur die Bright Data-span direk te kontak, kan ondernemingsgebruikers oneindige skaal en persoonlike pryse geniet. Begin vandag 'n gratis proeflopie om die potensiaal van Bright Data se skraapblaaier te ontdek en jou aanlyn skraappogings te verander.
Webwerf-ontsluiter
Web Unlocker is 'n kragtige instrument wat geskep is om verby webwerfbeperkings te kom en maklike data-oes te bied. Dit oorkom verskeie uitdagings, insluitend koekies, werfspesifieke blaaiergebruikersagente en captcha-oplossings, deur geoutomatiseerde prosedures te gebruik.
Deur outomatiese IP-adresrotasie te gebruik, kan gebruikers van Web Unlocker voortdurend teikenwebwerwe skraap, wat konstante toegang tot belangrike data verseker.
Verbetering van ontwikkelaarversoekreise
Verskeie kenmerke maak Web Unlocker gewild onder ontwikkelaars. Die program stroomlyn die data-insamelingsproses deur outomaties die gebruikersagente wat vir elke webwerf benodig word te identifiseer, wat waardevolle tyd en hulpbronne bespaar.
Web Unlocker pas intyds aan om opsporing te vermy in reaksie op die voortdurend veranderende strategieë wat gebruik word deur bots te blokkeer, wat deurlopende toegang tot die webwerwe van belang verseker. Die platform se masjienleeralgoritmes kan captchas vinnig oplos, 'n gereelde struikelblok vir inisiatiewe vir data-insameling.

Pryse van Web Unlocker
Web Unlocker begin by ongeveer $2.03 per duisend versoeke (CPM), en bied verskeie prysopsies om aan verskillende eise te voldoen. 'n Gratis proeftydperk van 7 dae is beskikbaar vir gebruikers om hulle aan die gang te kry en om hulle Web Unlocker se kenmerke te laat toets voordat hulle oorgaan.
Web Unlocker het die aanpasbaarheid om verskeie gebruikspatrone te ondersteun, ongeag of verbruikers 'n betaal-soos-jy-gaan-benadering wil hê of 'n pasgemaakte plan benodig wat by hul spesifieke vereistes pas. Daarbenewens kan diegene wat langtermyn-prysplanne kies 32% bespaar.
Vergelyking tussen Web Unlocker met selfbestuurde gevolmagtigdes
Web Unlocker bied talle onmiddellike voordele bo selfbestuurde gevolmagtigdes. Vir gladde implementering bied dit 'n uitgebreide integrasietegniek wat superinstaanbediener- en Proxybestuurder-funksies kombineer. Gebruikers kan hul data-insamelingsbedrywighede effektief opskaal met 'n oneindige aantal gelyktydige verbindings.
Web Unlocker lewer outomatiese deblokkering, los CAPTCHA's op en bestuur opmerkwysigings suksesvol op teikenwebwerwe.
Die platform waarborg deurlopende en betroubare data-onttrekking deur 'n outomatiese herproberingstelsel te implementeer en asynchrone oproepe vir sekere domeine te maak. Boonop laat aanlyn Unlocker se groeiende versameling HTTP-kopversoeke, werfspesifieke blaaierkoekies en gesimuleerde toestelle gebruikers onopgemerk bly terwyl dit hulle in staat stel om aanlyndata intyds te bekom.
Finale gedagtes en belangrike dinge om te onthou
Ten slotte, terwyl u Bright Data vir Instagram-skraap gebruik, is dit van kritieke belang om 'n paar belangrike punte in gedagte te hou.
Neem asseblief kennis dat hul skraapvermoë beperk is tot publiek beskikbare data, deur etiese praktyke.
Jy moet altyd Instagram se diensbepalings en privaatheidsbeleide volg. Skraping moet eties en verantwoordelik gedoen word, sonder om inbreuk te maak op die regte van gebruikers of enige wette te oortree.
Tweedens, dateer en verfyn jou skraapparameters gereeld om die akkuraatheid en relevansie van die opgespoorde data te verseker. Instagram se platform en algoritmes is onderhewig aan verandering, daarom moet jy jou skraapstrategieë dienooreenkomstig verander.
Ten slotte, gebruik Bright Data se platform se hulp en hulpbronne om die sukses van jou Instagram-skraappogings te optimaliseer. Raak betrokke by hul dokumentasie, tutoriale en kliëntediens om jou kennis van hul skraapgereedskap te verbeter.
Jy kan nuttige insigte kry, wyse besluitneming beïnvloed en suksesvol wees in jou data-gedrewe inisiatiewe op die Instagram-platform deur hierdie beste praktyke te volg en die krag van Bright Data se Instagram-skraapvermoëns te gebruik.





Lewer Kommentaar