INHOUDSOPGAWE[Versteek][Wys]
Data is oral om jou. In 'n werklike sin beïnvloed dit elke aspek van jou besigheid. Dit kan voel asof daar nie genoeg tyd is om die besonderhede te ondersoek van hoe goed dit jou besigheid dien wanneer jy besig is met besluite oor hoe om jou data te hanteer nie.
Neem dit waar. Jou organisasie gebruik data 24 uur per dag. Om te verstaan waar dit vandaan kom, hoe dit daar gekom het en hoe dit deur die maatskappy beweeg, is dus noodsaaklik om die waarde daarvan te verstaan.
Datalyn word in hierdie situasie belangrik. Dit is makliker om te verstaan hoe data gevorm is, waar dit vandaan kom en waarheen dit gaan wanneer ons die oorsprong, migrasies en veranderinge van die data kan naspoor.
In hierdie pos sal ons noukeurig kyk na Data Lineage, hoe dit werk, die gebruiksgevalle daarvan, tegnieke en nog baie meer.
Wat is Data Lineage?
Data-afkoms dien as 'n soort digitale paspoort. Dit is die mees omvattende weergawe van 'n datareis, wat al sy stops, ompaaie en wysigings van sy oorsprong tot sy uiteindelike bestemming uiteensit.
IIn wese beskryf datalyn die oorsprong, wysiging en gebruik van 'n stuk data oor baie stelsels en platforms. Dit funksioneer as 'n speurder se hulpmiddel deur gebruikers inligting te gee oor hoe data geproduseer is, waar dit vandaan kom en hoe dit gebruik is. Hierdie inligting stel gebruikers in staat om enige potensiële probleme te herken en op te los.
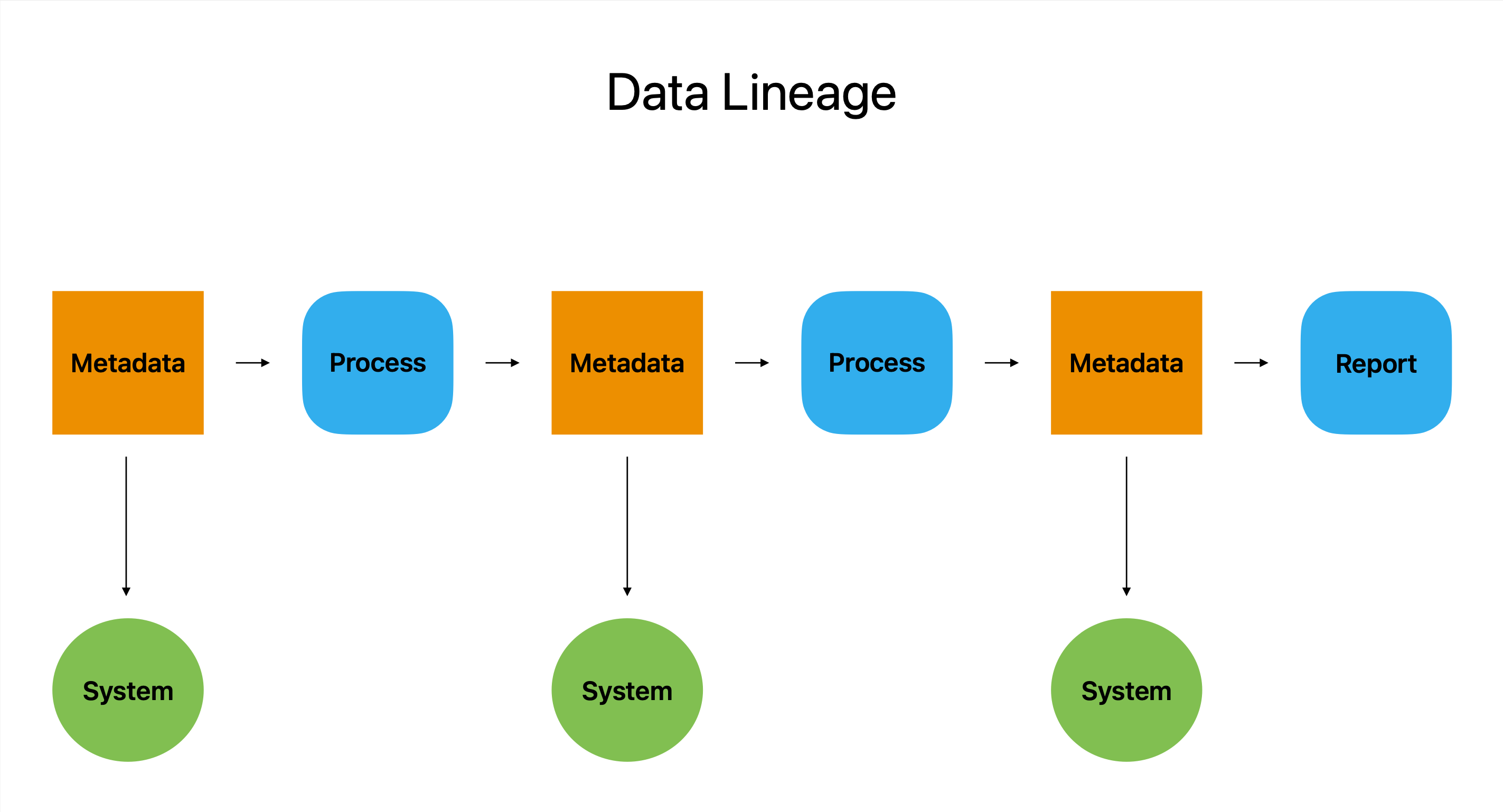
Data-afkoms is 'n onskatbare hulpbron vir maatskappye wat afhanklik is van data om hul bedrywighede uit te voer, want dit laat gebruikers toe om te reageer op belangrike vrae soos wie, wat, wanneer en waar.
Datalyn is, om dit eenvoudig te stel, die uiteindelike dataspoor wat data akkuraatheid, volledigheid en konsekwentheid waarborg terwyl dit 'n duidelike en bondige perspektief van 'n data se volle pad bied.
Hoe werk Data Lineage?
Datalyn is die padkaart wat ons in staat stel om 'n stukkie data vanaf sy beginpunt tot by sy eindpunt te volg. Beskou 'n datapunt as 'n reisiger, en sy paspoort as sy datalyn om beter te verstaan hoe dit funksioneer.
Databronne, datatransformasie, databerging en data-uitvoer vorm die paspoort se vier primêre komponente.
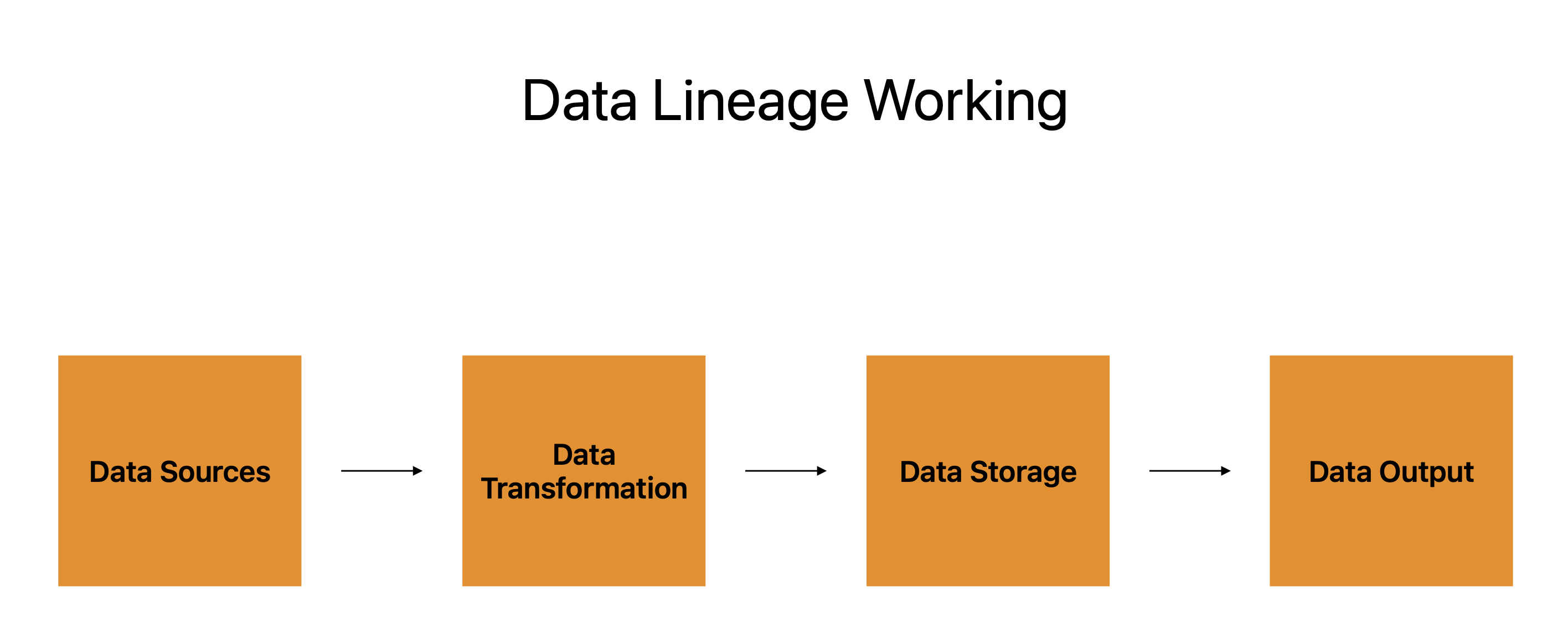
Die talle stelsels, toepassings en platforms waaruit die data afkomstig is, word deur databronne verteenwoordig, wat as die beginpunte vir die data se reis dien. Datatransformasie is die daaropvolgende stadium, en data-afkoms kaarte die data se vordering vanaf hierdie bronne na dit.
Datatransformasie verwys na die vorming, wysiging en manipulering van data om aan gebruikersbehoeftes te voldoen. Dit funksioneer as 'n rusplek tydens die data se reis, wat dit voorberei vir die volgende been.
Die data word dan gestoor voordat dit na die finale ligging daarvan gaan. Dit kan op wolkbedieners, databasisse of 'n ander soort bergingstoestel gehou word. Data-lyn hou tred met waar die data gestoor word, asook hoe dit beskerm, gerugsteun en herstel word.
Die laaste stap is data-uitvoer, dit is waarheen die data gestuur word om gebruik te word. Verslae, infografika of enige ander tipe dataproduk kan gebruik word om dit aan te bied. Data-lyn hou tred met die uitset en waarborg die konsekwentheid, akkuraatheid en volledigheid van die data.
Datalyn werk basies deur elke stadium van die data se reis op te teken, van die begin tot die uitvoer daarvan, en om seker te maak dat dit betroubaar, konsekwent en regdeur bly. Datalyn help organisasies om opgevoede besluite te neem, probleme op te los en wetlike verpligtinge na te kom deur 'n volledige oorsig van 'n data se bestaan te gee.
Om die databates te verstaan en hoe dit deur die datapyplyn beweeg, is metadata 'n deurslaggewende deel van die datalynproses.
U kan sien hoe data binne die organisasie omgeskakel en gebruik word deur gebruik te maak van datalyninstrumente, wat metadata gebruik om 'n visuele uitbeelding van die datavloei te verskaf. Dit stel gebruikers in staat om die data se potensiaal te assesseer en help hulle om beter ingeligte besluite te neem.
Tipes datalyn
Daar is drie basiese vorme van data-lyn: voorwaartse data-lyn, terugwaartse data-lyn en tweerigting data-lyn.
Voorstuur datalyn
Soos met 'n eenrigtingstraat, behels voorwaartse datalyn die dop van 'n stuk data vanaf sy beginpunt tot by sy eindpunt. Vanaf die databron, volg dit die data terwyl dit deur verskeie transformasies en bergingstelsels gaan om die uitset daarvan te bereik.
Begrip van die verwerking en transformasie van data sowel as enige probleme wat langs die pad mag ontstaan het, word vergemaklik deur 'n datalyn van hierdie soort te hê. Elke tree lei na die volgende; dit is soos om 'n spoor van broodkrummels te volg.
Agterwaartse datalyn
Agterwaartse datalyn is soortgelyk aan 'n reis in omgekeerde rigting waar ons die data se uitset na sy bron terugspoor. Die proses begin by die data se finale ligging en beweeg agteruit deur 'n verskeidenheid bergings- en transformasietegnieke totdat dit die databron bereik.
Identifikasie van die oorspronklike bron van die data, begrip van die transformasie daarvan en verifiëring van die korrektheid en volledigheid daarvan is alles moontlik met behulp van hierdie soort datalyn. Dit werk soos 'n speurder se instrument, wat ons in staat stel om die pad van die data agteruit te volg.
Tweerigting datalyn
'n Tweerigting-straat, tweerigting-datalyn kombineer die voordele van vorentoe en agtertoe data-lyn. Dit bied 'n omvattende oorsig van die roete van die data deur dit op te spoor vanaf sy bron tot sy bestemming sowel as van daardie ligging tot by sy beginpunt.
Om die oorspronklike bron van die data te bepaal, te begryp hoe dit verander is en die kwaliteit, konsekwentheid en volledigheid daarvan te verseker, is dit nuttig om die data se afkoms na te spoor. Met intydse inligting oor sy ligging en status, is dit soos om 'n GPS-spoorsnyer vir data te hê.
Implementering van Data Lineage
Die implementering van datalyn in 'n organisasie behels gereeld die volgende fases.
Definieer die databronne
Die stelsels en databasisse wat die data bevat wat jy wil opspoor, moet almal geïdentifiseer word. Om dit te doen, moet jy eers die verskillende databronne identifiseer, insluitend lêers, API's en wolkdienste.
Versamel die metadata
Die volgende fase is om besonderhede oor die data te bekom, insluitend die ligging, formaat en organisasie daarvan. Om die kenmerke van die data te verstaan en hoe dit gebruik word, word deur hierdie metadata moontlik gemaak.
Identifiseer datafoute
Dit is makliker om te verstaan hoe data opgedateer en gebruik word binne die organisasie as die vloei van data gekarteer word vanaf die bron tot by die bestemming, insluitend enige transformasies of verwerking wat langs die roete plaasvind.
Volg datatoegang
Om datasekuriteit en -nakoming te handhaaf, spoor en teken aan wie toegang tot die data het.
Stoor en visualiseer die afkoms
Gebruik visualiseringsinstrumente om die afkoms aan te bied vir eenvoudige begrip en ontleding. Stoor die versamelde metadata en datavloeiinligting in 'n enkele bewaarplek.
Implementeer 'n outomatiese oplossing
U kan verifieer dat datalyn deur outomatisering ingesamel en gemonitor word, wat ook sal help om foute te verminder en produktiwiteit te verhoog.
Hersien en opdatering
Maak dat die geslagsrekords op 'n gereelde basis korrek en aktueel is, en werk dit op soos toepaslik.
Die implementeringsproses moet dalk gewysig of by fases gevoeg word, afhangende van die unieke vereistes en limiete van elke organisasie.
Data Lineage Tegnieke
Patroon-gebaseerde afkoms
Met hierdie metode word afstamming uitgevoer sonder om interaksie te hê met die programmering wat die data gegenereer of getransformeer het. Metadata-assessering vir tabelle, kolomme en besigheidsverslae is alles deel daarvan. Dit ondersoek afstamming deur te soek na tendense deur hierdie metadata te gebruik.
Byvoorbeeld, dit is heel waarskynlik dat 'n kolom in twee datastelle met dieselfde naam en identiese datawaardes dieselfde data in verskillende fases van sy bestaan verteenwoordig. 'n Datalyngrafiek word dan gebruik om daardie twee kolomme te verbind.
Patroongebaseerde afkoms het die beduidende voordeel dat dit tegnologie-onafhanklik is omdat dit net data nagaan, nie dataverwerkingsmetodes nie. Enige databasistegnologie, insluitend Oracle, MySQL en Spark, kan dit op dieselfde manier implementeer. Die nadeel is dat hierdie benadering nie altyd presies is nie.
Wanneer die dataverwerkingslogika in die rekenaarkode versteek is en nie maklik in mensleesbare metadata duidelik sigbaar is nie, kan dit soms verwantskappe tussen datastelle miskyk.
Afstamming deur Data Tagging
Hierdie metode is gebaseer op die idee dat 'n transformasie-enjin data merk of andersins merker. Dit volg die merker van begin tot einde om afkoms te vind. Hierdie benadering kan slegs suksesvol wees as jy 'n betroubare transformasie-instrument het wat alle data-oordrag bestuur en jy vertroud is met die merkstruktuur wat die instrument gebruik.
Selfs as so 'n instrument sou bestaan, kan geen data wat daarsonder geskep of verander is, aan afstamming onderwerp word deur data-tagging nie. Dit is in hierdie verband beperk tot die uitvoering van datalyn op geslote datastelsels.
Selfstandige afkoms
Sommige besighede het 'n data-omgewing wat metadataberging, verwerkingslogika en meesterdatabestuur (MDM) insluit. Hierdie instellings sluit dikwels a data meer waar alle data gedurende sy hele leeftyd bewaar word.
Afstamming kan natuurlik verskaf word deur hierdie soort selfstandige stelsel sonder die vereiste vir bykomende hulpbronne. Net soos met die datamerkmetode, sal afstamming egter nie bewus wees van enigiets wat buite hierdie gereguleerde omgewing voorkom nie.
Data-afstamming deur ontleding
Die mees gesofistikeerde soort geslag is een wat dataverwerkingslogika outomaties lees. Vir deeglike, end-tot-end nasporing, hierdie metode reverse engineer die data transformasie logika.
Aangesien hierdie oplossing al die programmeringstale en gereedskap wat gebruik word om die data om te skakel en te vervoer, is die ontplooiing daarvan ingewikkeld. Dit kan gebruik maak van extract-transform-load (ETL) logika, SQL- en Java-gebaseerde oplossings, ou dataformate, XML-gebaseerde oplossings en ander tegnieke.
Data-afkomsgebruiksgevalle
Datamodellering
Maatskappye moet die onderliggende datastrukture vestig wat hulle ondersteun om die baie data-items en die verbande tussen hulle binne 'n maatskappy te visualiseer. Hierdie verbindings word gemodelleer deur gebruik te maak van datalyn, wat ook die baie afhanklikhede wat in die data-ekosisteem teenwoordig is, toon.
Aangesien data met verloop van tyd verander, verskyn voortdurend nuwe databronne, wat nuwe data-integrasies vereis, ens. As gevolg hiervan moet ondernemings se algemene datamodelle vir die bestuur van hul data eweneens verander om die omgewing te weerspieël.
Compliance
Data-lyn bied 'n nakomingsmetode vir ouditering, die verbetering van risikobestuur en om seker te maak dat data gehou en hanteer word in ooreenstemming met databestuursbeleide en -wette.
Impakanalise
Die uitwerking van sekere besigheidsveranderinge, soos enige stroomaf-verslaggewing, kan gesien word deur gebruik te maak van datalyn-instrumente. Data-afkoms, byvoorbeeld, kan bestuurders help om te bepaal hoeveel kontroleskerms 'n naamsverandering sal raak en, gevolglik, hoeveel mense toegang tot daardie verslagdoening kry.
Datamigrasie
Organisasies gebruik datamigrasie om te verstaan waar die data geleë is en hoe lank dit daar is voordat dit na 'n nuwe bergingstelsel verskuif word of nuwe sagteware geïmplementeer word.
Datalyn help spanne om voor te berei vir stelselopgraderings of -migrasies deur hulle 'n oorsig te gee van hoe die data deur die organisasie beweeg het. Dit versnel die oordrag na die nuwe bergingsomgewing in die algemeen.
Boonop gee dit spanne die kans om die datastelsel te ontklouter deur verouderde of nuttelose data te argiveer of uit te skakel. Deur dit te doen, sal die datastelsel in die algemeen beter presteer en minder bestuur van data benodig.
Uitdagings van die implementering van datalyn
- Datasekuriteit: Datasekuriteit is 'n primêre bekommernis tydens die bou van data-afkoms. Om 'n datareis vanaf sy beginpunt tot sy eindbestemming te volg, moet toegang tot sensitiewe data verleen word, en hierdie data moet beskerm word teen ongemagtigde toegang en oortredings.
- Gebrek aan standaardisering: Een van die primêre hindernisse om data-afkoms te omhels is die gebrek aan standaarde. Aangesien baie platforms, toepassings en stelsels unieke metodes gebruik om data-herkoms op te spoor en aan te teken, kan dit moeilik wees om 'n samehangende prentjie van 'n datareis saam te stel.
- Datasilo's: Datasilo's is nog 'n probleem wat ontstaan tydens die implementering van datalyn. Wanneer data oor verskeie toepassings en stelsels versprei word, kan dit uitdagend wees om die reis van die een na die ander na te spoor. Dit kan lei tot onakkurate of onvolledige datalyn.
Gevolgtrekking
Ten slotte, data-afkoms is 'n noodsaaklike deel van elke data-gedrewe onderneming. Dit bied 'n omvattende perspektief van 'n data se pad vanaf sy beginpunt tot sy eindpunt, wat die akkuraatheid, volledigheid en konsekwentheid daarvan waarborg.
Toekomstige outomatisering en standaardisering van datalyn sal na verwagting toeneem, wat implementering en instandhouding vir organisasies makliker maak. Uiteindelik kan die belangrikheid van datalyn nie beklemtoon word nie.
Dit gee maatskappye die gereedskap wat hulle nodig het om wyse keuses te maak, hul bedrywighede meer doeltreffend te bestuur en sukses te behaal.





Lewer Kommentaar