KI is oral, maar soms kan dit uitdagend wees om die terminologie en jargon te verstaan. In hierdie blogpos verduidelik ons meer as 50 KI-terme en -definisies sodat jy meer sin kan maak van hierdie vinnig groeiende tegnologie.
Of jy nou 'n beginner of 'n kenner is, ons wed dat daar 'n paar terme hier is wat jy nie ken nie!
1. Kunsmatige intelligensie
Kunsmatige Intelligensie (AI) verwys na die ontwikkeling van rekenaarstelsels wat die vermoë het om onafhanklik te leer en te funksioneer, dikwels deur menslike intelligensie na te boots.
Hierdie stelsels ontleed data, herken patrone, neem besluite en pas hul gedrag aan op grond van ervaring. Deur gebruik te maak van algoritmes en modelle, beoog KI om intelligente masjiene te skep wat in staat is om hul omgewing waar te neem en te verstaan.
Die uiteindelike doel is om masjiene in staat te stel om take doeltreffend uit te voer, uit data te leer en kognitiewe vermoëns soortgelyk aan mense te vertoon.
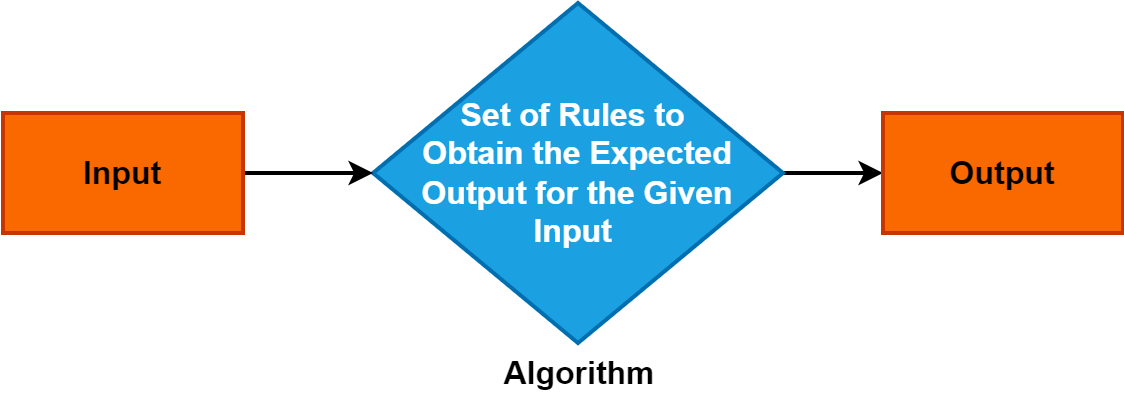
2. Algoritme
'n Algoritme is 'n presiese en sistematiese stel instruksies of reëls wat die proses lei om 'n probleem op te los of om 'n spesifieke taak uit te voer.
Dit dien as 'n fundamentele konsep in verskeie domeine en speel 'n deurslaggewende rol in rekenaarwetenskap, wiskunde en probleemoplossingsdissiplines. Om algoritmes te verstaan is van kardinale belang aangesien dit doeltreffende en gestruktureerde probleemoplossingsbenaderings moontlik maak, wat vordering in tegnologie en besluitnemingsprosesse aandryf.
3. Groot data
Groot data verwys na uiters groot en komplekse datastelle wat die vermoëns van tradisionele ontledingsmetodes oorskry. Hierdie datastelle word tipies gekenmerk deur hul volume, snelheid en verskeidenheid.
Volume verwys na die groot hoeveelheid data wat uit verskeie bronne gegenereer word, soos sosiale media, sensors en transaksies.
Snelheid verwys na die hoë spoed waarteen data gegenereer word en intyds of byna intyds verwerk moet word. Verskeidenheid dui op die diverse tipes en formate van data, insluitend gestruktureerde, ongestruktureerde en semi-gestruktureerde data.
4. Datamynbou
Data-ontginning is 'n omvattende proses wat daarop gemik is om waardevolle insigte uit groot datastelle te onttrek.
Dit sluit vier sleutelfases in: data-insameling, wat die insameling van relevante data behels; datavoorbereiding, die versekering van datakwaliteit en versoenbaarheid; die ontginning van die data, die gebruik van algoritmes om patrone en verwantskappe te ontdek; en data-analise en interpretasie, waar die onttrekte kennis ondersoek en verstaan word.
5. Neurale netwerk
'n Rekenaarstelsel is ontwerp om te werk soos die menslike brein, saamgestel uit onderling gekoppelde nodusse of neurone. Kom ons verstaan dit 'n bietjie meer soos die meeste AI gebaseer is neurale netwerke.
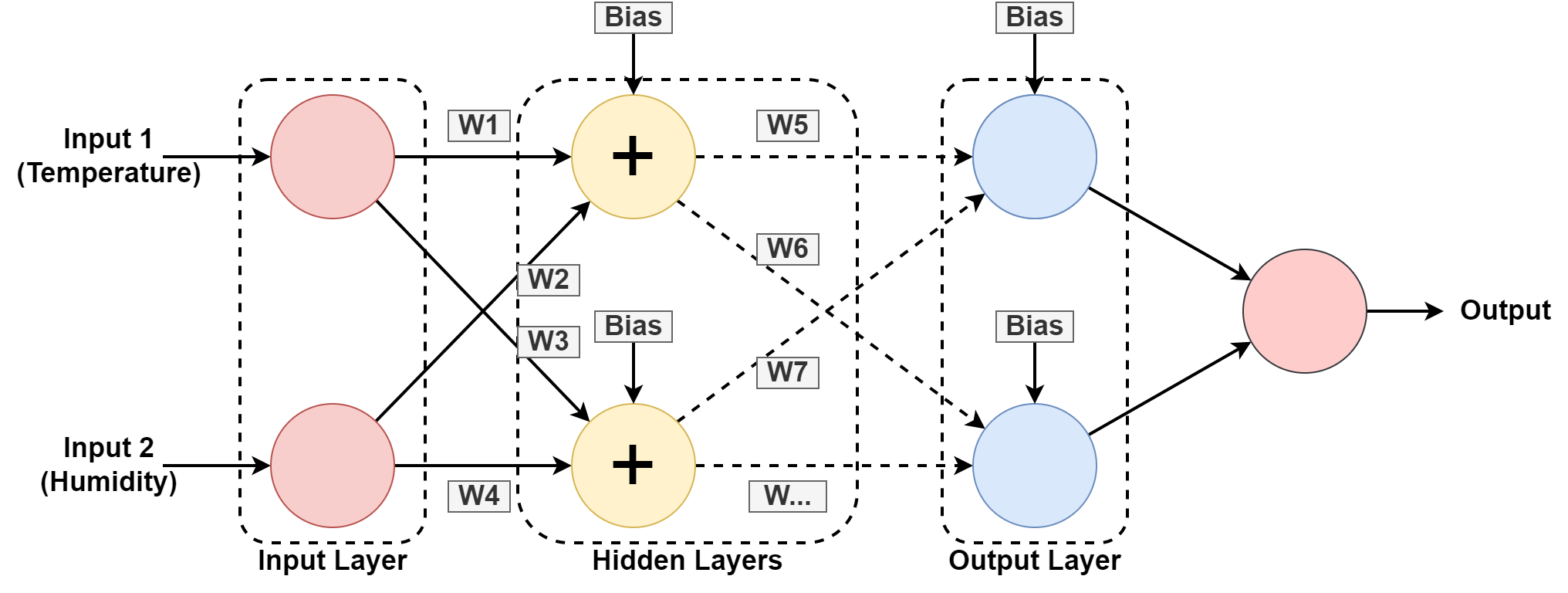
In die bogenoemde grafika voorspel ons die humiditeit en temperatuur van 'n geografiese ligging deur uit die verlede patroon te leer. Die insette is die datastel vir die vorige rekord.
Die neurale netwerk leer die patroon deur met gewigte te speel en vooroordeelwaardes in die versteekte lae toe te pas. W1, W2….W7 is die onderskeie gewigte. Dit lei homself op die datastel wat verskaf word en gee uitset as 'n voorspelling.
Jy kan dalk oorweldig word deur hierdie komplekse inligting. As dit die geval is, kan jy begin met ons eenvoudige gids na hierdie skakel.
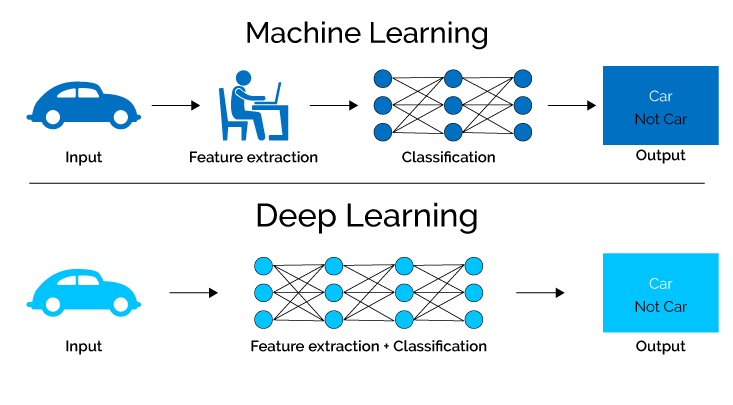
6. Masjienleer
Masjienleer fokus op die ontwikkeling van algoritmes en modelle wat in staat is om outomaties uit data te leer en hul werkverrigting met verloop van tyd te verbeter.
Dit behels die gebruik van statistiese tegnieke om rekenaars in staat te stel om patrone te identifiseer, voorspellings te maak en data-gedrewe besluite te neem sonder om uitdruklik geprogrammeer te word.
Masjienleer-algoritmes analiseer en leer uit groot datastelle, sodat stelsels hul gedrag kan aanpas en verbeter op grond van die inligting wat hulle verwerk.
7. Diep leer
Diep leer, 'n subveld van masjienleer en neurale netwerke, maak gebruik van gesofistikeerde algoritmes om kennis uit data te verkry deur die ingewikkelde prosesse van die menslike brein te simuleer.
Deur neurale netwerke met talle versteekte lae te gebruik, kan diepleermodelle outonoom ingewikkelde kenmerke en patrone onttrek, wat hulle in staat stel om komplekse take met buitengewone akkuraatheid en doeltreffendheid aan te pak.
8. Patroonherkenning
Patroonherkenning, 'n data-ontledingstegniek, benut die krag van masjienleeralgoritmes om outonoom patrone en reëlmatighede binne datastelle op te spoor en te onderskei.
Deur gebruik te maak van berekeningsmodelle en statistiese metodes, kan patroonherkenningsalgoritmes betekenisvolle strukture, korrelasies en neigings in komplekse en diverse data identifiseer.
Hierdie proses maak die onttrekking van waardevolle insigte, klassifikasie van data in afsonderlike kategorieë en voorspelling van toekomstige uitkomste moontlik gebaseer op erkende patrone. Patroonherkenning is 'n noodsaaklike hulpmiddel oor verskeie domeine, wat besluitneming, anomalie-opsporing en voorspellende modellering bemagtig.
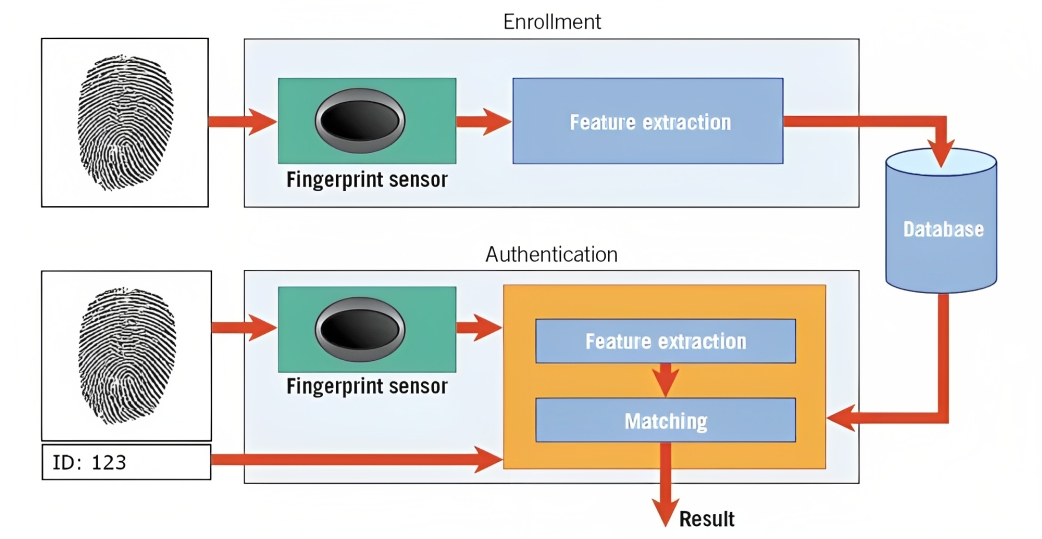
Biometrie is een voorbeeld hiervan. Byvoorbeeld, in vingerafdrukherkenning, ontleed die algoritme die rante, kurwes en unieke kenmerke van 'n persoon se vingerafdruk om 'n digitale voorstelling te skep wat 'n sjabloon genoem word.
Wanneer jy probeer om jou slimfoon te ontsluit of toegang tot 'n veilige fasiliteit te kry, vergelyk die patroonherkenningstelsel die vasgelegde biometriese data (bv. vingerafdruk) met die gestoor sjablone in sy databasis.
Deur die patrone te pas en die vlak van ooreenkoms te bepaal, kan die stelsel bepaal of die verskafde biometriese data by die gestoorde sjabloon pas en dienooreenkomstig toegang verleen.
9. Leer onder toesig
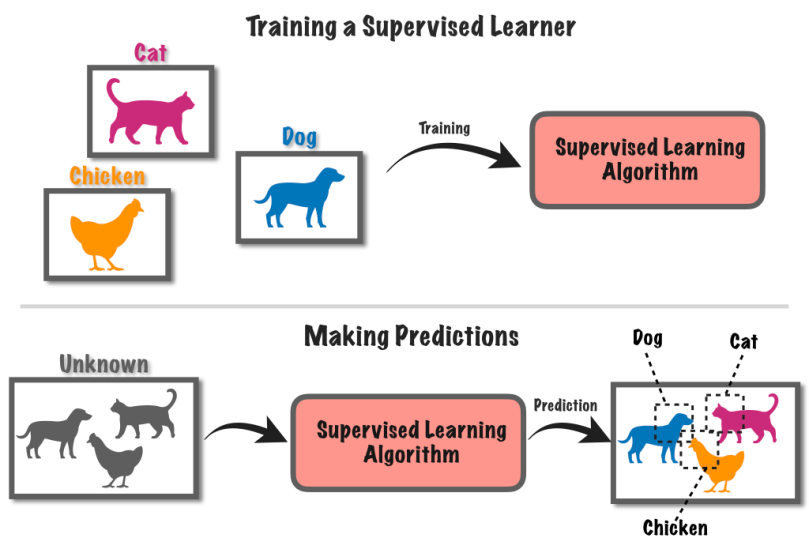
Leer onder toesig is 'n masjienleerbenadering wat die opleiding van 'n rekenaarstelsel behels deur gebruik te maak van gemerkte data. In hierdie metode word die rekenaar voorsien van 'n stel invoerdata saam met ooreenstemmende bekende byskrifte of uitkomste.
Kom ons sê jy het 'n klomp foto's, sommige met honde en ander met katte.
Jy vertel die rekenaar watter prente het honde en watter het katte. Die rekenaar leer dan om die verskille tussen honde en katte te herken deur patrone in die prente te vind.
Nadat dit geleer het, kan jy die rekenaar nuwe prente gee, en dit sal probeer om uit te vind of hulle honde of katte het op grond van wat dit uit die benoemde voorbeelde geleer het. Dit is soos om 'n rekenaar op te lei om voorspellings te maak deur bekende inligting te gebruik.
10. Leer sonder toesig
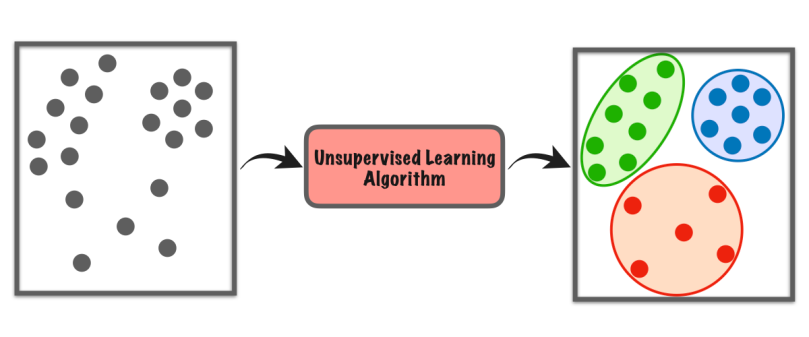
Leer sonder toesig is 'n tipe masjienleer waar die rekenaar 'n datastel op sy eie verken om patrone of ooreenkomste te vind sonder enige spesifieke instruksies.
Dit maak nie staat op benoemde voorbeelde soos in leer onder toesig nie. In plaas daarvan soek dit na versteekte strukture of groepe in die data. Dit is asof die rekenaar dinge vanself ontdek, sonder dat 'n onderwyser vir hom sê waarna om te soek.
Hierdie tipe leer help ons om nuwe insigte te vind, data te organiseer of ongewone dinge te identifiseer sonder om voorafkennis of eksplisiete leiding te benodig.
11. Natuurlike taalverwerking (NLP)
Natuurlike Taalverwerking fokus op hoe rekenaars menslike taal verstaan en daarmee in wisselwerking tree. Dit help rekenaars om menslike taal te ontleed, te interpreteer en daarop te reageer op 'n manier wat vir ons natuurliker voel.
NLP is wat dit vir ons moontlik maak om met stemassistente en kletsbotte te kommunikeer, en selfs ons e-posse outomaties in dopgehou te sorteer.
Dit behels dat rekenaars geleer word om die betekenis agter woorde, sinne en selfs hele tekste te verstaan, sodat hulle ons in verskeie take kan bystaan en ons interaksies met tegnologie meer naatloos kan maak.
12. Rekenaarvisie
Rekenaarvisie is 'n fassinerende tegnologie wat rekenaars toelaat om beelde en video's te sien en te verstaan, net soos ons mense met ons oë doen. Dit gaan alles daaroor om rekenaars te leer om visuele inligting te ontleed en sin te maak van wat hulle sien.
In eenvoudiger terme, rekenaarvisie help rekenaars om die visuele wêreld te herken en te interpreteer. Dit behels take soos om hulle te leer om spesifieke voorwerpe in beelde te identifiseer, beelde in verskillende kategorieë te klassifiseer, of selfs beelde in betekenisvolle dele te verdeel.
Stel jou voor 'n selfrymotor wat rekenaarvisie gebruik om die pad en alles rondom dit te "sien".
Dit kan voetgangers, verkeerstekens en ander voertuie opspoor en opspoor, wat hulle help om veilig te navigeer. Of dink aan hoe gesigsherkenningstegnologie rekenaarvisie gebruik om ons slimfone te ontsluit of ons identiteite te verifieer deur ons unieke gelaatstrekke te herken.
Dit word ook in toesigstelsels gebruik om oorvol plekke te monitor en enige verdagte aktiwiteite op te spoor.
Rekenaarvisie is 'n kragtige tegnologie wat 'n wêreld van moontlikhede oopmaak. Deur rekenaars in staat te stel om visuele inligting te sien en te verstaan, kan ons toepassings en stelsels ontwikkel wat die wêreld rondom ons kan waarneem en interpreteer, wat ons lewens makliker, veiliger en doeltreffender maak.
13.Geselsbot
'n Chatbot is soos 'n rekenaarprogram wat met mense kan praat op 'n manier wat soos 'n regte menslike gesprek lyk.
Dit word dikwels in aanlyn kliëntediens gebruik om kliënte te help en hulle te laat voel dat hulle met 'n persoon praat, al is dit eintlik 'n program wat op 'n rekenaar loop.
Die kletsbot kan boodskappe of vrae van kliënte verstaan en daarop reageer, en bied nuttige inligting en bystand net soos 'n menslike kliëntediensverteenwoordiger.
14. Stemherkenning
Stemherkenning verwys na die vermoë van 'n rekenaarstelsel om menslike spraak te verstaan en te interpreteer. Dit behels die tegnologie wat 'n rekenaar of toestel in staat stel om na gesproke woorde te "luister" en dit om te skakel in teks of opdragte wat dit kan verstaan.
Met Stemherkenning, kan jy interaksie met toestelle of toepassings hê deur bloot met hulle te praat in plaas van om te tik of ander invoermetodes te gebruik.
Die sisteem ontleed die gesproke woorde, herken die patrone en klanke en vertaal dit dan in verstaanbare teks of handelinge. Dit maak voorsiening vir handvrye en natuurlike kommunikasie met tegnologie, wat take soos stemopdragte, diktee of stembeheerde interaksies moontlik maak. Die mees algemene voorbeelde is die KI-assistente soos Siri en Google Assistant.
15. Sentimentanalise
Sentimentanalise is 'n tegniek wat gebruik word om die emosies, opinies en houdings wat in teks of spraak uitgedruk word, te verstaan en te interpreteer. Dit behels die ontleding van geskrewe of gesproke taal om te bepaal of die sentiment wat uitgedruk word positief, negatief of neutraal is.
Deur masjienleeralgoritmes te gebruik, kan sentimentanalise-algoritmes groot hoeveelhede teksdata skandeer en ontleed, soos klantresensies, sosialemediaplasings of klantterugvoer, om die onderliggende sentiment agter die woorde te identifiseer.
Die algoritmes soek spesifieke woorde, frases of patrone wat emosies of opinies aandui.
Hierdie ontleding help besighede of individue om te verstaan hoe mense oor 'n produk, diens of onderwerp voel en kan gebruik word om data-gedrewe besluite te neem of insigte te kry in klante se voorkeure.
Byvoorbeeld, 'n maatskappy kan sentimentanalise gebruik om klanttevredenheid op te spoor, areas vir verbetering te identifiseer of die publieke mening oor hul handelsmerk te monitor.
16. Masjienvertaling
Masjienvertaling, in die konteks van KI, verwys na die gebruik van rekenaaralgoritmes en kunsmatige intelligensie om teks of spraak outomaties van een taal na 'n ander te vertaal.
Dit behels die leer van rekenaars om menslike tale te verstaan en te verwerk ten einde akkurate vertalings te verskaf. Die mees algemene voorbeeld is Google vertaal.
Met masjienvertaling kan jy teks of spraak in een taal invoer, en die stelsel sal die invoer ontleed en 'n ooreenstemmende vertaling in 'n ander taal genereer. Dit is veral nuttig wanneer u inligting oor verskillende tale kommunikeer of toegang verkry.
Masjienvertalingstelsels maak staat op 'n kombinasie van linguistiese reëls, statistiese modelle en masjienleeralgoritmes. Hulle leer uit groot hoeveelhede taaldata om die akkuraatheid van vertaling met verloop van tyd te verbeter. Sommige masjienvertalingsbenaderings sluit ook neurale netwerke in om die kwaliteit van vertalings te verbeter.
17. Robotika
Robotika is die kombinasie van kunsmatige intelligensie en meganiese ingenieurswese om intelligente masjiene genaamd robotte te skep. Hierdie robotte is ontwerp om take outonoom of met minimale menslike ingryping uit te voer.
Robotte is fisiese entiteite wat hul omgewing kan aanvoel, besluite kan neem op grond van daardie sensoriese insette en spesifieke aksies of take kan uitvoer.
Hulle is toegerus met verskeie sensors, soos kameras, mikrofone of raaksensors, wat hulle in staat stel om inligting van die wêreld rondom hulle in te samel. Met behulp van KI-algoritmes en -programmering kan robotte hierdie data analiseer, interpreteer en intelligente besluite neem om hul aangewese take uit te voer.
KI speel 'n deurslaggewende rol in robotika deur robotte in staat te stel om uit hul ervarings te leer en by verskillende situasies aan te pas.
Masjienleeralgoritmes kan gebruik word om robotte op te lei om voorwerpe te herken, omgewings te navigeer of selfs met mense te kommunikeer. Dit laat robotte toe om meer veelsydig, buigsaam en in staat te wees om komplekse take te hanteer.
18. darren
Hommeltuie is 'n soort robot wat in die lug kan vlieg of sweef sonder 'n menslike vlieënier aan boord. Hulle staan ook bekend as onbemande lugvoertuie (UAV's). Hommeltuie is toegerus met verskeie sensors, soos kameras, GPS en gyroskope, wat hulle in staat stel om data in te samel en hul omgewing te navigeer.
Hulle word op afstand beheer deur 'n menslike operateur of kan outonoom funksioneer deur vooraf geprogrammeerde instruksies te gebruik.
Hommeltuie dien 'n wye verskeidenheid doeleindes, insluitend lugfotografie en -videoografie, opmeting en kartering, afleweringsdienste, soek- en reddingsmissies, landboumonitering en selfs ontspanningsgebruik. Hulle het toegang tot afgeleë of gevaarlike gebiede wat moeilik of gevaarlik vir mense is.
19. Volgemaakte werklikheid (AR)
Augmented reality (AR) is 'n tegnologie wat die werklike wêreld met virtuele voorwerpe of inligting kombineer om ons persepsie en interaksie met die omgewing te verbeter. Dit bedek rekenaargegenereerde beelde, klanke of ander sensoriese insette op die regte wêreld, wat 'n meeslepende en interaktiewe ervaring skep.
Eenvoudig gestel, stel jou voor dat jy spesiale bril dra of jou slimfoon gebruik om die wêreld om jou te sien, maar met bykomende virtuele elemente bygevoeg.
Byvoorbeeld, jy kan jou slimfoon na 'n stadsstraat wys en virtuele wegwysers sien wat aanwysings, graderings en resensies vir nabygeleë restaurante of selfs virtuele karakters in wisselwerking met die werklike omgewing wys.
Hierdie virtuele elemente meng naatloos met die werklike wêreld, wat jou begrip en ervaring van die omgewing verbeter. Vergrote werklikheid kan gebruik word in verskeie velde soos speletjies, onderwys, argitektuur, en selfs vir alledaagse take soos navigasie of om nuwe meubels in jou huis uit te probeer voordat jy dit koop.
20. Virtuele werklikheid (VR)
Virtuele realiteit (VR) is 'n tegnologie wat rekenaargegenereerde simulasies gebruik om 'n kunsmatige omgewing te skep wat 'n persoon kan verken en mee kan kommunikeer. Dit dompel die gebruiker in 'n virtuele wêreld, blokkeer die werklike wêreld en vervang dit met 'n digitale realm.
Eenvoudig gestel, stel jou voor dat jy 'n spesiale headset opsit wat jou oë en ore bedek en jou na 'n heel ander plek vervoer. In hierdie virtuele wêreld voel alles wat jy sien en hoor ongelooflik eg, al word dit alles deur 'n rekenaar gegenereer.
Jy kan rondbeweeg, in enige rigting kyk en met voorwerpe of karakters interaksie hê asof hulle fisies teenwoordig is.
Byvoorbeeld, in 'n virtuele realiteit-speletjie kan jy jouself in 'n Middeleeuse kasteel bevind, waar jy deur sy gange kan stap, wapens kan optel en swaardgevegte met virtuele teenstanders kan deelneem. Die virtuele werklikheidsomgewing reageer op jou bewegings en aksies, wat jou ten volle verdiep en betrokke by die ervaring laat voel.
Virtuele realiteit word nie net vir speletjies gebruik nie, maar ook vir verskeie ander toepassings soos opleidingsimulasies vir vlieëniers, chirurge of militêre personeel, argitektoniese deurbrake, virtuele toerisme en selfs terapie vir sekere sielkundige toestande. Dit skep 'n gevoel van teenwoordigheid en vervoer gebruikers na nuwe en opwindende virtuele wêrelde, wat die ervaring so na as moontlik aan die werklikheid laat voel.
21. Datawetenskap
Data wetenskap is 'n veld wat die gebruik van wetenskaplike metodes, gereedskap en algoritmes behels om waardevolle kennis en insigte uit data te onttrek. Dit kombineer elemente van wiskunde, statistiek, programmering en domeinkundigheid om groot en komplekse datastelle te ontleed.
In eenvoudiger terme gaan datawetenskap daaroor om betekenisvolle inligting en patrone te vind wat binne 'n klomp data versteek is. Dit behels die insameling, skoonmaak en organisering van data en die gebruik van verskeie tegnieke om dit te verken en te ontleed. Datawetenskaplikes gebruik statistiese modelle en algoritmes om tendense te ontbloot, voorspellings te maak en probleme op te los.
Byvoorbeeld, op die gebied van gesondheidsorg kan datawetenskap gebruik word om pasiëntrekords en mediese data te ontleed om risikofaktore vir siektes te identifiseer, pasiëntuitkomste te voorspel of behandelingsplanne te optimaliseer. In besigheid kan datawetenskap op kliëntedata toegepas word om hul voorkeure te verstaan, produkte aan te beveel of bemarkingstrategieë te verbeter.
22. Data-twis
Data-wrangling, ook bekend as data-munging, is die proses om rou data in te samel, skoon te maak en te omskep in 'n formaat wat meer bruikbaar en geskik is vir ontleding. Dit behels die hantering en voorbereiding van data om die kwaliteit, konsekwentheid en versoenbaarheid daarvan met analise-instrumente of -modelle te verseker.
In eenvoudiger terme, data-twis is soos die voorbereiding van bestanddele vir kook. Dit behels die insameling van data uit verskillende bronne, uitsorteer en skoonmaak daarvan om enige foute, teenstrydighede of irrelevante inligting te verwyder.
Daarbenewens moet data dalk getransformeer, herstruktureer of saamgevoeg word om dit makliker te maak om mee te werk en insigte daaruit te onttrek.
Datatwis kan byvoorbeeld die verwydering van duplikaatinskrywings behels, die regstelling van spelfoute of formateringskwessies, die hantering van ontbrekende waardes en die omskakeling van datatipes. Dit kan ook behels om verskillende datastelle saam te voeg of saam te voeg, data in substelle te verdeel, of nuwe veranderlikes te skep gebaseer op bestaande data.
23. Data Storievertelling
Data storievertelling is die kuns om data op 'n boeiende en boeiende manier aan te bied om 'n narratief of boodskap effektief te kommunikeer. Dit behels die gebruik van data visualisasies, narratiewe en konteks om insigte en bevindinge oor te dra op 'n wyse wat verstaanbaar en onvergeetlik vir die gehoor is.
In eenvoudiger terme gaan datastorievertelling oor die gebruik van data om 'n storie te vertel. Dit gaan verder as net die aanbieding van getalle en kaarte. Dit behels die skep van 'n narratief rondom die data, die gebruik van visuele elemente en storieverteltegnieke om die data lewendig te maak en dit met die gehoor herkenbaar te maak.
Byvoorbeeld, in plaas daarvan om bloot 'n tabel van verkoopsyfers aan te bied, kan datastorievertelling die skep van 'n interaktiewe dashboard behels wat gebruikers in staat stel om die verkoopsneigings visueel te verken.
Dit kan 'n narratief insluit wat die sleutelbevindinge uitlig, die redes agter die neigings verduidelik en uitvoerbare aanbevelings voorstel gebaseer op die data.
24. Data-gedrewe besluitneming
Datagedrewe besluitneming is 'n proses om keuses te maak of aksies te neem gebaseer op die ontleding en interpretasie van relevante data. Dit behels die gebruik van data as 'n grondslag om besluitnemingsprosesse te lei en te ondersteun eerder as om net op intuïsie of persoonlike oordeel staat te maak.
In eenvoudiger terme beteken data-gedrewe besluitneming om feite en bewyse uit data te gebruik om die keuses wat ons maak in te lig en te lei. Dit behels die insameling en ontleding van data om patrone, tendense en verhoudings te verstaan en die gebruik van daardie kennis om ingeligte besluite te neem en probleme op te los.
Byvoorbeeld, in 'n besigheidsomgewing kan datagedrewe besluitneming die ontleding van verkoopsdata, klantterugvoer en markneigings behels om die mees doeltreffende prysstrategie te bepaal of areas vir verbetering in produkontwikkeling te identifiseer.
In gesondheidsorg kan dit die ontleding van pasiëntdata behels om behandelingsplanne te optimaliseer of siekte-uitkomste te voorspel.
25. Data Lake
'n Datameer is 'n gesentraliseerde en skaalbare databewaarplek wat groot hoeveelhede data in sy rou en onverwerkte vorm stoor. Dit is ontwerp om 'n wye verskeidenheid datatipes, -formate en -strukture te hou, soos gestruktureerde, semi-gestruktureerde en ongestruktureerde data, sonder die behoefte aan vooraf gedefinieerde skemas of datatransformasies.
Byvoorbeeld, 'n maatskappy kan data van verskeie bronne, soos webwerflogboeke, klanttransaksies, sosiale media-feeds en IoT-toestelle, in 'n datameer versamel en stoor.
Hierdie data kan dan vir verskeie doeleindes gebruik word, soos om gevorderde analise uit te voer, masjienleeralgoritmes uit te voer, of patrone en neigings in kliëntgedrag te ondersoek.
26. Datapakhuis
'n Datapakhuis is 'n gespesialiseerde databasisstelsel wat spesifiek ontwerp is vir die berging, organisering en ontleding van groot hoeveelhede data uit verskeie bronne. Dit is gestruktureer op 'n manier wat doeltreffende data-herwinning en komplekse analitiese navrae ondersteun.
Dit dien as 'n sentrale bewaarplek wat data van verskillende bedryfstelsels, soos transaksionele databasisse, CRM-stelsels en ander databronne binne 'n organisasie, integreer.
Die data word getransformeer, skoongemaak en in die datapakhuis gelaai in 'n gestruktureerde formaat wat vir analitiese doeleindes geoptimaliseer is.
27. Besigheidsintelligensie (BI)
Besigheidsintelligensie verwys na die proses om data in te samel, te analiseer en aan te bied op 'n manier wat besighede help om ingeligte besluite te neem en waardevolle insigte te verkry. Dit behels die gebruik van verskeie instrumente, tegnologieë en tegnieke om rou data te omskep in sinvolle, bruikbare inligting.
Byvoorbeeld, 'n besigheidsintelligensiestelsel kan verkoopsdata ontleed om die winsgewendste produkte te identifiseer, voorraadvlakke te monitor en klante se voorkeure na te spoor.
Dit kan intydse insigte verskaf oor sleutelprestasie-aanwysers (KPI's) soos inkomste, kliëntverkryging of produkprestasie, wat besighede in staat stel om data-gedrewe besluite te neem en toepaslike aksies te neem om hul bedrywighede te verbeter.
Besigheidsintelligensie-nutsgoed sluit dikwels kenmerke soos datavisualisering, ad hoc-navrae en dataverkenningsvermoëns in. Hierdie instrumente stel gebruikers in staat, soos sake ontleders of bestuurders, om met die data te kommunikeer, dit op te sny en te sny, en verslae of visuele voorstellings te genereer wat belangrike insigte en neigings uitlig.
28. Voorspellende ontleding
Voorspellende analise is die gebruik van data en statistiese tegnieke om ingeligte voorspellings of voorspellings oor toekomstige gebeure of uitkomste te maak. Dit behels die ontleding van historiese data, identifisering van patrone en die bou van modelle om toekomstige tendense, gedrag of gebeurtenisse te ekstrapoleer en te skat.
Dit het ten doel om verwantskappe tussen veranderlikes te ontbloot en daardie inligting te gebruik om voorspellings te maak. Dit gaan verder as om bloot vorige gebeure te beskryf; in plaas daarvan maak dit gebruik van historiese data om te verstaan en te antisipeer wat waarskynlik in die toekoms gaan gebeur.
Byvoorbeeld, op die gebied van finansies, kan voorspellende analise gebruik word om te voorspel voorraad pryse gebaseer op historiese markdata, ekonomiese aanwysers en ander relevante faktore.
In bemarking kan dit aangewend word om kliëntgedrag en voorkeure te voorspel, wat geteikende advertensies en persoonlike bemarkingsveldtogte moontlik maak.
In gesondheidsorg kan voorspellende analise help om pasiënte met 'n hoë risiko vir sekere siektes te identifiseer of die waarskynlikheid van hertoelating te voorspel op grond van mediese geskiedenis en ander faktore.
29. Voorskriftelike analise
Voorskriftelike analise is die toepassing van data en analise om die beste moontlike aksies te bepaal om in 'n bepaalde situasie of besluitnemingscenario te neem.
Dit gaan verder as beskrywende en predictive analytics deur nie net insigte te verskaf oor wat in die toekoms kan gebeur nie, maar ook die mees optimale manier van aksie aan te beveel om 'n gewenste uitkoms te bereik.
Dit kombineer historiese data, voorspellende modelle en optimaliseringstegnieke om verskillende scenario's te simuleer en die potensiële uitkomste van verskeie besluite te evalueer. Dit oorweeg veelvuldige beperkings, doelwitte en faktore om uitvoerbare aanbevelings te genereer wat gewenste resultate maksimeer of risiko's verminder.
Byvoorbeeld, in ketting bestuur, kan voorskriftelike analise data oor voorraadvlakke, produksiekapasiteite, vervoerkoste en klantvraag ontleed om die doeltreffendste verspreidingsplan te bepaal.
Dit kan die ideale toewysing van hulpbronne, soos voorraadopslagplekke of vervoerroetes, aanbeveel om koste te minimaliseer en tydige aflewering te verseker.
30. Data-gedrewe Bemarking
Datagedrewe bemarking verwys na die gebruik van data en analise om bemarkingstrategieë, veldtogte en besluitnemingsprosesse te dryf.
Dit behels die gebruik van verskeie bronne van data om insigte te verkry in klante se gedrag, voorkeure en tendense en die gebruik van daardie inligting om bemarkingspogings te optimaliseer.
Dit fokus op die insameling en ontleding van data vanaf verskeie raakpunte, soos webwerf-interaksies, sosiale media-betrokkenheid, kliëntedemografie, aankoopgeskiedenis, en meer. Hierdie data word dan gebruik om 'n omvattende begrip van die teikengehoor, hul voorkeure en hul behoeftes te skep.
Deur data te benut, kan bemarkers ingeligte besluite neem rakende klantsegmentering, teikening en verpersoonliking.
Hulle kan spesifieke klantsegmente identifiseer wat meer geneig is om positief op bemarkingsveldtogte te reageer en hul boodskappe en aanbiedinge daarvolgens aanpas.
Daarbenewens help datagedrewe bemarking om bemarkingskanale te optimaliseer, die doeltreffendste bemarkingsmengsel te bepaal en die sukses van bemarkingsinisiatiewe te meet.
Byvoorbeeld, 'n datagedrewe bemarkingsbenadering kan die ontleding van klantdata behels om aankoopgedrag en voorkeurpatrone te identifiseer. Op grond van hierdie insigte kan bemarkers geteikende veldtogte skep met gepersonaliseerde inhoud en aanbiedinge wat aanklank vind by spesifieke klantsegmente.
Deur deurlopende ontleding en optimalisering kan hulle die doeltreffendheid van hul bemarkingspogings meet en strategieë oor tyd verfyn.
31. Databestuur
Databestuur is die raamwerk en stel praktyke wat organisasies aanneem om die behoorlike bestuur, beskerming en integriteit van data regdeur sy lewensiklus te verseker. Dit sluit die prosesse, beleide en prosedures in wat bepaal hoe data ingesamel, gestoor, toegang verkry, gebruik en gedeel word binne 'n organisasie.
Dit het ten doel om aanspreeklikheid, verantwoordelikheid en beheer oor databates te vestig. Dit verseker dat data akkuraat, volledig, konsekwent en betroubaar is, wat organisasies in staat stel om ingeligte besluite te neem, datakwaliteit te handhaaf en aan regulatoriese vereistes te voldoen.
Databestuur behels die definisie van rolle en verantwoordelikhede vir databestuur, die daarstelling van datastandaarde en -beleide, en die implementering van prosesse om nakoming te monitor en af te dwing. Dit spreek verskeie aspekte van databestuur aan, insluitend dataprivaatheid, datasekuriteit, datakwaliteit, dataklassifikasie en datalewensiklusbestuur.
Databestuur kan byvoorbeeld die implementering van prosedures behels om te verseker dat persoonlike of sensitiewe data in ooreenstemming met toepaslike privaatheidsregulasies hanteer word, soos die Algemene Databeskermingsregulasie (GDPR).
Dit kan ook die vestiging van datakwaliteitstandaarde en die implementering van datavalideringsprosesse insluit om te verseker dat data akkuraat en betroubaar is.
32. Databeveiliging
Datasekuriteit gaan daaroor om ons waardevolle inligting veilig te hou teen ongemagtigde toegang of diefstal. Dit behels die neem van maatreëls om datavertroulikheid, integriteit en beskikbaarheid te beskerm.
In wese beteken dit om te verseker dat slegs die regte mense toegang tot ons data kan kry, dat dit akkuraat en onveranderd bly en dat dit beskikbaar is wanneer dit nodig is.
Om datasekuriteit te bereik, word verskeie strategieë en tegnologieë gebruik. Toegangskontroles en enkripsiemetodes help byvoorbeeld om toegang tot gemagtigde individue of stelsels te beperk, wat dit moeiliker maak vir buitestaanders om toegang tot ons data te kry.
Moniteringstelsels, brandmure en inbraakdetectiestelsels tree op as voogde, waarsku ons van verdagte aktiwiteite en voorkom ongemagtigde toegang.
33. Internet van Dinge
Die Internet van Dinge (IoT) verwys na 'n netwerk van fisiese voorwerpe of "dinge" wat aan die Internet gekoppel is en met mekaar kan kommunikeer. Dit is soos 'n groot web van alledaagse voorwerpe, toestelle en masjiene wat in staat is om inligting te deel en take uit te voer deur interaksie deur die internet.
In eenvoudige terme behels IoT om "slim" vermoëns te gee aan verskeie voorwerpe of toestelle wat tradisioneel nie aan die internet gekoppel was nie. Hierdie voorwerpe kan huishoudelike toestelle, draagbare toestelle, termostate, motors en selfs industriële masjinerie insluit.
Deur hierdie voorwerpe aan die internet te koppel, kan hulle data versamel en deel, instruksies ontvang en take outonoom of in reaksie op gebruikeropdragte uitvoer.
Byvoorbeeld, 'n slim termostaat kan temperatuur monitor, instellings aanpas en energieverbruikverslae na 'n slimfoontoepassing stuur. 'n Drabare fiksheidspoorder kan data oor jou fisiese aktiwiteite insamel en dit sinkroniseer met 'n wolk-gebaseerde platform vir ontleding.
34. Besluitboom
'n Besluitboom is 'n visuele voorstelling of diagram wat ons help om besluite te neem of 'n optrede te bepaal gebaseer op 'n reeks keuses of voorwaardes.
Dit is soos 'n vloeidiagram wat ons deur 'n besluitnemingsproses lei deur verskillende opsies en hul potensiële uitkomste te oorweeg.
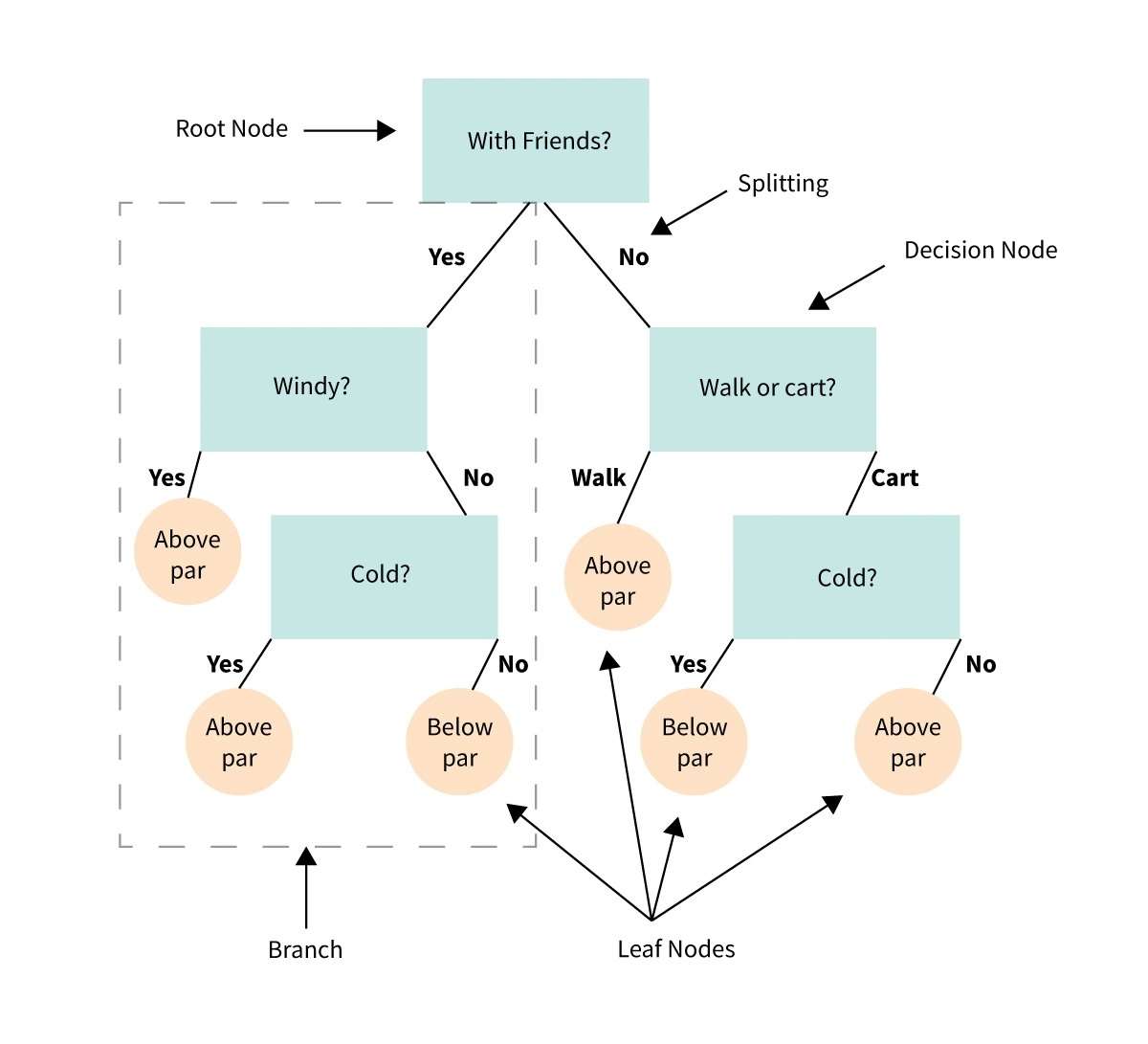
Stel jou voor jy het 'n probleem of 'n vraag, en jy moet 'n keuse maak.
'n Besluitboom breek die besluit in kleiner stappe af, wat begin met 'n aanvanklike vraag en vertak in verskillende moontlike antwoorde of aksies gebaseer op die voorwaardes of kriteria by elke stap.
35. Kognitiewe Rekenaarkunde
Kognitiewe rekenaars, in eenvoudige terme, verwys na rekenaarstelsels of tegnologieë wat menslike kognitiewe vermoëns naboots, soos leer, redenering, begrip en probleemoplossing.
Dit behels die skep van rekenaarstelsels wat inligting kan verwerk en interpreteer op 'n manier wat soos menslike denke lyk.
Kognitiewe rekenaars het ten doel om masjiene te ontwikkel wat mense op 'n meer natuurlike en intelligente manier kan verstaan en met mense kan kommunikeer. Hierdie stelsels is ontwerp om groot hoeveelhede data te ontleed, patrone te herken, voorspellings te maak en betekenisvolle insigte te verskaf.
Dink aan kognitiewe rekenaars as 'n poging om rekenaars meer soos mense te laat dink en op te tree.
Dit behels die benutting van tegnologieë soos kunsmatige intelligensie, masjienleer, natuurlike taalverwerking en rekenaarvisie om rekenaars in staat te stel om take uit te voer wat tradisioneel met menslike intelligensie geassosieer is.
36. Berekeningsleerteorie
Computational Learning Theory is 'n gespesialiseerde tak binne die gebied van kunsmatige intelligensie wat wentel om die ontwikkeling en ondersoek van algoritmes wat spesifiek ontwerp is om uit data te leer.
Hierdie veld ondersoek verskeie tegnieke en metodologieë vir die konstruksie van algoritmes wat hul werkverrigting outonoom kan verbeter deur groot hoeveelhede inligting te ontleed en te verwerk.
Deur die krag van data te benut, poog Computational Learning Theory om patrone, verhoudings en insigte te ontbloot wat masjiene in staat stel om hul besluitnemingsvermoëns te verbeter en take meer doeltreffend uit te voer.
Die uiteindelike doel is om algoritmes te skep wat kan aanpas, veralgemeen en akkurate voorspellings kan maak gebaseer op die data waaraan hulle blootgestel is, wat bydra tot die bevordering van kunsmatige intelligensie en die praktiese toepassings daarvan.
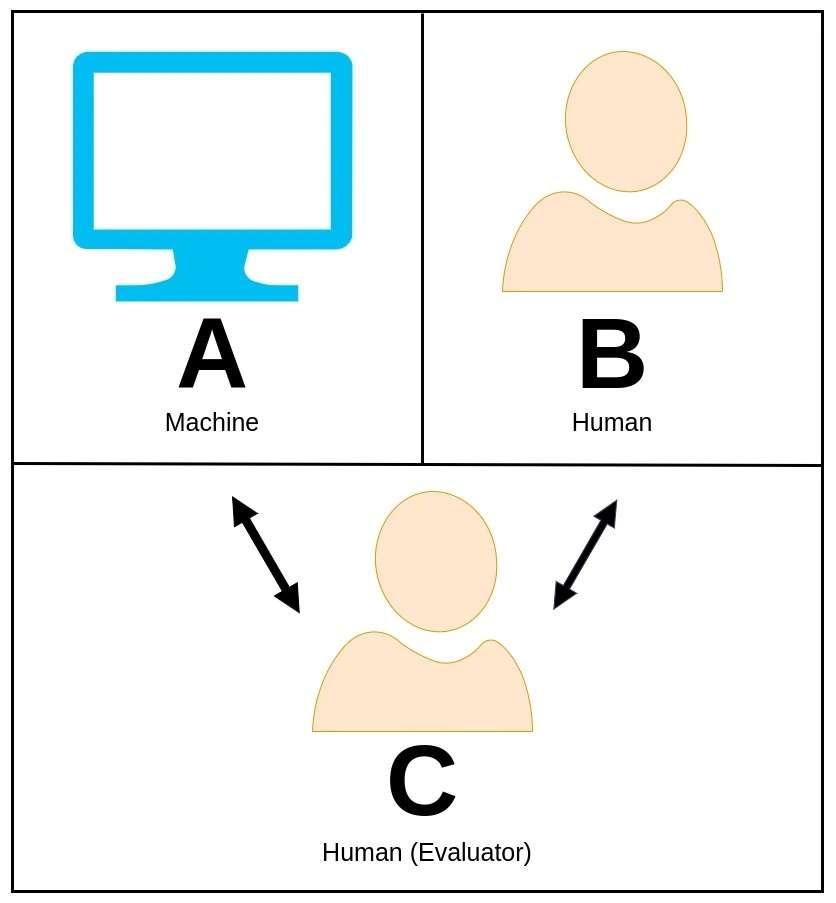
37. Turing-toets
Die Turing-toets, oorspronklik voorgestel deur die briljante wiskundige en rekenaarwetenskaplike Alan Turing, is 'n boeiende konsep wat gebruik word om te bepaal of 'n masjien intelligente gedrag kan toon wat vergelykbaar is met, of feitlik ononderskeibaar is met dié van 'n mens.
In die Turing-toets voer 'n menslike evalueerder 'n natuurlike taalgesprek met beide 'n masjien en 'n ander menslike deelnemer aan sonder om te weet watter een die masjien is.
Die evalueerder se rol is om uitsluitlik op grond van hul antwoorde te onderskei watter entiteit die masjien is. As die masjien in staat is om die evalueerder te oortuig dat dit die menslike eweknie is, word gesê dat dit die Turing-toets geslaag het, en sodoende 'n vlak van intelligensie demonstreer wat menslike vermoëns weerspieël.
Alan Turing het hierdie toets voorgestel as 'n manier om die konsep van masjienintelligensie te ondersoek en om die vraag te stel of masjiene kognisie op menslike vlak kan bereik.
Deur die toets in terme van menslike ononderskeibaarheid op te stel, het Turing die potensiaal beklemtoon vir masjiene om gedrag te toon wat so oortuigend intelligent is dat dit uitdagend word om hulle van mense te onderskei.
Die Turing-toets het uitgebreide besprekings en navorsing in die velde van kunsmatige intelligensie en kognitiewe wetenskap ontketen. Alhoewel die slaag van die Turing-toets 'n belangrike mylpaal bly, is dit nie die enigste maatstaf van intelligensie nie.
Nietemin dien die toets as 'n gedagteprikkelende maatstaf, wat voortdurende pogings stimuleer om masjiene te ontwikkel wat in staat is om menslike intelligensie en gedrag na te boots en by te dra tot die breër verkenning van wat dit beteken om intelligent te wees.
38. Versterkingsleer
Versterking leer is 'n tipe leer wat deur beproewing en fout plaasvind, waar 'n "agent" (wat 'n rekenaarprogram of 'n robot kan wees) leer om take uit te voer deur belonings vir goeie gedrag te ontvang en die gevolge of strawwe vir slegte gedrag in die gesig te staar.
Stel jou 'n scenario voor waar die agent 'n spesifieke taak probeer voltooi, soos om 'n doolhof te navigeer. Aanvanklik weet die agent nie die regte pad om te volg nie, daarom probeer hy verskillende aksies en verken verskeie roetes.
Wanneer dit 'n goeie aksie kies wat dit nader aan die doelwit bring, ontvang dit 'n beloning, soos 'n virtuele "klop op die skouer." As dit egter 'n swak besluit neem wat tot 'n doodloopstraat lei of dit wegneem van die doelwit, ontvang dit straf of negatiewe terugvoer.
Deur hierdie proses van beproewing en fout leer die agent om sekere aksies met positiewe of negatiewe uitkomste te assosieer. Dit vind geleidelik die beste volgorde van aksies uit om sy belonings te maksimeer en strawwe te verminder, en word uiteindelik meer vaardig in die taak.
Versterkingsleer put inspirasie uit hoe mense en diere leer deur terugvoer van die omgewing te ontvang.
Deur hierdie konsep op masjiene toe te pas, beoog navorsers om intelligente stelsels te ontwikkel wat kan leer en aanpas by verskillende situasies deur outonoom die mees effektiewe gedrag te ontdek deur 'n proses van positiewe versterking en negatiewe gevolge.
39. Entiteit Onttrekking
Entiteit-onttrekking verwys na 'n proses waarin ons belangrike stukke inligting, bekend as entiteite, uit 'n teksblok identifiseer en onttrek. Hierdie entiteite kan verskillende dinge wees soos die name van mense, name van plekke, name van organisasies, ensovoorts.
Kom ons stel ons voor dat jy 'n paragraaf het wat 'n nuusartikel beskryf.
Entiteit-onttrekking sal die ontleding van die teks behels en die uitsoek van spesifieke stukkies wat verskillende entiteite verteenwoordig. Byvoorbeeld, as die teks die naam van 'n persoon soos "John Smith", die ligging "New York City" of die organisasie "OpenAI" noem, sal dit die entiteite wees wat ons wil identifiseer en onttrek.
Deur entiteit-onttrekking uit te voer, leer ons in wese 'n rekenaarprogram om belangrike elemente uit die teks te herken en te isoleer. Hierdie proses stel ons in staat om inligting meer doeltreffend te organiseer en te kategoriseer, wat dit makliker maak om te soek, te ontleed en insigte uit groot volumes tekstuele data te verkry.
Algehele, entiteit-onttrekking help ons om die taak te outomatiseer om belangrike entiteite, soos mense, plekke en organisasies, binne die teks vas te stel, wat die onttrekking van waardevolle inligting vaartbelyn maak en ons vermoë om tekstuele data te verwerk en te verstaan, verbeter.
40. Taalkundige Annotasie
Linguistiese annotasie behels die verryking van teks met bykomende linguistiese inligting om ons begrip en ontleding van die taal wat gebruik word, te verbeter. Dit is soos om nuttige etikette of etikette by verskillende dele van 'n teks te voeg.
Wanneer ons linguistiese annotasies uitvoer, gaan ons verder as die basiese woorde en sinne in 'n teks en begin ons spesifieke elemente byskrifte of merk. Ons kan byvoorbeeld woordsoort-etikette byvoeg, wat die grammatikale kategorie van elke woord aandui (soos selfstandige naamwoord, werkwoord, byvoeglike naamwoord, ens.). Dit help ons om die rol wat elke woord in 'n sin speel, te verstaan.
'n Ander vorm van linguistiese annotasie word entiteitsherkenning genoem, waar ons spesifieke benoemde entiteite identifiseer en etiketteer, soos name van mense, plekke, organisasies of datums. Dit stel ons in staat om vinnig belangrike inligting uit die teks op te spoor en te onttrek.
Deur teks op hierdie maniere te annoteer, skep ons 'n meer gestruktureerde en georganiseerde voorstelling van die taal. Dit kan uiters nuttig wees in 'n verskeidenheid toepassings. Dit help byvoorbeeld om die akkuraatheid van soekenjins te verbeter deur die bedoeling agter gebruikersnavrae te verstaan. Dit help ook met masjienvertaling, sentimentanalise, inligtingonttrekking en baie ander natuurlike taalverwerkingstake.
Taalkundige annotasie dien as 'n noodsaaklike hulpmiddel vir navorsers, taalkundiges en ontwikkelaars, wat hulle in staat stel om taalpatrone te bestudeer, taalmodelle te bou en gesofistikeerde algoritmes te ontwikkel wat die teks beter kan analiseer en verstaan.
41. Hiperparameter
In machine learning, 'n hiperparameter is soos 'n spesiale instelling of konfigurasie waaroor ons moet besluit voordat ons 'n model oplei. Dit is nie iets wat die model op sy eie uit die data kan leer nie; in plaas daarvan moet ons dit vooraf bepaal.
Dink daaraan as 'n knop of skakelaar wat ons kan verstel om te verfyn hoe die model leer en voorspellings maak. Hierdie hiperparameters beheer verskeie aspekte van die leerproses, soos die model se kompleksiteit, die spoed van opleiding en die afweging tussen akkuraatheid en veralgemening.
Kom ons kyk byvoorbeeld na 'n neurale netwerk. Een belangrike hiperparameter is die aantal lae in die netwerk. Ons moet kies hoe diep ons wil hê die netwerk moet wees, en hierdie besluit beïnvloed sy vermoë om komplekse patrone in die data vas te vang.
Ander algemene hiperparameters sluit in die leertempo, wat bepaal hoe vinnig die model sy interne parameters aanpas op grond van die opleidingsdata, en die regulariseringssterkte, wat beheer hoeveel die model komplekse patrone penaliseer om oorpassing te voorkom.
Om hierdie hiperparameters korrek in te stel is van kardinale belang, want dit kan 'n aansienlike impak hê op die prestasie en gedrag van die model. Dit behels dikwels 'n bietjie proef en fout, eksperimentering met verskillende waardes en waarneming hoe dit die model se werkverrigting op 'n valideringsdatastel beïnvloed.
42. Metadata
Metadata verwys na bykomende inligting wat besonderhede oor ander data verskaf. Dit is soos 'n stel etikette of etikette wat ons meer konteks gee of die kenmerke van die hoofdata beskryf.
Wanneer ons data het, of dit nou 'n dokument, 'n foto, 'n video of enige ander tipe inligting is, help metadata ons om belangrike aspekte van daardie data te verstaan.
Byvoorbeeld, in 'n dokument kan metadata besonderhede soos die skrywer se naam, die datum waarop dit geskep is, of die lêerformaat insluit. In die geval van 'n foto, kan metadata vir ons die ligging vertel waar dit geneem is, die kamera-instellings wat gebruik is, of selfs die datum en tyd wat dit vasgelê is.
Metadata help ons om data meer effektief te organiseer, te soek en te interpreteer. Deur hierdie beskrywende stukke inligting by te voeg, kan ons vinnig spesifieke lêers vind of hul oorsprong, doel of konteks verstaan sonder om deur die hele inhoud te hoef te delf.
43. Dimensionaliteitvermindering
Dimensionaliteitsvermindering is 'n tegniek wat gebruik word om 'n datastel te vereenvoudig deur die aantal kenmerke of veranderlikes wat dit bevat te verminder. Dit is soos om die inligting in 'n datastel te kondenseer of op te som om dit meer hanteerbaar en makliker te maak om mee te werk.
Stel jou voor jy het 'n datastel met talle kolomme of eienskappe wat verskillende kenmerke van die datapunte verteenwoordig. Elke kolom dra by tot die kompleksiteit en berekeningsvereistes van masjienleeralgoritmes.
In sommige gevalle kan 'n groot aantal dimensies dit uitdagend maak om betekenisvolle patrone of verwantskappe in die data te vind.
Dimensionaliteitsvermindering help om hierdie probleem aan te spreek deur die datastel in 'n laer-dimensionele voorstelling te transformeer terwyl soveel relevante inligting as moontlik behou word. Dit het ten doel om die belangrikste aspekte of variasies in die data vas te lê terwyl oortollige of minder insiggewende dimensies weggegooi word.
44. Teksklassifikasie
Teksklassifikasie is 'n proses wat behels dat spesifieke etikette of kategorieë aan blokke teks toegeken word op grond van hul inhoud of betekenis. Dit is soos om tekstuele inligting in verskillende groepe of klasse te sorteer of te organiseer om verdere ontleding of besluitneming te vergemaklik.
Kom ons kyk na 'n voorbeeld van e-posklassifikasie. In hierdie scenario wil ons bepaal of 'n inkomende e-pos strooipos of nie-strooipos is (ook bekend as ham). Teksklassifikasie Algoritmes ontleed die inhoud van die e-pos en gee dit dienooreenkomstig 'n etiket.
As die algoritme bepaal dat die e-pos eienskappe vertoon wat gewoonlik met strooipos geassosieer word, ken dit die etiket "spam" toe. Omgekeerd, as die e-pos wettig en nie-strooipos lyk nie, ken dit die etiket "nie-spam" of "ham" toe.
Teksklassifikasie vind toepassings in verskeie domeine buite e-posfiltrering. Dit word in sentimentanalise gebruik om die sentiment te bepaal wat in klantresensies (positief, negatief of neutraal) uitgedruk word.
Nuusartikels kan in verskillende onderwerpe of kategorieë geklassifiseer word soos sport, politiek, vermaak en meer. Kliëntediens-kletslogboeke kan gekategoriseer word op grond van die bedoeling of kwessie wat aangespreek word.
45. Swak KI
Swak KI, ook bekend as smal KI, verwys na kunsmatige intelligensiestelsels wat ontwerp en geprogrammeer is om spesifieke take of funksies uit te voer. Anders as menslike intelligensie, wat 'n wye reeks kognitiewe vermoëns insluit, is swak KI beperk tot 'n spesifieke domein of taak.
Dink aan swak KI as gespesialiseerde sagteware of masjiene wat uitblink in die uitvoering van spesifieke take. Byvoorbeeld, 'n skaakspelende KI-program kan geskep word om spelsituasies te ontleed, skuiwe te strategiseer en teen menslike spelers mee te ding.
Nog 'n voorbeeld is 'n beeldherkenningstelsel wat voorwerpe in foto's of video's kan identifiseer.
Hierdie KI-stelsels is opgelei en geoptimaliseer om uit te blink in hul spesifieke gebiede van kundigheid. Hulle maak staat op algoritmes, data en vooraf gedefinieerde reëls om hul take effektief uit te voer.
Hulle beskik egter nie oor 'n algemene intelligensie wat hulle toelaat om take buite hul aangewese domein te verstaan of uit te voer nie.
46. Sterk KI
Sterk KI, ook bekend as algemene KI of kunsmatige algemene intelligensie (AGI), verwys na 'n vorm van kunsmatige intelligensie wat oor die vermoë beskik om enige intellektuele taak te verstaan, te leer en uit te voer wat 'n mens kan.
Anders as swak KI, wat ontwerp is vir spesifieke take, poog sterk KI om menslike intelligensie en kognitiewe vermoëns te herhaal. Dit streef daarna om masjiene of sagteware te skep wat nie net uitblink in gespesialiseerde take nie, maar ook 'n breër begrip en aanpasbaarheid het om 'n wye reeks intellektuele uitdagings aan te pak.
Die doel van sterk KI is om stelsels te ontwikkel wat kan redeneer, komplekse inligting kan begryp, uit ervaring kan leer, in natuurlike taalgesprekke kan deelneem, kreatiwiteit aan die dag lê en ander eienskappe wat met menslike intelligensie geassosieer word, vertoon.
In wese streef dit daarna om KI-stelsels te skep wat mensvlakdenke en probleemoplossing oor verskeie domeine kan simuleer of herhaal.
47. Voorwaartse ketting
Voorwaartse ketting is 'n metode van redenasie of logika wat by die beskikbare data begin en dit gebruik om afleidings te maak en nuwe gevolgtrekkings te maak. Dit is soos om die kolletjies te verbind deur die inligting byderhand te gebruik om vorentoe te beweeg en bykomende insigte te bereik.
Stel jou voor jy het 'n stel reëls of feite, en jy wil nuwe inligting aflei of spesifieke gevolgtrekkings op grond daarvan maak. Voorwaartse ketting werk deur die aanvanklike data te ondersoek en logiese reëls toe te pas om bykomende feite of gevolgtrekkings te genereer.
Om dit te vereenvoudig, kom ons kyk na 'n eenvoudige scenario om te bepaal wat om te dra, gebaseer op weerstoestande. Jy het 'n reël wat sê: "As dit reën, bring 'n sambreel," en 'n ander reël wat sê: "As dit koud is, dra 'n baadjie." Nou, as jy sien dat dit wel reën, kan jy vorentoe ketting gebruik om af te lei dat jy 'n sambreel moet saambring.
48. Terugketting
Terugketting is 'n redenasiemetode wat met 'n gewenste gevolgtrekking of doelwit begin en agteruit werk om die nodige data of feite te bepaal wat nodig is om daardie gevolgtrekking te ondersteun. Dit is soos om jou stappe op te spoor van die gewenste uitkoms tot die aanvanklike inligting wat nodig is om dit te bereik.
Om agterwaartse ketting te verstaan, kom ons kyk na 'n eenvoudige voorbeeld. Gestel jy wil vasstel of dit geskik is om te gaan swem. Die gewenste gevolgtrekking is of swem gepas is op grond van sekere toestande.
In plaas daarvan om met die voorwaardes te begin, begin agterwaartse ketting met die gevolgtrekking en werk agteruit om die ondersteunende data te vind.
In hierdie geval sal agteruit ketting behels die vra van vrae soos "Is die weer warm?" As die antwoord ja is, sal jy dan vra: "Is daar 'n swembad beskikbaar?" As die antwoord weer ja is, sal jy verdere vrae vra soos: "Is daar genoeg tyd om te gaan swem?"
Deur hierdie vrae iteratief te beantwoord en agteruit te werk, kan jy die nodige voorwaardes bepaal waaraan voldoen moet word om die besluit om te gaan swem te ondersteun.
49. Heuristiek
'n Heuristiek, in eenvoudige terme, is 'n praktiese reël of strategie wat ons help om besluite te neem of probleme op te los, gewoonlik gebaseer op ons vorige ervarings of intuïsie. Dit is soos 'n verstandelike kortpad wat ons in staat stel om vinnig met 'n redelike oplossing vorendag te kom sonder om deur 'n lang of uitputtende proses te gaan.
Wanneer dit met komplekse situasies of take gekonfronteer word, dien heuristiek as rigtinggewende beginsels of "duimreëls" wat besluitneming vereenvoudig. Hulle voorsien ons van algemene riglyne of strategieë wat dikwels in sekere situasies effektief is, al waarborg dit dalk nie die optimale oplossing nie.
Kom ons kyk byvoorbeeld na 'n heuristiek om 'n parkeerplek in 'n oorvol gebied te vind. In plaas daarvan om elke beskikbare plek noukeurig te ontleed, kan jy staatmaak op die heuristiek om geparkeerde motors te soek met hul enjins aan die gang.
Hierdie heuristiek neem aan dat hierdie motors op die punt is om te vertrek, wat die kanse verhoog om 'n beskikbare plek te vind.
50. Natuurlike taalmodellering
Natuurlike taalmodellering, in eenvoudige terme, is die proses om rekenaarmodelle op te lei om menslike taal te verstaan en te genereer op 'n manier wat soortgelyk is aan hoe mense kommunikeer. Dit behels die leer van rekenaars om teks op 'n natuurlike en betekenisvolle wyse te verwerk, te interpreteer en te genereer.
Die doel van natuurlike taalmodellering is om rekenaars in staat te stel om menslike taal te verstaan en te genereer op 'n wyse wat vlot, samehangend en kontekstueel relevant is.
Dit behels opleidingsmodelle op groot hoeveelhede tekstuele data, soos boeke, artikels of gesprekke, om die patrone, strukture en semantiek van taal aan te leer.
Sodra hulle opgelei is, kan hierdie modelle verskeie taalverwante take verrig, soos taalvertaling, teksopsomming, vraagbeantwoording, kletsbotinteraksies, en meer.
Hulle kan die betekenis en konteks van sinne verstaan, relevante inligting onttrek en teks genereer wat grammatikaal korrek en samehangend is.





Lewer Kommentaar